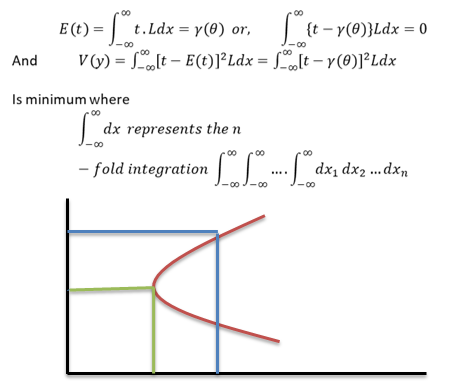
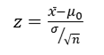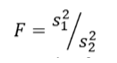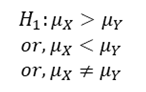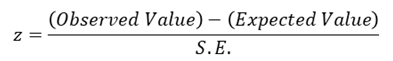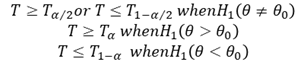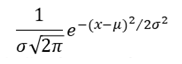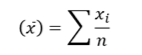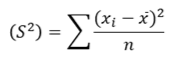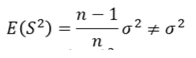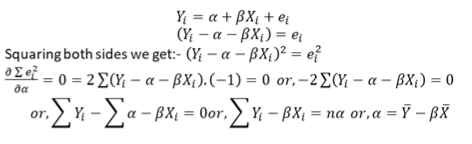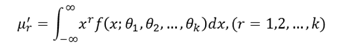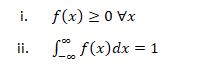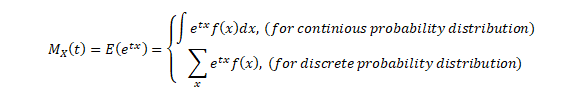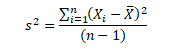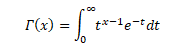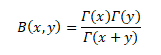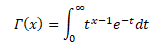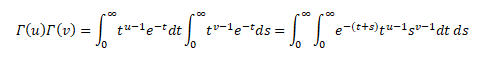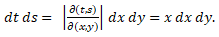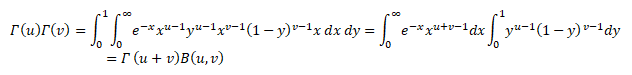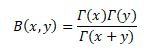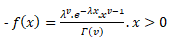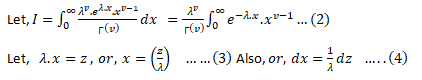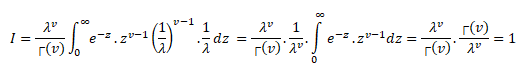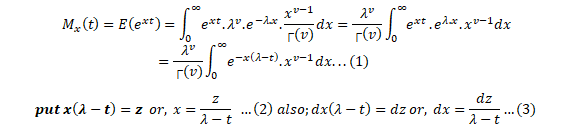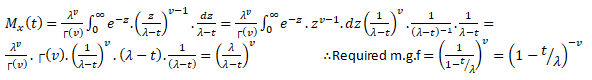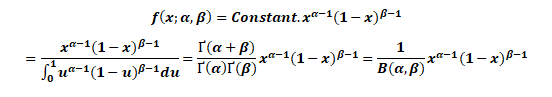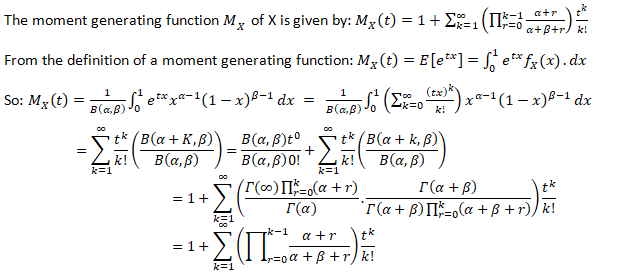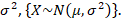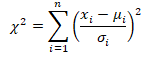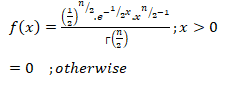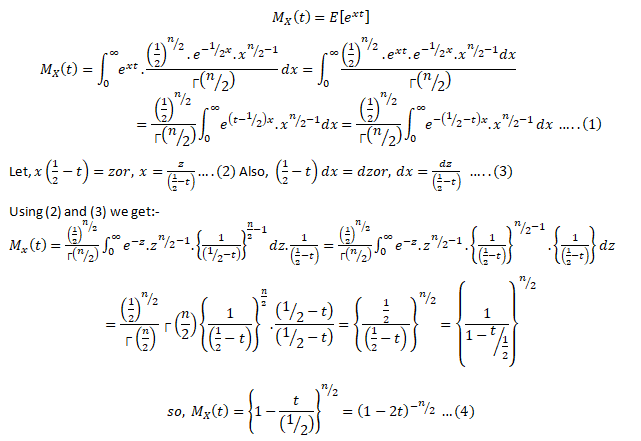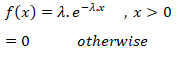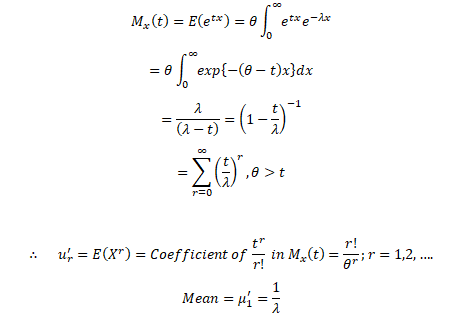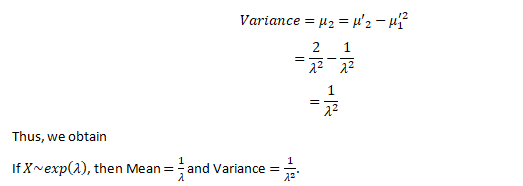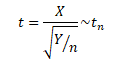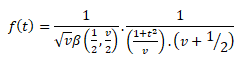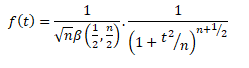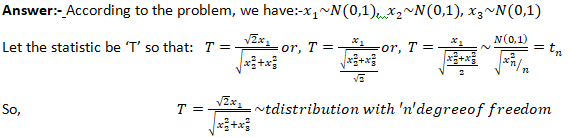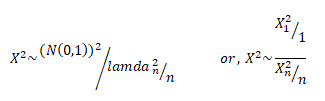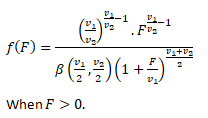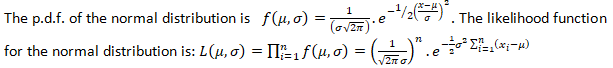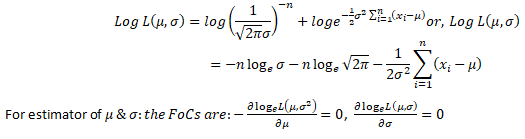A time series is a sequence of numerical data in which each item is associated with a particular instant in time. Many sets of data appear as time series: a monthly sequence of the quantity of goods shipped from a factory, a weekly series of the number of road accidents, daily rainfall amounts, hourly observations made on the yield of a chemical process, and so on. Examples of time series abound in such fields as economics, business, engineering, the natural sciences (especially geophysics and meteorology), and the social sciences.
Univariate time series analysis- When we have a single sequence of data observed over time then it is called univariate time series analysis.
Multivariate time series analysis – When we have several sets of data for the same sequence of time periods to observe then it is called multivariate time series analysis.
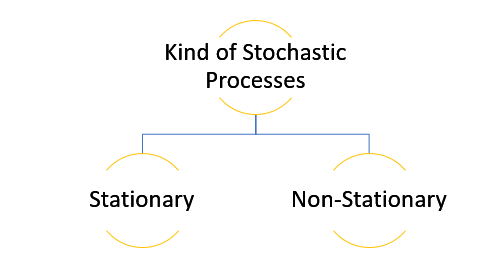
The data used in time series analysis is a random variable (Yt) where t is denoted as time and such a collection of random variables ordered in time is called random or stochastic process.
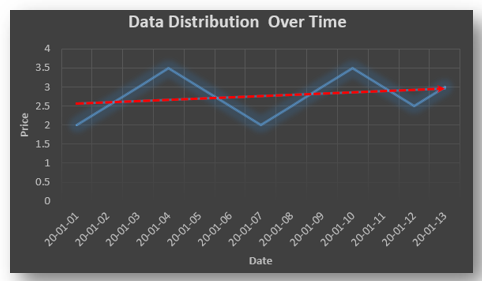
Stationary: A time series is said to be stationary when all the moments of its probability distribution i.e. mean, variance , covariance etc. are invariant over time. It becomes quite easy forecast data in this kind of situation as the hidden patterns are recognizable which make predictions easy.
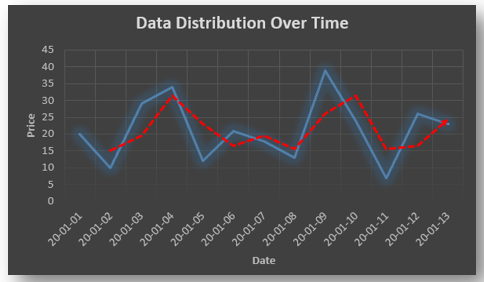
Non-stationary: A non-stationary time series will have a time varying mean or time varying variance or both, which makes it impossible to generalize the time series over other time periods.
Non stationary processes can further be explained with the help of a term called Random walk models. This term or theory usually is used in stock market which assumes that stock prices are independent of each other over time. Now there are two types of random walks: Random walk with drift : When the observation that is to be predicted at a time ‘t’ is equal to last period’s value plus a constant or a drift (α) and the residual term (ε). It can be written as Yt= α + Yt-1 + εt The equation shows that Yt drifts upwards or downwards depending upon α being positive or negative and the mean and the variance also increases over time. Random walk without drift: The random walk without a drift model observes that the values to be predicted at time ‘t’ is equal to last past period’s value plus a random shock. Yt= Yt-1 + εt Consider that the effect in one unit shock then the process started at some time 0 with a value of Y0 When t=1 Y1= Y0 + ε1 When t=2 Y2= Y1+ ε2= Y0 + ε1+ ε2 In general, Yt= Y0+∑ εt In this case as t increases the variance increases indefinitely whereas the mean value of Y is equal to its initial or starting value. Therefore the random walk model without drift is a non-stationary process.
