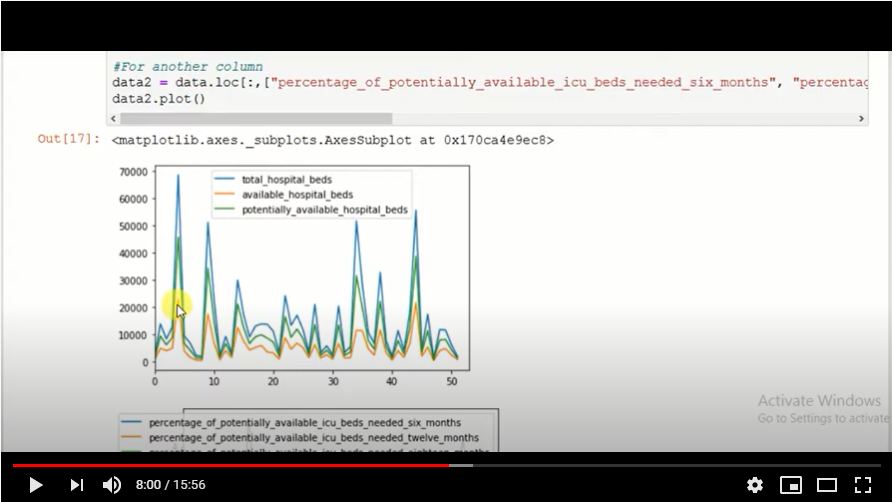
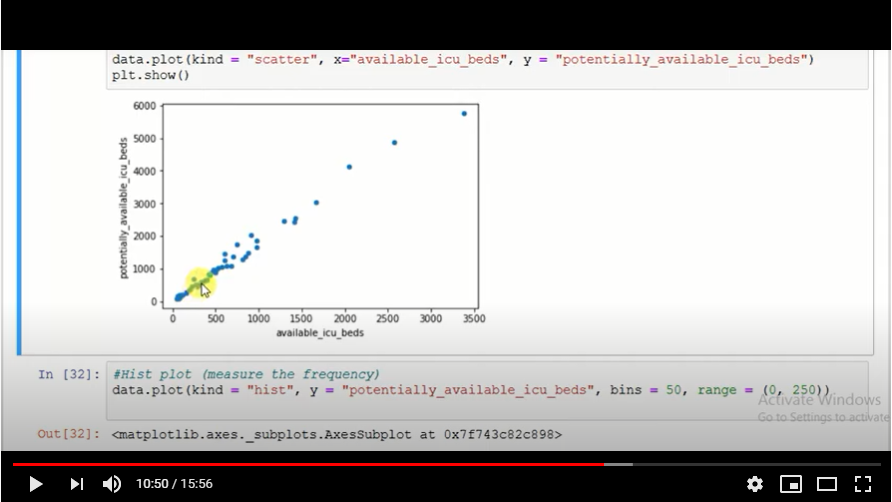
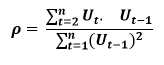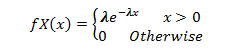This is another blog added to the series of time series forecasting. In this particular blog I will be discussing about the basic concepts of ARIMA model.
So what is ARIMA?
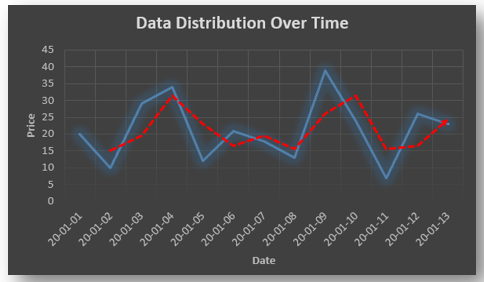
ARIMA also known as Autoregressive Integrated Moving Average is a time series forecasting model that helps us predict the future values on the basis of the past values. This model predicts the future values on the basis of the data’s own lags and its lagged errors.
