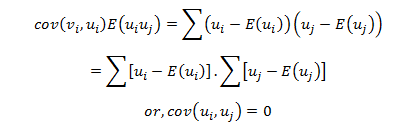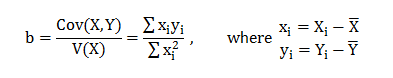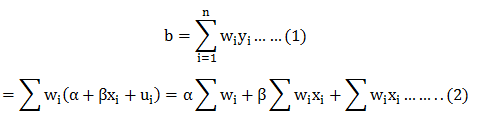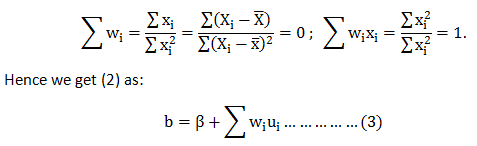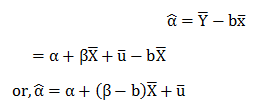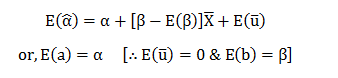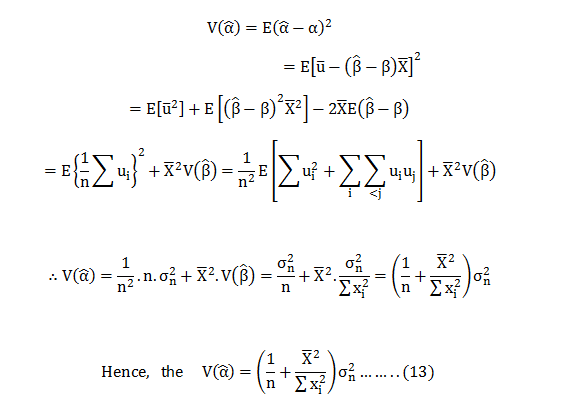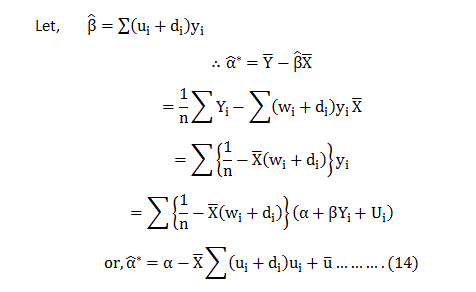Excited to face your first data science interview? Probably, you must have double-checked your practical skills and theoretical knowledge. Technical interviews are tough yet interesting. Cracking them and bagging your dream job is no mean feat.
Thus, to lend you a helping hand, we’ve compiled a nifty list of some common red flags that plague data science interviews. Go through them and decide how to handle them well!
Boring Portfolio
Having a monotonous portfolio is not a crime. Nevertheless, it’s the most common allegation against data scientists by the recruiters. Given the scope, you should always exhibit your organizational and communication abilities in an interesting way to the hiring company. A well-crafted portfolio will give you instant recognition, so why not try it!

Sloppy Code
Of course, your analytical skills, including coding is going to be put to test during any data science interview. A quick algorithm coding test will bring out the technical value you would add to the company. In such circumstances, writing a clumsy code or a code with too many bugs would be the last thing you want to do. Improving the quality of coding will accelerate your hiring process for sure.
Confusion about Job Role
No wonder if you walk up to your interviewer having no idea about your job responsibilities, your expertise and competence will be questionable. The domain of data science includes a lot of closely related job profiles. But, they differ widely in terms of skills and duties. This is why it’s very important to know your field of expertise and the skills your hiring company is looking for.
Zero Hands-on Experience
A decent, if not rich, hands-on experience in Machine Learning or Data Science projects is a requisite. Organizations prefer candidates who have some experience. The latter may include data cleaning projects, data-storytelling projects or even end-to-end data projects. So, keep this in mind. It will help you score well in the upcoming data science interview.
Lack of Knowledge over Data Science Technicalities
Data analytics, data science, machine learning and AI – are all closely associated with one another. To excel in each of these fields you need to possess high technical expertise. Being technically sound is the key. An interview can go wrong if the recruiter feels you lack command over data science technicalities, even though you have presented an excellent portfolio of projects.
Therefore, you have to be excellent in coding and harbor a vast pool of technical knowledge. Also, be updated with the latest industry trends and robust set of algorithms.
Ignoring the Basics
It happens. At times, we fumble while answering some very fundamental questions regarding our particular domain of work. However, once we come out of the interview venue, we tend to know everything. Reason: lack of presence of mind. Therefore, the key is to be confident. Don’t lose your presence of mind in the stifling interview room.
Thus, beware of these drooping gaps; being a victim of these critical objections might keep you away from bagging that dream data analyst job. Instead, work on them and win a certain edge over others while cracking the toughest data science interview session.

Note:
If interested in Data Science Courses in Gurgaon, check out DexLab Analytics. We are a premier training platform specialized in in-demand skills, including machine learning using Python, Alteryx and customer analytics. All our courses are industry-relevant and crafted by experts.
The blog has been sourced from — upxacademy.com/eleven-most-common-objections-in-data-science-interviews-and-how-to-handle-them
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.