So, with that we come to the end of the discussion on the Time Series. Hopefully it helped you understand time Series, for more information you can also watch the video tutorial attached down this blog. DexLab Analytics offers machine learning courses in delhi. To keep on learning more, follow DexLab Analytics blog.
Businesses today can no longer afford to run based on assumptions, they need actionable intel which can help them formulate sharper business strategies. Big data holds the key to all the information they need and the application of business analytics strategies can help businesses realize their goals. Business analytics is about collecting data and processing it to glean valuable business information. Business analytics puts statistical models to use to access business insight. It is a crucial branch of business intelligence that applies cutting edge tools to dissect available data and detect the patterns to predict market trends and doing business analysis training in delhi can help a professional in this field in a big way.
Different types of business analytics:
Business analytics could be broken down into four different segments all of which perform different tasks yet all of these are interrelated. The types are namely Descriptive Analytics, Diagnostic Analytics, Predictive Analytics, and Prescriptive Analytics. The role of each is to offer a thorough understanding of the data to predict future solutions. Find out how these different types of analytics work.
Descriptive Analytics: Descriptive analytics is the simplest form of analytics and the term itself is self-explanatory enough. Descriptive analytics is all about presenting a summary of the data a particular business organization has to create a clear picture of the past trends and also capturing the present situation. It helps an organization to understand what are the areas that need attention and what are their strengths. Analyzing historical data the existence of certain trends could be identified and most importantly could also offer some valuable insight towards developing some plan. Usually, the size of the data both structured and unstructured are beyond our comprehension unless it is presented in some coherent format, something that could be easily ingested. Descriptive analytics performs that function with the help of data aggregation and data mining techniques. For improving communication descriptive analytics helps in summarizing data that needs to be accessible to employees as well as to investors.
Diagnostic Analytics: Diagnostic analytics plays the role of detecting issues a company might be facing. When the entire data set is presented comprehensively, it is time for diagnosis of the patterns detected and detecting issues that might be causing harm. Now, this business analytics dives down deeper into the problem and offers an in-depth analysis to bring out the root cause of the problem. The diagnostic analytics concerns itself with the problem finding aspect by reading data and extracting information to find out why something is not working or, working in a way that is giving considerable trouble. Usually, principle components analysis, conjoint analysis, drill-down, are some of the techniques employed in this specific branch of analytics. Diagnostic analytics takes a critical look at issues and allows the management to identify the reasons so that they can work on that.
Predictive Analytics: Predictive analytics is sophisticated analytics that is concerned about taking the results of descriptive analytics and working on that to forecast probabilities. It does not predict an outcome but, it suggests probabilities by combining statistics and machine learning. It takes a look at the past data mainly the history of the organization, past performances, and also takes into account the current state and on the basis of that analysis it suggests future trends. However, predictive analytics does not work like magic, it does its job based on the data provided and so, data quality matters here. High quality, complete data ensures accurate prediction, because the data is analyzed to find patterns and further prediction takes off from there. This type of analytics plays a key role in strategizing, based on the forecasts the company can change the sales and marketing strategy and set a new goal.
Prescriptive Analytics: With prescriptive analytics, an organization can find a direction as it is about suggesting solutions for the future. So, it suggests the possible trends or, outcomes, and based on that this analytics can also suggest actions that could be taken to achieve desired results. It employs simulation and optimization modeling to predict which should be the ideal course of action to reach a certain goal. This form of analytics offers recommendations in real-time, it could be thought of as the next step of predictive analytics. Here not just the data previously stored is put to use, but, real-time data is also utilized, in fact, this type of analytics also takes into account data coming from external sources to offer better results.
Those were the four types of business analytics that are employed by data analysts to offer sharp business insight to an organization. However, there needs to be skilled people who have done Business analyst training courses in Gurgaon to be able to carry out business analytics procedure to drive organizations towards a brighter future.
In this fifth part of the basic of statistical inference series you will learn about different types of Parametric tests. Parametric statistical test basically is concerned with making assumption regarding the population parameters and the distributions the data comes from. In this particular segment the discussion would focus on explaining different kinds of parametric tests. You can find the 4th part of the series here.
INTRODUCTION
Parametric statistics are the most common type of inferential statistics. Inferential statistics are calculated with the purpose of generalizing the findings of a sample to the population it represents, and they can be classified as either parametric or non-parametric. Parametric tests make assumptions about the parameters of a population, whereas nonparametric tests do not include such assumptions or include fewer. For instance, parametric tests assume that the sample has been randomly selected from the population it represents and that the distribution of data in the population has a known underlying distribution. The most common distribution assumption is that the distribution is normal. Other distributions include the binomial distribution (logistic regression) and the Poisson distribution (Poisson regression).
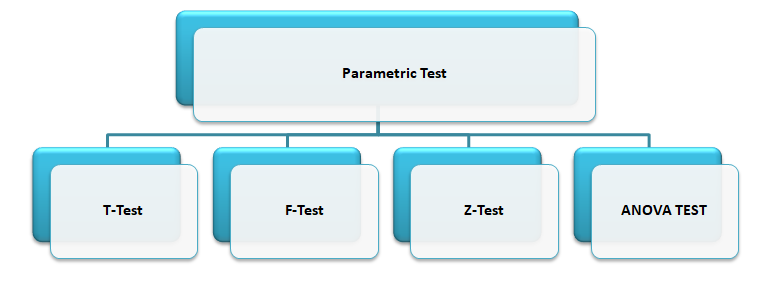
PARAMETRIC TEST
A parameter in statistics refers to an aspect of a population, as opposed to a statistic, which refers to an aspect, about a sample. For example, the population mean is a parameter, while the sample mean is a statistic. A parametric statistical test makes an assumption about the population parameters and the distributions that the data comes from. These types of tests assume to data is from normal distribution.
Data that is assumed to have been drawn from a particular distribution, and that is used in a parametric test.
Parametric equations are used in calculus to deal with the problems that arise when trying to find functions that describe curves. These equations are beyond the scope of this site, but you can find an excellent rundown of how to use these types of equations here.
The parametric tests are: Let’s discuss about each test in details.
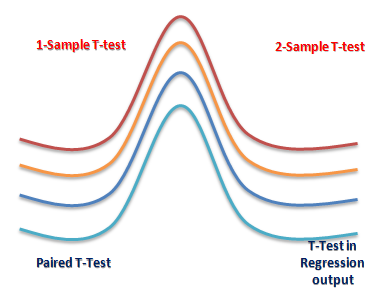
T-TEST
The T-test is one of, inferential statistics. It is used to determine whether there is a significant difference between the means of two groups or not. When the difference between two population averages is being investigated, a t-test is used. In other words, a t-test is used when we wish to compare two means. Essentially, a t-test allows us to compare the average values of the two data sets and determine if they came from the same population. In the above examples, if we were to take a sample of students from class A and another sample of students from class B, we would not expect them to have exactly the same mean and standard deviation.
Mathematically, the t-test takes a sample from each of the two sets and establishes the problem statement by assuming a null hypothesis that the two means are equal. Based on the applicable formulas, certain values are calculated and compared against the standard values, and the assumed null hypothesis is accepted or rejected accordingly.
If the null hypothesis qualifies to be rejected, it indicates that data readings are strong and are probably not due to chance. The t-test is just one of many tests used for this purpose. Statisticians must additionally use tests other than the t-test to examine more variables and tests with larger sample sizes. For a large sample size, statisticians use a z-test. Other testing options include the chi-square test and the f-test.
T-Test Assumptions
The first assumption made regarding t-tests concerns the scale of measurement. The assumption for a t-test is that the scale of measurement applied to the data collected follows a continuous or ordinal scale, such as the scores for an IQ test.
The second assumption made is that of a simple random sample, that the data is collected from a representative, randomly selected portion of the total population.
The third assumption is the data, when plotted, results in a normal distribution, bell-shaped distribution curve.
The final assumption is the homogeneity of variance. Homogeneous, or equal, variance exists when the standard deviations of samples are approximately equal.
There are three types to T-test: (i) Correlated or paired T-test, (ii) Equal variance(or pooled) T-test (iii) Unequal variance T-test.
Z-TEST
A z-test is a statistical test used to determine whether two population means are different when the variances are known and the sample size is large. The test statistic is assumed to have a normal distribution, and nuisance parameters such as standard deviation should be known in order for an accurate z-test to be performed. A z-statistic, or z-score, is a number representing how many standard deviations above or below the mean population a score derived from a z-test is.
The z-test is also a hypothesis test in which the z-statistic follows a normal distribution. The z-test is best used for greater-than-30 samples because, under the central limit theorem, as the number of samples gets larger, the samples are considered to be approximately normally distributed. When conducting a z-test, the null and alternative hypotheses, alpha and z-score should be stated. Next, the test statistic should be calculated, and the results and conclusion stated. Examples of tests that can be conducted as z-tests include a one-sample location test, a two-sample location test, a paired difference test, and a maximum likelihood estimate. Z-tests are closely related to t-tests, but t-tests are best performed when an experiment has a small sample size. Also, t-tests assume the standard deviation is unknown, while z-tests assume it is known. If the standard deviation of the population is unknown, the assumption of the sample variance equaling the population variance is made.
One Sample Z-test: A one sample z test is one of the most basic types of hypothesis test. In order to run a one sample z test, its work through several steps:
Step 1: Null hypothesis is one of the common stumbling blocks–in order to make sense of your sample and have the one sample z test give you the right information it must make sure written the null hypothesis and alternate hypothesis correctly. For example, you might be asked to test the hypothesis that the mean weight gain of an women was more than 30 pounds. Your null hypothesis would be: H0 : μ = 30 and your alternate hypothesis would be H, sub>1: μ > 30.