When a data does not reflect any seasonal changes and plus it does not have a pattern of random white noise or residual then an ARIMA model can be used for forecasting.
There are three parameters attributed to an ARIMA model p, q and d :-
p :- corresponds to the autoregressive part
q:- corresponds to the moving average part.
d:- corresponds to number of differencing required to make the data stationary.
In our previous blog we have already discussed in detail what is p and q but what we haven’t discussed is what is d and what is the meaning of differencing (a term missing in ARMA model).
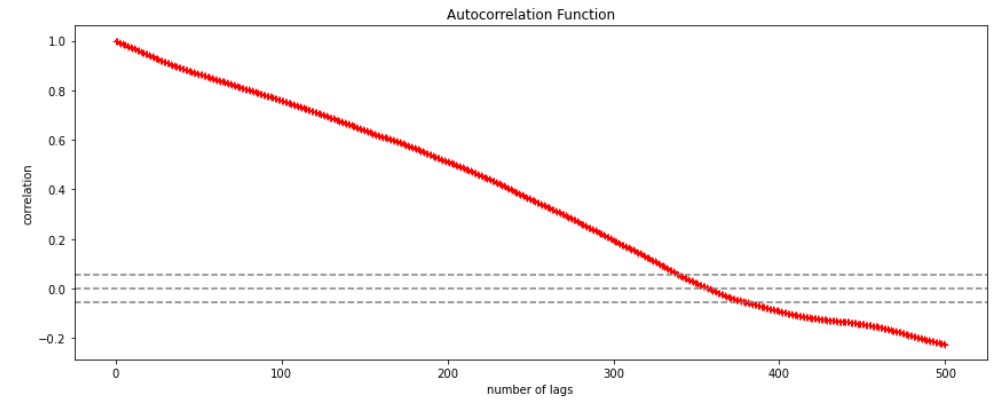
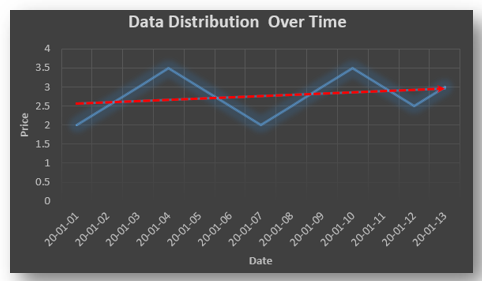
Since AR is a linear regression model and works best when the independent variables are not correlated, differencing can be used to make the model stationary which is subtracting the previous value from the current value so that the prediction of any further values can be stabilized . In case the model is already stationary the value of d=0. Therefore “differencing is the minimum number of deductions required to make the model stationary”. The order of d depends on exactly when your model becomes stationary i.e. in case the autocorrelation is positive over 10 lags then we can do further differencing otherwise in case autocorrelation is very negative at the first lag then we have an over-differenced series.
The formula for the ARIMA model would be:-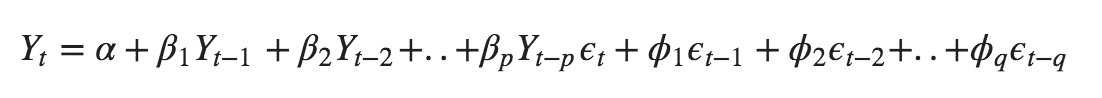
To check if ARIMA model is suited for our dataset i.e. to check the stationary of the data we will apply Dickey Fuller test and depending on the results we will using differencing.
In my next blog I will be discussing about how to perform time series forecasting using ARIMA model manually and what is Dickey Fuller test and how to apply that, so just keep on following us for more.
So, with that we come to the end of the discussion on the ARIMA Model. Hopefully it helped you understand the topic, for more information you can also watch the video tutorial attached down this blog. The blog is designed and prepared by Niharika Rai, Analytics Consultant, DexLab Analytics DexLab Analytics offers machine learning courses in Gurgaon. To keep on learning more, follow DexLab Analytics blog.
.