Step 2: Use the z-formula to find a z-score
All you do is put in the values you are given into the formula. Your question should give you the sample mean (x̄), the standard deviation (σ), and the number of items in the sample (n). Your hypothesized mean (in other words, the mean you are testing the hypothesis for, or your null hypothesis) is μ0 .
Two Sample Z Test: The z-Test: Two- Sample for Means tool runs a two sample z-Test means with known variances to test the null hypothesis that there is no difference between the means of two independent populations. This tool can be used to run a one-sided or two-sided test z-test.
ANOVA
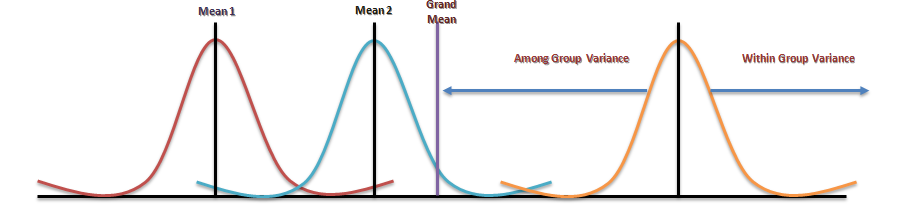
Analysis of variance (ANOVA) is an analysis tool used in statistics that splits an observed aggregate variability found inside a data set into two parts: systematic factors and random factors. The systematic factors have a statistical influence on the given data set, while the random factors do not. Analysts use the ANOVA test to determine the influence that independent variables have on the dependent variable in a regression study. The ANOVA test is the initial step in analysing factors that affect a given data set. Once the test is finished, an analyst performs additional testing on the methodical factors that measurably contribute to the data set’s inconsistency. The analyst utilizes the ANOVA test results in an f-test to generate additional data that aligns with the proposed regression models. The ANOVA test allows a comparison of more than two groups at the same time to determine whether a relationship exists between them. The result of the ANOVA formula, the F statistic (also called the F-ratio), allows for the analysis of multiple groups of data to determine the variability between samples and within samples.
If no real difference exists between the tested groups, which is called the null hypothesis, the result of the ANOVA’s F-ratio statistic will be close to 1. Fluctuations in its sampling will likely follow the Fisher F distribution. This is actually a group of distribution functions, with two characteristic numbers, called the numerator degrees of freedom and the denominator degrees of freedom.
One-way Anova: A one-way ANOVA uses one independent variable, use a one-way ANOVA when collected data about one categorical independent variable and one quantitative dependent variable. The independent variable should have at least three levels (i.e. at least three different groups or categories). ANOVA that if the dependent variable changes according to the level of the independent variable.
Two-way Anova: A two-way ANOVA is used to estimate how the mean of a quantitative variable changes according to the levels of two categorical variables. Use a two-way ANOVA when you want to know how two independent variables, in combination, affect a dependent variable.
F-TEST
An “F Test” is a catch-all term for any test that uses the F-distribution. In most cases, when people talk about the F-Test, what they are actually talking about is The F-Test to compare two variances. However, the f-statistic is used in a variety of tests including regression analysis, the Chow test and the Scheffe Test (a post-hoc ANOVA test).
F Test to Compare Two Variances
A Statistical F Test uses an F Statistic to compare two variances, s1 and s2 , by dividing them. The result is always a positive number (because variances are always positive). The equation for comparing two variances with the f-test is:
If the variances are equal, the ratio of the variances will equal 1. For example, if you had two data sets with a sample 1 (variance of 10) and a sample 2 (variance of 10), the ratio would be 10/10 = 1.
You always test that the population variances are equal when running an F Test. In other words, you always assume that the variances are equal to 1. Therefore, your null hypothesis will always be that the variances are equal. Assumptions
Several assumptions are made for the test. Your population must be approximately normally distributed (i.e. fit the shape of a bell curve) in order to use the test. Plus, the samples must be independent events. In addition, you’ll want to bear in mind a few important points:
The larger variance should always go in the numerator (the top number) to force the test into a right-tailed test. Right-tailed tests are easier to calculate.
For two-tailed tests, divide alpha by 2 before finding the right critical value.
If you are given standard deviations, they must be squared to get the variances.
If your degrees of freedom aren’t listed in the F Table, use the larger critical value. This helps to avoid the possibility of Type I errors.
CONCLUSION
Conventional statistical procedures may also call parametric tests. In every parametric test, for example, you have to use statistics to estimate the parameter of the population. Because of such estimation, you have to follow a process that includes a sample as well as a sampling distribution and a population along with certain parametric assumptions that required, which makes sure that all components compatible with one another.
An example can use to explain this. Observations are first of all quite independent, the sample data doesn’t have any normal distributions and the scores in the different groups have some homogeneous variances. Parametric tests are based on the distribution, parametric statistical tests are only applicable to the variables. There’re no parametric tests that exist for the nominal scale date, and finally, they are quite powerful when they exist. There are mainly four types of Parametric Hypothesis Test which already mentioned in previous slides.
Advantages of Parametric Test
One of the biggest and best advantages of using parametric tests is first of all that you don’t need much data that could be converted in some order or format of ranks. The process of conversion is something that appears in rank format and to be able to use a parametric test regularly, you will end up with a severe loss in precision. Another big advantage of using parametric tests is the fact that you can calculate everything so easily. In short, you will be able to find software much quicker so that you can calculate them fast and quick. Apart from parametric tests, there are other non-parametric tests, where the distributors are quite different and they are not all that easy when it comes to testing such questions that focus related to the means and shapes of such distributions.
Disadvantages of Parametric Test
Parametric tests are not valid when it comes to small data sets. The requirement that the populations are not still valid on the small sets of data, the requirement that the populations which are under study have the same kind of variance and the need for such variables are being tested and have been measured at the same scale of intervals. Another disadvantage of parametric tests is that the size of the sample is always very big, something you will not find among non-parametric tests. That makes it a little difficult to carry out the whole test.
This particular discussion on parametric tests ends here, and at the end of this you must have developed clear ideas regarding these test categories. To find more such posts on Data Science training topics follow the Dexlab Analytics blog.
In this series we cover the basic of statistical inference, this is the fourth part of our discussion where we explain the concept of hypothesis testing which is a statistical technique. You could also check out the 3rd part of the series here.
Introduction
The objective of sampling is to study the features of the population on the basis of sample observations. A carefully selected sample is expected to reveal these features, and hence we shall infer about the population from a statistical analysis of the sample. This process is known as Statistical Inference.
There are two types of problems. Firstly, we may have no information at all about some characteristics of the population, especially the values of the parameters involved in the distribution, and it is required to obtain estimates of these parameters. This is the problem of Estimation. Secondly, some information or hypothetical values of the parameters may be available, and it is required to test how far the hypothesis is tenable in the light of the information provided by the sample. This is the problem of Test of Hypothesis or Test of Significance.
In many practical problems, statisticians are called upon to make decisions about a population on the basis of sample observations. For example, given a random sample, it may be required to decide whether the population, from which the sample has been obtained, is a normal distribution with mean = 40 and s.d. = 3 or not. In attempting to reach such decisions, it is necessary to make certain assumptions or guesses about the characteristics of population, particularly about the probability distribution or the values of its parameters. Such an assumption or statement about the population is called Statistical Hypothesis. The validity of a hypothesis will be tested by analyzing the sample. The procedure which enables us to decide whether a certain hypothesis is true or not, is called Test of Significance or Test of Hypothesis.
What Is Testing Of Hypothesis?
Statistical Hypothesis
Hypothesis is a statistical statement or a conjecture about the value of a parameter. The basic hypothesis being tested is called the null hypothesis. It is sometimes regarded as representing the current state of knowledge & belief about the value being tested. In a test the null hypothesis is constructed with alternative hypothesis denoted by 𝐻1 ,when a hypothesis is completely specified then it is called a simple hypothesis, when all factors of a distribution are not known then the hypothesis is known as a composite hypothesis.
Testing Of Hypothesis
The entire process of statistical inference is mainly inductive in nature, i.e., it is based on deciding the characteristics of the population on the basis of sample study. Such a decision always involves an element of risk i.e., the risk of taking wrong decisions. It is here that modern theory of probability plays a vital role & the statistical technique that helps us at arriving at the criterion for such decision is known as the testing of hypothesis.
Testing Of Statistical Hypothesis
A test of a statistical hypothesis is a two action decision after observing a random sample from the given population. The two action being the acceptance or rejection of hypothesis under consideration. Therefore a test is a rule which divides the entire sample space into two subsets.
A region is which the data is consistent with 𝐻0.
The second is its complement in which the data is inconsistent with 𝐻0.
The actual decision is however based on the values of the suitable functions of the data, the test statistic. The set of all possible values of a test statistic which is consistent with 𝐻0 is the acceptance region and all these values of the test statistic which is inconsistent with 𝐻0 is called the critical region. One important condition that must be kept in mind for efficient working of a test statistic is that the distribution must be specified.
Does the acceptance of a statistical hypothesis necessarily imply that it is true?
The truth a fallacy of a statistical hypothesis is based on the information contained in the sample. The rejection or the acceptance of the hypothesis is contingent on the consistency or inconsistency of the 𝐻0 with the sample observations. Therefore it should be clearly bowed in mind that the acceptance of a statistical hypothesis is due to the insufficient evidence provided by the sample to reject it & it doesn’t necessarily imply that it is true.
Elements: Null Hypothesis, Alternative Hypothesis, Pot
Null Hypothesis
A Null hypothesis is a hypothesis that says there is no statistical significance between the two variables in the hypothesis. There is no difference between certain characteristics of a population. It is denoted by the symbol 𝐻0. For example, the null hypothesis may be that the population mean is 40 then
𝐻0(𝜇 = 40)
Let us suppose that two different concerns manufacture drugs for including sleep, drug A manufactured by first concern and drug B manufactured by second concern. Each company claims that its drug is superior to that of the other and it is desired to test which is a superior drug A or B? To formulate the statistical hypothesis let X be a random variable which denotes the additional hours of sleep gained by an individual when drug A is given and let the random variable Y denote the additional hours to sleep gained when drug B is used. Let us suppose that X and Y follow the probability distributions with means 𝜇𝑥 and 𝜇𝑌 respectively.
Here our null hypothesis would be that there is no difference between the effects of two drugs. Symbolically,
𝐻0: 𝜇𝑋 = 𝜇𝑌
Alternative Hypothesis
A statistical hypothesis which differs from the null hypothesis is called an Alternative Hypothesis, and is denoted by 𝐻1. The alternative hypothesis is not tested, but its acceptance (rejection) depends on the rejection (acceptance) of the null hypothesis. Alternative hypothesis contradicts the null hypothesis. The choice of an appropriate critical region depends on the type of alternative hypothesis, whether both-sided, one-sided (right/left) or specified alternative.
Alternative hypothesis is usually denoted by 𝐻1.
For example, in the drugs problem, the alternative hypothesis could be
Power Of Test
The null hypothesis 𝐻0 𝜃 = 𝜃0 is accepted when the observed value of test statistic lies the critical region, as determined by the test procedure. Suppose that the true value of 𝜃 is not 𝜃0, but another value 𝜃1, i.e. a specified alternative hypothesis 𝐻1 𝜃 = 𝜃1 is true. Type II error is committed if 𝐻0 is not rejected, i.e. the test statistic lies outside the critical region. Hence the probability of Type II error is a function of 𝜃1, because now 𝜃 = 𝜃1 is assumed to be true. If 𝛽 𝜃1 denotes the probability of Type II error, when 𝜃 = 𝜃1 is true, the complementary probability 1 − 𝛽 𝜃1 is called power of the test against the specified alternative 𝐻1 𝜃 = 𝜃1 . Power = 1-Probability of Type II error=Probability of rejection 𝐻0 when 𝐻1 is true Obviously, we could like a test to be as ‘powerful’ as possible for all critical regions of the same size. Treated as a function of 𝜃, the expression of 𝑃 𝜃 = 1 − 𝛽 𝜃 is called Power Function of the test for 𝜃0 against 𝜃. the curve obtained by plotting P(𝜃) against all possible values of 𝜃, is known as Power Curve.
Elements: Type I & Type II Error
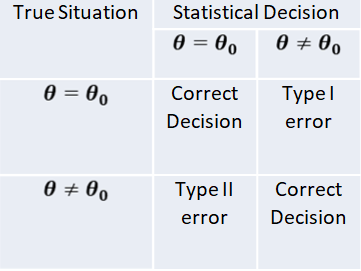
Type I Error & Type Ii Error
The procedure of testing statistical hypothesis does not guarantee that all decisions are perfectly accurate. At times, the test may lead to erroneous conclusions. This is so, because the decision is taken on the basis of sample values, which are themselves fluctuating and depend purely on chance. The errors in statistical decisions are two types:
Type I Error – This is the error committed by the test in rejecting a true null hypothesis.
Type II Error – This is the error committed by the test in accepting a false null hypothesis.
Considering for the population mean is 40, i.e. 𝐻0 𝜇 = 40 , let us imagine that we have a random sample from a population whose mean is really 40. if we apply the test for 𝐻0 𝜇 = 40 , we might find that the values of test statistic lines in the critical region, thereby leading to the conclusion that the population mean is not 40; i.e. the test rejects the null hypothesis although it is true. We have thus committed what is known as “Type I error” or “Error of first kind”. On the other hand, suppose that we have a random sample from a population whose mean is known to different from 40, say 43. if we apply the test for 𝐻0 𝜇 = 40 , the value of the statistic may, by chance, lie in the acceptance region, leading to the conclusion that the mean may be 40; i.e. the test does not reject the null hypothesis 𝐻0 𝜇 = 40 , although it is false. This is again another form of incorrect decision, and the error thus committed is known as “Type II error” or “Error of second kind”.
Using sampling distribution of the test statistic, we can measure in advance the probabilities of committing the two types of error. Since the null hypothesis is rejected only when the test statistic falls in the critical region.
Probability of Type I error = Probability of rejecting 𝐻0 𝜃 = 𝜃0 , when it is true = Probability that the test statistic lies in the critical region, assuming 𝜃 = 𝜃0.
The probability of Type I error must not exceed the level of significance (𝛼) of the test.
The probability of Type II error assumes different values for different values of 𝜃 covered by the alternative hypothesis 𝐻1. Since the null hypothesis is accepted only when the observed value of the best statistic lies outside the critical region.
Probability of Type II error 𝑊ℎ𝑒𝑛 𝜃 = 𝜃1 = Probability of accepting 𝐻0 𝜃 = 𝜃0 , when it is false = Probability that the test statistic lies in the region of acceptance, assuming 𝜃 = 𝜃1
The probability of Type I error is necessary for constructing a test of significance. It is in fact the ‘size of the Critical Region’. The probability of Type II error is used to measure the “power” of the test in detecting falsity of the null hypothesis. When the population has a continuous distribution
Probability of Type I error = Level of significance = Size of critical region
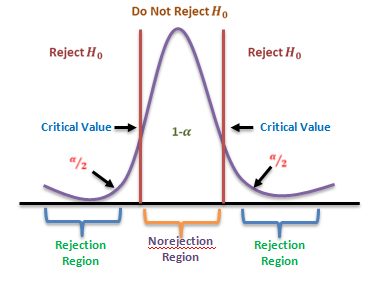
Elements: Level Of Significance & Critical Region
Level Of Significance And Critical Region
The decision about rejection or otherwise of the null hypothesis is based on probability considerations. Assuming the null hypothesis to be true, we calculate the probability of obtaining a difference equal to or greater than the observed difference. If this probability is found to be small, say less than .05, the conclusion is that the observed value of the statistic is rather unusual and has been caused due to the underlying assumption (i.e. null hypothesis) that is not true. We say that the observed difference is significant at 5 per cent level, and hence the ‘null hypothesis is rejected’ at 5 per cent level of significance. If, however, this probability is not very small, say more than .05, the observed difference cannot be considered to be unusual and is attributed to sampling fluctuation only. The difference is, now said to be not significant at 5 per cent level, and we conclude that there is no reason to reject the null hypothesis’ at 5 per cent level of significance. It has become customary to use 5% and 1% level of significance, although other levels, such as 2% or 5% may also be used.
Without actually going to calculate this probability, the test of significance may be simplified as follows. From the sampling distribution of the statistic, we find the maximum difference is which is exceeded in (say 5) percent of cases. If the observed difference in larger than this value, the null hypothesis is rejected. It is less there in no reason to reject the null hypothesis.
Suppose, the sampling distribution of the statistic is a normal distribution. Since the area under normal curve outside the ordinates at mean ±1.96 (𝑠. 𝑑. ) is only 5%, the probability that the observed value of the statistic differs from the expected value of 1.96 times the S.E. or more is .05; and the probability of a larger difference will be still smaller. If, therefore
Is either greater than 1.96 or less than -1.96 (i.e. numerically greater than 1.96), the null hypothesis 𝐻0 is rejected at 5% level of significance. The set values 𝑧 ≥ 1.96 𝑜𝑟 ≤ −1.96, i.e.
|𝑧| ≥ 1.96
constitutes what is called the Critical Region for the test. Similarly since the area outside mean ±2.58 (s.d.) is only 1%. 𝐻0 is rejected at 1% level of significance, if z numerically exceeds 258, i.e. the critical region is 𝑧 ≥ 2.58 at 1% level. Using the sampling distribution of an appropriate test statistic we are able to establish the maximum difference at a specified level between the observed and expected values that is consistent with null hypothesis 𝐻0 . The set of values of the test statistic corresponding to this difference which lead to the acceptance of 𝐻0 is called Region of acceptance. Conversely, the set of values of the statistic leading to the rejection of 𝐻0 is referred to as Region of Rejection or “Critical Region” of the test. The value of the statistic which lies at the boundary of the regions of acceptance and the rejection is called Critical value. When the null hypothesis is true, the probability of observed value of the test statistic falling in the critical region is often called the “Size of Critical Region”.
𝑆𝑖𝑧𝑒 𝑜𝑓 𝐶𝑟𝑖𝑡𝑖𝑐𝑎𝑙 𝑅𝑒𝑔𝑖𝑜𝑛 ≤ 𝐿𝑒𝑣𝑒𝑙 𝑜𝑓 𝑆𝑖𝑔𝑛𝑖𝑓𝑖𝑐𝑎𝑛𝑐𝑒
However, for a continuous population, the critical region is so determined that its size equals the Level of Significance (𝛼).
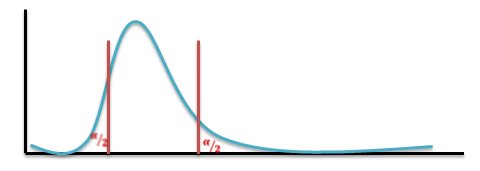
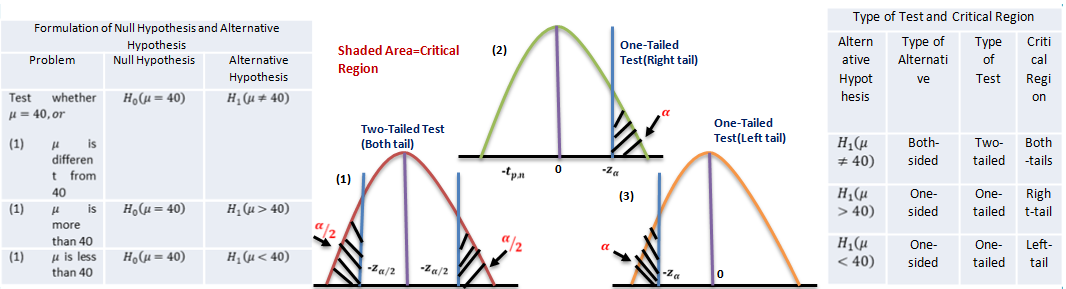
Two-Tailed And One-Tailed Tests
Our discussion above were centered around testing the significance of ‘difference’ between the observed and expected values, i.e. whether the observed value is significantly different from (i.e. either larger or smaller than) the expected value, as could arise due to fluctuations of random sampling. In the illustration, the null hypothesis is tested against “both-sided alternatives” 𝜇 > 40 𝑜𝑟 𝜇 < 40 , i.e.
𝐻0 𝜇 = 40 𝑎𝑔𝑎𝑖𝑛𝑠𝑡 𝐻1 𝜇 ≠ 40
Thus assuming 𝐻0 to be true, we would be looking for large differences on both sides of the expected value, i.e. in “both tails” of the distribution. Such tests are, therefore, called “Two-tailed tests”.
Sometimes we are interested in tests for large differences on one side only i.e., in one ‘one tail’ of the distribution. For example, whether a change in the production bricks with a ‘higher’ breaking strength, or whether a change in the production technique yields ‘lower’ percentage of defectives. These are known as “One-tailed tests”.
For testing the null hypothesis against “one-sided alternatives (right side)” 𝜇 > 40 , i.e.
𝐻0 𝜇 = 40 𝑎𝑔𝑎𝑖𝑛𝑠𝑡𝐻1 𝜇 > 40
The calculated value of the statistic z is compared with 1.645, since 5% of the area under the standard normal curve lies to the right of 1.645. if the observed value of z exceeds 1.645, the null hypothesis 𝐻0 is rejected at 5% level of significance. If a 1% level were used, we would replace 1.645 by 2.33. thus the critical regions for test at 5% and 1% levels are 𝑧 ≥ 1.645 and 𝑧 ≥ 2.33 respectively.
For testing the null hypothesis against “one-sided alternatives (left side)” 𝜇 < 40 i.e.
𝐻0 𝜇 = 40 𝑎𝑔𝑎𝑖𝑛𝑠𝑡𝐻1 𝜇 < 40
The value of z is compared with -1.645 for significance at 5% level, and with -2.33 for significance at 1% level. The critical regions are now 𝑧 ≤ −1.645 and 𝑧 ≤ −2.33 for 5% and 1% levels respectively. In fact, the sampling distributions of many of the commonly-used statistics can be approximated by normal distributions as the sample size increases, so that these rules are applicable in most cases when the sample size is ‘large’, say, more than 30. It is evident that the same null hypothesis may be tested against alternative hypothesis of different types depending on the nature of the problem. Correspondingly, the type of test and the critical region associated with each test will also be different.
Solving Testing Of Hypothesis Problem
Step 1 Set up the “Null Hypothesis” 𝐻0 and the “Alternative Hypothesis” 𝐻1 on the basis of the given problem. The null hypothesis usually specifies the values of some parameters involved in the population: 𝐻0 𝜃 = 𝜃0 . The alternative hypothesis may be any one of the following types: 𝐻1 ( ) 𝜃 ≠ 𝜃1 𝐻1 𝜃 > 𝜃0 , 𝐻1 𝜃 < 𝜃0 . The types of alternative hypothesis determines whether to use a two-tailed or one-tailed test (right or left tail).
Step 2
State the appropriate “test statistic” T and also its sampling distribution, when the null hypothesis is true. In large sample tests the statistic 𝑧 = (𝑇 − 𝜃0)Τ𝑆. 𝐸. , (T) which approximately follows Standard Normal Distribution, is often used. In small sample tests, the population is assumed to be Normal and various test statistics are used which follow Standard Normal, Chi-square, t for F distribution exactly.
Step 3 Select the “level of significance” 𝛼 of the test, if it is not specified in the given problem. This represents the maximum probability of committing a Type I error, i.e., of making a wrong decision by the test procedure when in fact the null hypothesis is true. Usually, a 5% or 1% level of significance is used (If nothing is mentioned, use 5% level).
Step 4
Find the “Critical region” of the test at the chosen level of significance. This represents the set of values of the test statistic which lead to rejection of the null hypothesis. The critical region always appears in one or both tails of the distribution, depending on weather the alternative hypothesis is one-sided or both-sided. The area in the tails must be equal to the level of significance 𝛼. For a one-tailed test, 𝛼 appears in one tail and for two-tailed test 𝛼/2 appears in each tail of the distribution. The critical region is
Where 𝑇𝛼 is the value of T such that the area to its tight is 𝛼.
Step 5
Compute the value of the test statistic T on the basis of sample data the null hypothesis. In large sample tests, if some parameters remain unknown they should be estimated from the sample. Step 6
If the computed value of test statistic T lies in the critical region, “reject 𝐻0”; otherwise “do not reject 𝐻0 ”. The decision regarding rejection or otherwise of 𝐻0 is made after a comparison of the computed value of T with critical value (i.e., boundary value of the appropriate critical region).
Step 7 Write the conclusion in plain non-technical language. If 𝐻0 is rejected, the interpretation is: “the data are not consistent with the assumption that the null hypothesis is true and hence 𝐻0 is not tenable”. If 𝐻0 is not rejected, “the data cannot provide any evidence against the null hypothesis and hence 𝐻0 may be accepted to the true”. The conclusion should preferably be given in the words stated in the problem.
Conclusion
Hypothesis is a statistical statement or a conjecture about the value of a parameter. The legal concept that one is innocent until proven guilty has an analogous use in the world of statistics. In devising a test, statisticians do not attempt to prove that a particular statement or hypothesis is true. Instead, they assume that the hypothesis is incorrect (like not guilty), and then work to find statistical evidence that would allow them to overturn that assumption. In statistics this process is referred to as hypothesis testing, and it is often used to test the relationship between two variables. A hypothesis makes a prediction about some relationship of interest. Then, based on actual data and a pre-selected level of statistical significance, that hypothesis is either accepted or rejected. There are some elements of hypothesis like null hypothesis, alternative hypothesis, type I & type II error, level of significance, critical region and power of test and some processes like one and two tail test to find the critical region of the graph as well as the error that help us reach the final conclusion.
A Null hypothesis is a hypothesis that says there is no statistical significance between the two variables in the hypothesis. There is no difference between certain characteristics of a population. It is denoted by the symbol 𝐻0. A statistical hypothesis which differs from the null hypothesis is called an Alternative Hypothesis, and is denoted by 𝐻1. The procedure of testing statistical hypothesis does not guarantee that all decisions are perfectly accurate. At times, the test may lead to erroneous conclusions. This is so, because the decision is taken on the basis of sample values, which are themselves fluctuating and depend purely on chance, this process called types of error. Hypothesis testing is very important part of statistical analysis. By the help of hypothesis testing many business problem can be solved accurately.
That was the fourth part of the series, that explained hypothesis testing and hopefully it clarified your notion of the same by discussing each crucial aspect of it. You can find more informative posts like this one on Data Science course topics. Just keep on following the Dexlab Analytics blog to stay informed.
As we continue our discussion on statistical inference, we move on to the estimation theory. Here you will learn about the concept of estimation, along with different elements and methods of estimation. You can check part-II here.
The estimation is the process of providing numerical values of the unknown parameter to the population. There are mainly two types of estimation process Point estimation and Interval estimation and confidence interval is the part of the interval estimation. We will also discuss about the elements of the estimation like parameter, statistic and estimator.
The characteristics of estimators are – (i) Unbiasedness – This is desirable property of a good estimator. (ii) Consistency – An estimator is said to be consistent if increasing the sample size produces an estimate with smaller standard error. (iii) Efficiency – An estimator should be an efficient estimator. (iv) Sufficiency – An estimator is said to be sufficient for a parameter, if it contains all the information in the sample regarding the parameter.
The methods of estimation are– (i) Method of maximum likelihood, (ii) Method of least square, (iii) Method of minimum variance, (iv) Method of moments.
Element For Estimation
Parameter
Parameter is an unknown numerical factor of the population. The primary interest of any survey lies in knowing the values of different measures of the population distribution of a variable of interest. The measures of population distribution involves its mean, standard deviation etc. which is calculated on the basis of the population values of the variable. In other words, the parameter is a functional form of all the population unit.
Statistic
Any statistical measure calculated on the basis of sample observations is called Statistic. Like sample mean, sample standard deviation, etc. Sample statistic are always known to us.
EstimatorAn estimator is a measure computed on the basis of sample values. It is a functional from of all sample observe prorating a representative value of the collected sample.Relation Between Parameter And Statistic
Parameter is a fixed measure describing the whole population (population being a group of people, things, animals, phenomena that share common characteristics.) A statistic is a characteristic of a sample, a portion of the target population. A parameter is fixed, unknown numerical value, while the statistic is a known number and a variable which depends on the portion of the population. Sample statistic and population parameters have different statistical notations: In population parameter, population proportion is represented by P, mean is represented by µ (Greek letter mu), σ2 represents variance, N represents population size, σ (Greek letter sigma) represents standard deviation, σx̄ represents Standard error of mean, σ/µ represents Coefficient of variation, (X-µ)/σ represents standardized variate (z), and σp represents standard error of proportion.
In sample statistics, mean is represented by x̄(x-bar), sample proportion is represented by p̂(p-hat), s represents standard deviation, s2 represents variance, sample size is represented by n, sx̄ represents Standard error of mean, sp represents standard error of proportion, s/(x̄) represents Coefficient of variation, and (x-x)/s ̄ represents standardized variate (z).
What Is Estimation?
Estimation refers to the process by which one makes an idea about a population, based on information obtained from a sample.
Suppose we have a random sample 𝑥1, 𝑥2, … , 𝑥𝑛 on a variable x, whose distribution in the population involves an unknown parameter 𝜃. It is required to find an estimate of 𝜃 on the basis of sample values. The estimation is done in two different ways: (i) Point Estimation, and (ii) Interval Estimation.
In point estimation, the estimated value is given by a single quantity, which is a function of sample observations. This function is called the ‘estimator’ of the parameter, and the value of the estimator in a particular sample is called an ‘estimate’.
Interval estimation, an interval within which the parameter is expected to lie in given by using two quantities based on sample values. This is known as Confidence interval, and the two quantities which are used to specify the interval, are known as Confidence Limits.
Point Estimation
Many functions of sample observations may be proposed as estimators of the same parameter. For example, either the mean or median or mode of the sample values may be used to estimate the parameter 𝜇 of the normal distribution with probability density function
Which we shall in future refer to as 𝑁(𝜇, 𝜎 2 ).
Interval Estimation
In statistical analysis it is not always possible to find out an exact point estimate to form an idea about the population parameters. An approximately true picture can be formed if the sample estimations satisfy some important property such as unbiasedness consistency, sufficiency, efficiency & so on. So, a more general concept of estimation would be to find out an interval based on sample values which is expected to include the unknown parameter with a specified probability. This is known as the theory of interval estimator.
Confidence Interval
Let 𝑥1, 𝑥2,… , 𝑥𝑛 be a random sample from a population involve an unknown parameter 𝜃. Our job is to find out two functions 𝑡1 & 𝑡2 of the sample values. Such that the probability of 𝜃 being included in the random interval 𝑡1,𝑡2 has a given value say 1 − 𝛼 . So,
Here the interval [𝑡1,𝑡2] is called a 100 × ( ) 1 − 𝛼 % confidence interval for the parameter 𝜃. The quantities 𝑡1 & 𝑡2 which serve as the lower & upper limits of the interval are known as confidence limits. 1 − 𝛼 is called the confidence coefficient. The is a sort of measures of the trust or confidence that one may place in the interval for actually including 𝜃.
Characteristics of Estimation
Unbiasedness
A statistic t is said to be an Unbiased Estimator of parameter 𝜃, if the expected value of t is 𝜃. 𝐸 𝑡 = 𝜃 Otherwise, the estimator is said to be ‘biased’. The bias of a statistic in estimating 𝜃 is given as 𝐵𝑖𝑎𝑠 = 𝐸 𝑡 − 𝜃 Let 𝑥1, 𝑥2,… , 𝑥𝑛 be a random sample drawn from a population with mean 𝜇 and variance 𝜎 2 . Then Sample mean
Sample varianceThe sample mean 𝑥ҧis an unbiased estimator of the population mean 𝜇; because 𝐸 𝑥ҧ = 𝜇 The sample variance 𝑆 2 is a biased estimator of the population variance 𝜎 2 ; because
An unbiased estimator of the population variance 𝜎 2 is given by
Because
The distinction between 𝑆 2 and 𝑠 2 in which only he denominators are different. 𝑆 2 is the variance of the sample observations, but 𝑠 2 is the ‘unbiased estimator’ of the variance (𝜎 2 ) in the population.
Example:
Characteristics of Estimation (Sufficiency, Efficiency, Consistency)
Consistency
A desirable property of good estimator is that its accuracy should increase when the sample becomes larger. That is, the estimator is expected to come closer to the parameter as the size of the sample increases.
A statistic 𝑡𝑛 computed from a sample of n observations is said to be a Consistent Estimator of a parameter 𝜃, if it converges in probability to 𝜃 as n tends to infinity. This means that the larger the sample size (n), the less is the chance that the difference between 𝑡𝑛 and 𝜃 will exceed any fixed value. In symbols, given any arbitrary small positive quantity 𝜖, 𝜇 , then the statistic 𝑡𝑛 will be a ‘consistent estimator’ of 𝜃. Consistency is a limiting property. Moreover, several consistent estimators may exist for the same parameter. For example, in sampling from a normal population 𝑁 𝜇, 𝜎 2 , both the sample mean and sample median are consistent estimators of 𝜇.
Efficiency
If we confine ourselves to unbiased estimates, there will, in general, exist more than one consistent estimator of a parameter. For example, in sampling from a normal population 𝑁 𝜇, 𝜎 2 , when 𝜎 2 is known, sample mean 𝑥ҧis an unbiased and consistent estimator of 𝜇. From symmetry it follows immediately the sample median (Md) is an unbiased estimate of 𝜇. Which is same as the population median. Also for large n,
Median is also an unbiased and consistent estimator of 𝜇.
Thus, there is necessity of some further criterion which will enable us to choose between the estimators with the common property of consistency.
Such a criterion which is based on the variance of the sampling distribution of estimators is usually known as Efficiency.
Sufficiency
A statistic is said to be a ‘sufficient estimator’ of a parameter 𝜃, if it contains all information in the sample about 𝜃. If a statistic t exists such that the joint distribution of the sample is expressible as the product of two factors, one of which is the sampling distribution of t and contains 𝜃, but the other factor is independent of 𝜃, then t will be a sufficient estimator of 𝜃.
Thus if 𝑥1, 𝑥2,… , 𝑥𝑛 is a random sample from a population whose probability mass function or probability density function is 𝑓 𝑥, 𝜃 , and t is a sufficient estimator of 𝜃 then we can write
Where g(t, 𝜃) is the sampling distribution of t and contains 𝜃, but ℎ (𝑥1, 𝑥2,… , 𝑥𝑛) is independent of 𝜃.
Since the parameter 𝜃 is occurring in the joint distribution of all the sample observations can be contained in the distribution of the statistic t, it is said that t alone can provide all ‘information’ about 𝜃 and is therefore “sufficient” for 𝜃.
Sufficient estimators are the most desirable kind of estimators, but unfortunately they exist in only relatively few cases. If a sufficient estimator exists, it can be found by the method of maximum likelihood.
In random sampling from a Normal population 𝑁 (𝜇, 𝜎 2) , the sample mean 𝑥ҧis a sufficient estimator of 𝜇.
Methods of Estimation (MLE, MLS)
Method of Maximum Likelihood
This is a convenient method for finding an estimator which satisfies most of the criteria discussed earlier. Let 𝑥1, 𝑥2,… , 𝑥𝑛 be a random sample from a population with p.m.f (for discrete case) or p.d.f. (for continuous case) 𝑓 𝑥, 𝜃 , where 𝜃 is the parameter. Then the joint distribution of the sample observations
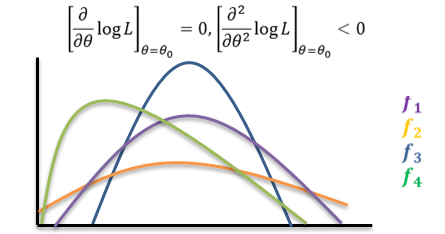
is called the Likelihood Function of the sample. The Method of Maximum Likelihood consists in choosing as an estimator of 𝜃 that statistic, which when substituted for 𝜃, maximizes the likelihood function L. such a statistic is called a maximum likelihood estimator (m.l.e.). We shall denote the m.l.e. of 𝜃 by the symbol 𝜃0. Since log 𝐿 is maximum when L is maximum, in practice the m.l.e. of 𝜃 is obtained by maximizing log 𝐿 . This is achieved by differentiating log 𝐿 partially with respect to 𝜃, and using the two relations
The m.l.e. is not necessarily unbiased. But when the m.l.e. is biased, by a slight modification, it can be converted into an unbiased estimator. The m.l.e. tends to be distributed normally for large samples. The m.l.e. is invariant under functional transformations. If T is an m.l.e. of 𝜃, and 𝑔(𝜃) is a function of 𝜃, then g(T) is the m.l.e. of 𝑔(𝜃) .
Method Of Least Square
Method of Least Squares is a device for finding the equation of a specified type of curve, which best fits a given set of observations. The principal of least squares is used to fit a curve of the form:
𝑦𝑖 = 𝑓 𝑥𝑖 be a function where 𝑥𝑖 is an explanatory variable. & 𝑦𝑖 is the dependent variable. Let us assume a linear relationship between the dependent & independent variable. So,
The objective of the researcher is to minimize σ𝑙𝑖 2, σ 𝑒𝑖 is not minimized because σ 𝑒𝑖 = 0 but actual error of individual observation can remain
The method of least squares can be used to fit other types of curves, e.g. parabola, exponential curve, etc. method of least squares is applied to find regression lines and also in the determination of trend in time series.
Methods of Estimation (MMV, MM)
Method of Minimum Variance
Minimum Variance Unbiased Estimates, the estimates 𝑖 𝑇 𝑖𝑠 𝑢𝑛𝑏𝑖𝑎𝑠𝑒𝑑 𝑓𝑜𝑟 𝛾 𝜃 , 𝑓𝑜𝑟 𝑎𝑙𝑙 𝜃𝜖𝜗 are unbiased and [(ii) It has smallest variance among the class of all unbiased estimators of 𝛾(𝜃), then T is called the minimum variance unbiased estimator (MVUE) of 𝛾(𝜃)] have minimum variance.
If 𝐿 = ς𝑖=1 𝑛 𝑓 𝑥𝑖 , 𝜃 , is the likelihood function of a random sample of n observations 𝑥1, 𝑥2, … , 𝑥𝑛 from a population with probability function 𝑓(𝑥, 𝜃), then the problem is to find a statistics 𝑡 = 𝑡(𝑥1, 𝑥2,… , 𝑥𝑛), such that
Method of Moments
This method was discovered and studied in detail by Karl Pearson. Let 𝑓 𝑥; 𝜃1, 𝜃2, … , 𝜃𝑘 be the density function of the parent population with k parameters 𝜃1, 𝜃2,… , 𝜃𝑘. If 𝜇𝑟 ′ denoted the rth moment about origin, then
Let 𝑥𝑖 , 𝑖 = 1,2, … , 𝑛 be a random sample of size n from the given population. The method of moments consists in solving the k-equations for 𝜃1, 𝜃2,… , 𝜃𝑘 in terms of 𝜇1 ′ , 𝜇2 ′ ,… , 𝜇𝑘 ′ and then replacing these moments 𝜇𝑟 ′ ; 𝑟 = 1,2,… , 𝑘 by the sample moments,
Where 𝑚𝑖 ′ is the ith moment about origin in the sample.
Then by the method of moments 𝜃1, 𝜃2,… , 𝜃𝑘 are the required estimator of 𝜃1, 𝜃2,… . , 𝜃𝑘 respectively.
Conclusion
Estimation theory is a branch of statistics and signal processing that deals with estimating the values of parameters based on measured/empirical data that has a random component. The parameters describe an unknown numerical factor of the population. The primary interest of any survey lies in knowing the values of different measures of the population distribution of a variable of interest. The measures of population distribution involves its mean, standard deviation etc. which is calculated on the basis of the population values of the variable. The estimation theory has its own characteristics like the data should be unbiased, a good estimator is that its accuracy should increase when the sample size becomes larger, The sample mean and sample median should be consistent estimators of parameter mean, The estimator is expected to come closer to the parameter as the size of the sample increases. Two consistent estimators for the same parameter, the statistic with the smaller sampling variance is said to be more efficient, so, efficiency is another characteristic of the estimation. The estimator should be sufficient estimator of a parameter theta.
The estimation theory follows some methods by this method and with the characteristics we can properly estimate from the data. The methods we already discussed that maximum likelihood method, least square method, minimum variance method & method of moments.
In real life, estimation is part of our everyday experience. When you’re shopping in the grocery store and trying to stay within a budget, for example, you estimate the cost of the items you put in your cart to keep a running total in your head. When you’re purchasing tickets for a group of people or splitting the cost of dinner between 8 friends, we estimate for ease. In many other field we can use the estimation theory specially for statistical analysis.
If you found this blog helpful then, then keep on exploring DexLab Analytics blog to pursue more informative posts on diverse topics such as python for data analysis. Also, check out part-I AND part- II of the series to keep pace.
Here is taking an in-depth look at how sampling distribution works along with a discussion on various types of the sampling distribution. This is a continuation of the discussion on Classical Inferential Statistics that focused on the theory of sampling, breaking it down to building blocks of classical sampling theory along with various kinds of sampling. You can read part 1 of the article here
The sampling distribution is a probability distribution of statistics obtained from a large number of samples drawn from a specific population. And the types of sampling distribution are- (i) Gamma Distribution, (ii) Beta Distribution, (iii) Chi-Square Distribution, (iv) Exponential Distribution, (v) T-Distribution & (vi) F-Distribution.
The key components for describing all these distributions are – (i) Probability Density Function – Which is the function whose integral is to be calculated to find probabilities associated with a continuous random variable and their shape(graph) for the same, (ii) Moment Generating Function – which helps to find the moment of those distributions, and (iii) Degrees of Freedom – It refers to the number of independent sample points and compute a static minus the number of parameters explained from the sample.
For Gamma and Beta distribution, we will discuss gamma and beta function and relation between them etc.
2. Probability Density Function, Moment Generating Function, Sampling Distribution, Degrees of Freedom
PROBABILITY DENSITY FUNCTION
Probability density function (PDF), in statistics, is a function whose integral is calculated to find probabilities associated with a continuous random variable (see continuity; probability theory). Its graph is a curve above the horizontal axis that defines a total area, between itself and the axis, of 1. The percentage of this area included between any two values coincides with the probability that the outcome of an observation described by the probability density function falls between those values. Every random variable is associated with a probability density function (e.g., a variable with a normal distribution is described by a bell curve). If X be continuous Random variable taking any continuous real values then f(x) is a probability density function if:-
Moment Generating Function
The moment generating function (m.g.f.) of a random variable X (about origin) having the probability function f(x) is given by:
The integration of summation being extended to the entire range of x, t being the real parameter and it is being assumed that the right-hand side of the equation is absolutely convergent for some positive number h such that –h<t<h.
SAMPLING DISTRIBUTION
It may be defined as the probability law which the statistic follows if repeated random samples of a fixed size are drawn from a specified population. A number of samples, each of size n, are taken from the same population and if for each sample the values of the statistic are calculated, a series of values of the statistic will be obtained. If the number of samples is large, these may be arranged into a frequency table. The frequency distribution of the statistic that would be obtained if the number of samples, each of the same size (say n), were infinite is called the Sampling distribution of the statistic
DEGREES OF FREEDOM
The term degrees of freedom (df) refers to the number of independent sample points used to compute a statistic minus the number of parameters estimated from the sample points: For example, consider the sample estimate of the population variance (s2)
Where is the score for observation i in the sample, X ̅ is the sample estimate of the population mean, n is the number of observation in the sample. The formula is based on n independent sample points and one estimated population parameter (x ̅). Therefore, the number of degrees of freedom is n minus one. For this example
df=n-1
3. Gamma Function, Beta Function, Relation between Gamma &Beta Function
GAMMA FUNCTION
The Gamma function is defined for x>0 in integral form by the improper integral known as Euler’s integral of the second kind.
Many probability distributions are defined by using the gamma function, such as gamma distribution, beta distribution, chi-squared distribution, student’s t-distribution, etc. For data scientists, machine learning engineers, researchers, the Gamma function is probably one of the most widely used functions because it is employed in many distributions.
BETA FUNCTION
The Beta function is a function of two variables that is often found in probability theory and mathematical statistics.
The Beta function is a function B: R_(++)^2→R defined as follows:
There is also a Euler’s integral of the first kind.
For example, as a normalizing constant in the probability density functions of the F distribution and of the Student’s t distribution
RELATION BETWEEN GAMMA AND BETA FUNCTION
In the realm of Calculus, many complex integrals can be reduced to expressions involving the Beta Function. The Beta Function is important in calculus due to its close connection to the Gamma Function which is itself a generalization of the factorial function.
We know,
So, the product of two factorials as
Now apply the changes of variables t=xy and s=x(1-y) to this double integral. Note that t + s = x and that 0 < t < ∞ and 0 < x < ∞ and 0 < y < 1. The jacobian of this transformation is
Since x > 0 we conclude that Hence we have
Therefore,
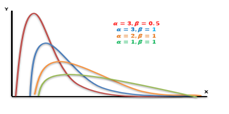
4. Gamma Distribution
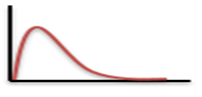
The gamma distribution is a widely used distribution. It is a right-skewed probability distribution. These distributions are useful in real life where something has a natural minimum of 0.
If X be a continuous random variable taking only positive values, then X is said to be following a gamma distribution iff its p.d.f can be expressed as:-
=0 otherwise….(1)
Probability Density Function for Gamma Distribution
For (1), to be the Probability Density Function, we must have:-
Now, f(x)>0 if x>0 & f(x)=0 if x taking any non-positive values, so, f(x)≥0 ∀x .
Hence, condition (i) is satisfied. Now,
Using (3) & (4) in (2) we get:-
Hence, f(x) statistics condition (ii).
So, equation (1) is a proper pdf.
Moment Generating Function for Gamma Distribution
Moment generating functions are general procedure of finding out moments of a probability distribution mathematically it may be expressed as- M_x (t)=E(e^xt )
This represents raw moments of the random variable X about to the origin 0.
Three important properties of m.g.f. are:- (i) where c is a constant.(ii) If ’s are independent Random variables i.e. then (iii) If X and Y are two random variables and if then X and Y are two identical distribution this is called the uniqueness property,Calculating the m.g.f. of gamma distribution:
Using (2) and (3) in (1) we get:
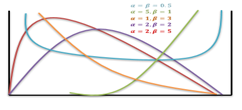
5. Beta Distribution
In probability theory and statistics, the beta distribution is a family of continuous probability distributions defined on the interval [0, 1] parameterized by two positive shape parameters, denoted by α and β, that appear as exponents of the random variable and control the shape of the distribution.
The beta distribution has been applied to model the behavior of random variables limited to intervals of finite length in a wide variety of disciplines.
Probability Density Function for Beta Distribution
The probability density function (PDF) of the beta distribution, for 0 ≤ x ≤ 1, and shape parameters α, β > 0, is a power function of the variable x and of its reflection (1 − x) as follows:
Where Γ(z) is the gamma function. The beta function, B, =+is a normalization constant to ensure that the total probability integrates to 1. In the above equations, x is a realization—an observed value that actually occurred—of a random process X.
This definition includes both ends x = 0 and x = 1, which is consistent with the definitions for other continuous distributions supported on a bounded interval which are special cases of the beta distribution, for example, the arcsine distribution, and consistent with several authors, like N. L. Johnson and S. Kotz. However, the inclusion of x= 0 and x= 1 does not work for α, β < 1; accordingly, several other authors, including W. Feller, choose to exclude the ends x = 0 and x = 1, (so that the two ends are not actually part of the domain of the density function) and consider instead 0 < x < 1. Several authors, including N. L. Johnson and S. Kotz, use the symbols p and q (instead of α and β) for the shape parameters of the beta distribution, reminiscent of the symbols are traditionally used for the parameters of the Bernoulli distribution, because the beta distribution approaches the Bernoulli distribution in the limit when both shape parameters α and β approach the value of zero.
In the following, a random variable X beta-distributed with parameters α and β will be denoted by:
Other notations for beta-distributed random variables used in the statistical literature are. X- Be(α,β)and X~β_(α,β)
Moment Generating Function for Beta Distribution
6. Chi-square Distribution & Exponential Distribution
CHI-SQUARE DISTRIBUTION
A chi-square distribution is defined as the sum of the squares of standard normal variates. Let x be a random variable which follows normal distribution with mean μ& variance then standard normal variate is defined as: –
The variate Z is said to follow a standard normal distribution with mean 0 and variance 1. Let X be a random variable containing observations,.
Then the chi-square distribution is defined as:- So we can say:-
A chi-square distribution with ‘n’ degree of freedom, where degrees of freedom refer to number of independent associations among variables.
The Probability Density Function of a Chi-Square Distribution:
The Moment Generating Function of Chi-Square Distribution:
(4) is a required m.g.f. of the chi-square distribution.
EXPONENTIAL DISTRIBUTION
The Exponential distribution is one of the widely used continuous distributions. It is often used to model the time elapsed between events.
The Probability Density Function of Exponential Distribution:
Let X be a continuous random variable assuming only real values then X is said to be following an exponential distribution iff:-
Therefore, exponential distribution is a special case of gamma
distribution with v = 1.
The Moment Generating Function of Exponential Distribution:
Let X~Exponential (λ), we can find its expected value as follows, using integration by parts:
Now let’s find Var (X), we have
7. T-Distribution & F-Distribution
T-DISTRIBUTION
Student’s t-distribution:
If x1,x2,… ,xn be ‘n’ random samples drawn from a normal population having mean & standard deviation then the statistics following student t-distribution with (n-1) degrees of freedom.
Fisher’s t-distribution:
Let X~N(0,1) & let the random variable Y~X_n^2. Both X & Y are independent random variables. Then the fisher’s t-distribution is defined as :-
Probability Density Function for t-distribution:
Where, t2 > 0 Where, v=(n-1) degrees of freedom
= 0 , otherwise
For Fisher’s t-distribution:
Where, t2 > 0
=0 otherwise
Application of t-distribution:
If x1,x2, and x3 are independent random variables. Each following a standard normal distribution. What will be the distribution of
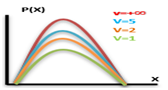
F- DISTRUBUTION
The F-Distribution is a ration of two chi-square distributions. If X be a random variable which follows a fisher’s t-distribution.Then:-
Squaring the above expression we get:
The R.V. X2~F1, n. Then we say X2 follows F-distribution with 1,n degrees of freedom.
Probability Density Function for F-distribution:
Application of F-Distribution:
Let x1,x2,… ,xn be a random sample drawn from a normal population with mean μ & variance σ2. where both μ & σ are unknown. Obtain the MLEs of θ.
Let x1,x2,… ,xn be ‘n’ random sample drawn from a normal population with mean μ & variance σ2.
Taking logarithms on both sides; we get:-
CONCLUSION: That was a thorough analysis of different types of sampling distribution along with their distinct functions and interrelations. If the resource was useful in understanding statistical analytics, find more such informative and analytical, subject-oriented discussion regarding statistical analytics courses on DexLab Analytics blog.
Hard Fact: Nowadays, all major organizations seek candidates who are technically sound, knowledgeable and creative. They don’t prefer spending time and money on employee training. Thus, fresh college graduates face a tricky situation.
Summer internship is a quick solution for them. Besides guaranteeing a valuable experience to the fresh graduates, internship helps them secure a quick job. However, the question is what exactly is a summer internship program and how does it help bag the best job in town?
What Is a Summer Internship?
Summer internships are mostly industrial-level training programs for students who are interested in core technical industry domain. Such internships offer students hands-on learning experience while letting them gain glimpses of the real world – following a practical approach. Put simply, summer trainings enhance skills, sharpen theoretical knowledge and are a great way to pursue a flourishing career. In most cases, the candidates are hired by the companies in which they are interning.
The duration of such internships is mostly between eight to twelve weeks following the college semesters. Mostly, they start from May or June and proceeds through August. So, technically, this is the time for summer internships and at DexLab Analytics, we offer industry-relevant certification courses that break open a gamut of job opportunities. Also, such accredited certifications add value to your CV. They help build powerful CVs.
Summers are crucial. If you are college-goer, you will understand that summertime is the most opportune time to explore diverse career interests without being bogged down by homework or classroom assignments.
Day by day, summer internships are becoming popular. Not only do they expose aspiring candidates to the nuances of the big bad world but also hone their communication skills, create great resumes and make them super confident. Building confidence is extremely important. If you want to survive in this competitive industry, you have to present a confident version of you. Summer training programs are great in this respect. Plus, they add value to your resume. A good internship will help you get noticed by the prospective employers. Always, try to add references; however, ask permission from your supervisors before including their names as references in your resume.
Moreover, summer training gives you the scope to experiment and explore options. Suppose, you are pursuing Marketing Major and bagged an internship in the same, but you are not happy with it. Maybe, marketing is not your thing. No worries! Complete your internship and move on.
On the other hand, let’s say you are very happy with your selected internship and want to do something in the respective field! Finish the internship, wait for some time and then try for recruitment in the same company where you interned or explore possibilities in the same domain.
It’s no wonder that summer internships open a roadway of opportunities. The technical aptitude and in-demand skills learned during the training help you accomplish your desired goal in life.
To learn more about Data Analyst with Advanced excel course – Enrol Now. To learn more about Data Analyst with R Course – Enrol Now. To learn more about Big Data Course – Enrol Now.
To learn more about Machine Learning Using Python and Spark – Enrol Now. To learn more about Data Analyst with SAS Course – Enrol Now. To learn more about Data Analyst with Apache Spark Course – Enrol Now. To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.
A flamboyant, sophisticated technology lashed with a heavy stroke of sci-fi, AI and machine learning – is today’s data science. To manage, control and understand such an elusive concept, we need highly skilled data specialists – they must have mastered thoroughly the art and science of machine learning, analytics and statistics.
As the world is becoming more dynamic, the roles of data analysts and professionals are found to be increasingly inclined towards precision, versatility and eccentricity. More and more, they are expected to do things differently, posing as catalysts for change. They play an incredible role in inspiring others and bringing accuracy and accountability within an organization.
Data Analysts Facilitate Solutions for Stakeholders
“Business analysis involves understanding how organizations function to accomplish their purposes and defining the capabilities an organization requires to provide products and services to external stakeholders,” shares International Institute of Business Analysis in its BABOK Guide.
The main job of a business analyst is to understand the current situation of a company and facilitate a respective solution to the problem. Mostly, a team of analysts work with the stakeholders to define their business goals and extract what they expect to be delivered. They gather a long range of business-fulfilled conditions and capabilities, document them in a collection and then eventually frame and strategize a plausible solution.
Analysts Have a Multifaceted Job Role
Mostly, they wear many hats as the tasks of analysts are widely versatile and always changing. Below, we have mentioned a few most common job responsibilities they have to perform every day:
As a matter of fact, the title ‘business analyst’ doesn’t matter much. To fulfill the role of a ‘business analyst’, you don’t have to an analyst at the first place. Many execute the tasks as part of their existing role – data analysts, user experience specialists, change managers and process analysts – each one of them can feature business analyst behaviour.
Put simply, you don’t have to be a business analyst to do the job of a business analyst.
Business Analysts Act As Interpreters
As always, different stakeholders have different goals, needs and knowledge regarding their businesses. Stakeholders can be anyone – managers to end users, vendors to customers, developers to testers, subject matter experts, architects and more. So, it depends on the analysts to bring together all this knowledge and analyze the information gathered. This, in turn, offers a clear understanding of company goals and vision. It bridges the gap between the business and IT.
For this and more, business analysts are often compared with interpreters. Just the way the latter translates French into English – analysts too translate their stakeholders’ query and needs into a language that IT professionals can easily grasp.
Hope this comprehensive list of thoughts has helped you understand what analysts do in general!
If you want to become a data analyst or interested in the study of analytics, drop by DexLab Analytics. They are a one-stop-destination to grab data analyst certification. For more, reach us at dexlabanalytics.com
To learn more about Data Analyst with Advanced excel course – Enrol Now. To learn more about Data Analyst with R Course – Enrol Now. To learn more about Big Data Course – Enrol Now.
To learn more about Machine Learning Using Python and Spark – Enrol Now. To learn more about Data Analyst with SAS Course – Enrol Now. To learn more about Data Analyst with Apache Spark Course – Enrol Now. To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.
Do you want to make a living as a successful business analyst? Does the prospect of analyzing data and drawing meaningful conclusions interest you? Are you thinking of taking the next big step into the career of analytics?
The demand for business analysts is soaring. It’s even touted as the highest paid job in the field of management. The job profile of a BA includes understanding a business organization critically, tapping into the ongoing business problems and filing a proper documentation of all business requirements and securing future success for the organization.
Below, we’ve whittled down few important FAQs on Business Analytics:
To understand or delve deeper into business analysis, opt for an excellent business analytics course in Delhi. Training courses as this will help you grab the hottest job in town.
Define business analysis.
Business analysis is a series of functions, implemented to assess the business needs and requirements and craft the best solution to ring bells of success in an organization or enterprise. This sequence of actions is generally performed by a business analyst.
Mention the industry and professional standards that a BA has to adhere to.
The most popular industry standards that have been set up for Business Analysts are OOAD principles and Unified Modeling Language (UML). They are recognized across the globe, so drafting requirements from any part of the world won’t be difficult.
What are the components of UML?
UML is a concoction of diverse concepts from a lot many sources.
For Structure: Actor, Attribute, Class, Component, Interface, Object, Package
For Behavior: Activity, Event, Message, Method, Operation, State, use case
For Relationships: Aggregation, Association, Composition, Depends, Generalization (or Inheritance)
Other Concepts: Stereotype – It qualifies the symbol it is attached to
Highlight the quality procedures that a BA normally follows.
Loud and clear, there exists no specific bar for such things, but if you ask us, Six Sigma and ITIL (Information Technology Infrastructural Library UK) have specific quality standards, which are more than enough. However, here we’ve enumerated some common things to consider:
Ensure the quality of communication is excellent and seamless.
Explore and decipher requirements of system functionality and user demands.
Collect, manage and analyze data for better business outcomes and future success of organizations in question.
Explain the procedure of Requirement Analysis.
JAD session usually precedes a Requirement Session. Business analysts, top notch sponsors and hardcore technical folks attend these significant sessions. In the end of the discussions, Business Analysts rifles through each requirement and asks from a valuable feedback. Now, if the sponsors and technical folks conclude all the requirements are as per business requirement, they will give an official signoff on business requirement documents, along with IT managers and business managers.
How do you define UML?
UML is the abbreviated form of Unified Modeling Language – which is referred to as a generic language for mentioning, envisioning, building and documenting the objects of software systems, business models and other non-software structures. Together, it’s a compilation of superior engineering practices that screams of proven success and functionability of large and complex models.
DexLab Analytics offers top of the line business analyst training Delhi – the course itinerary is crafted according to industry demands and seasoned consultants impart in-demand skill training to the aspiring candidates. For more information, visit their official site now.
To learn more about Data Analyst with Advanced excel course – Enrol Now. To learn more about Data Analyst with R Course – Enrol Now. To learn more about Big Data Course – Enrol Now.
To learn more about Machine Learning Using Python and Spark – Enrol Now. To learn more about Data Analyst with SAS Course – Enrol Now. To learn more about Data Analyst with Apache Spark Course – Enrol Now. To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.