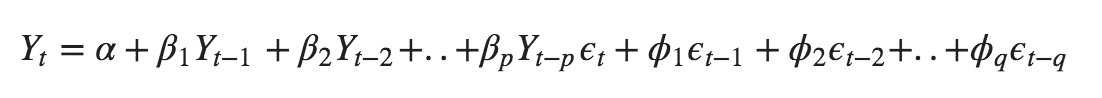In our previous blog we discussed about few of the basic functions of MQL like .find() , .count() , .pretty() etc. and in this blog we will continue to do the same. At the end of the blog there is a quiz for you to solve, feel free to test your knowledge and wisdom you have gained so far.
Given below is the list of functions that can be used for data wrangling:-
updateOne() :- This function is used to change the current value of a field in a single document.
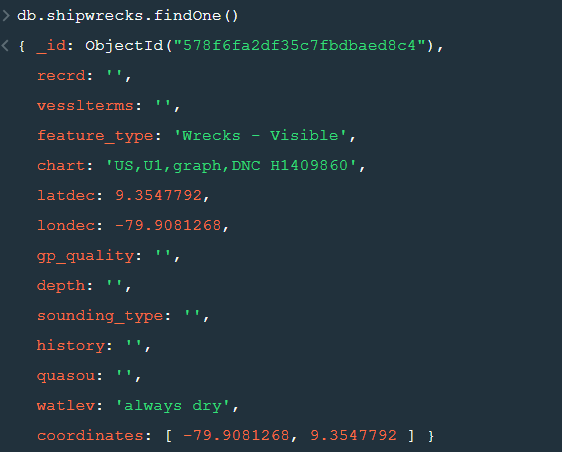
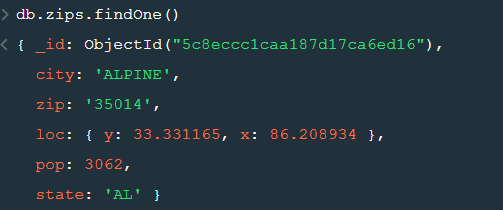
After changing the database to “sample_geospatial” we want to see what the document looks like? So for that we will use .findOne() function.
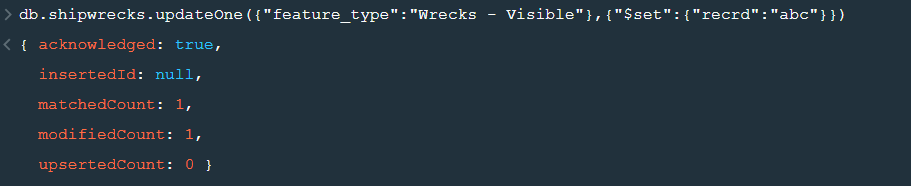
Now lets update the field value of “recrd” from ‘ ’ to “abc” where the “feature_type” is ‘Wrecks-Visible’.
Now within the .updateOne() funtion any thing in the first part of { } is the condition on the basis of which we want to update the given document and the second part is the changes which we want to make. Here we are saying that set the value as “abc” in the “recrd” field . In case you wanted to increase the value by a certain number ( assuming that the value is integer or float) you can use “$inc” instead.
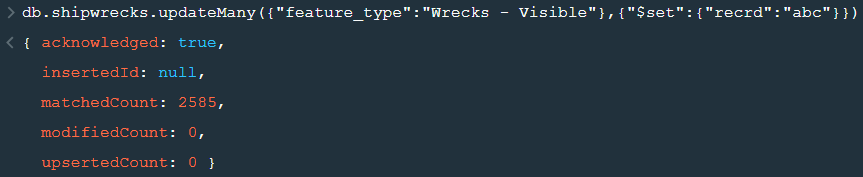
2. updateMany() :- This function updates many documents at once based on the condition provided.
3. deleteOne() & deleteMany() :- These functions are used to delete one or many documents based on the given condition or field.
4. Logical Operators :-
“$and” : It is used to match all the conditions.
“$or” : It is used to match any of the conditions.
The first code matches both the conditions i.e. name should be “Wetpaint” and “category_code” should be “web”, whereas the second code matches any one of the conditions i.e. either name should be “Wetpaint” or “Facebook”. Try these codes and see the difference by yourself.
So, with that we come to the end of the discussion on the MongoDB Basics. Hopefully it helped you understand the topic, for more information you can also watch the video tutorial attached down this blog. The blog is designed and prepared by Niharika Rai, Analytics Consultant, DexLab AnalyticsDexLab Analytics offers machine learning courses in Gurgaon. To keep on learning more, follow DexLab Analytics blog.
In this particular blog we will discuss about few of the basic functions of MQL (MongoDB Query Language) and we will also see how to use them? We will be using MongoDB Compass shell (MongoSH Beta) which is available in the latest version of MongoDB Compass.
Connect your Atlas cluster to your MongoDB Compass to get started. Latest version of MongoDB Compass will have this shell, so if you don’t find this shell then please install the latest version for this to work.
Now lets start with the functions.
find() :- You need this function for data extraction in the shell.
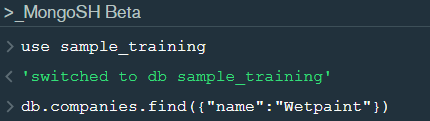
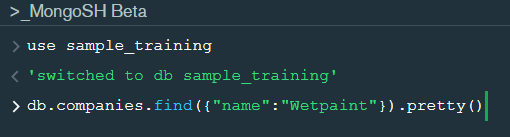
In the shell we need to first write the “use database name” code to access the database then use .find() to extract data which has name “Wetpaint”
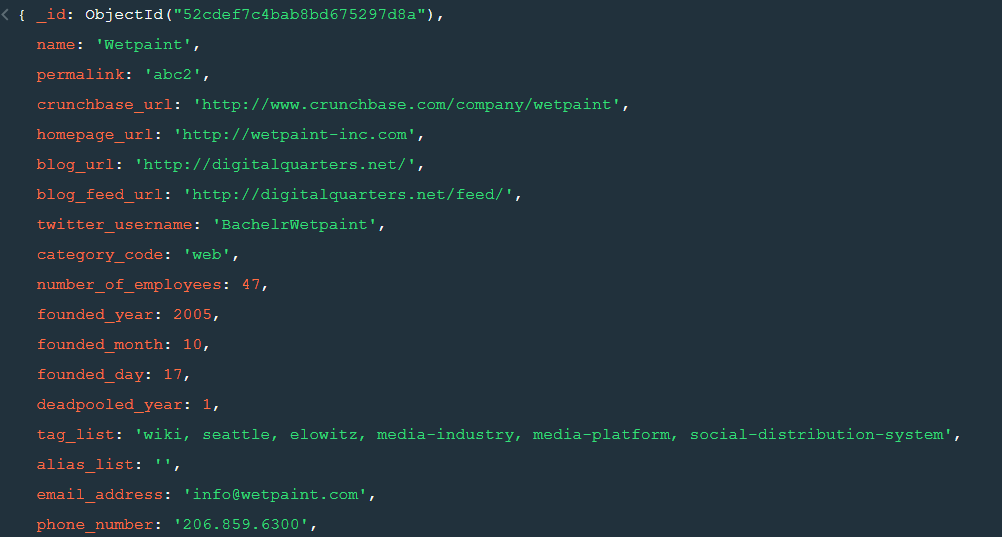
For the above query we get the following result:-
The above result brings us to another function .pretty() .
2. pretty() :- this function helps us see the result more clearly.
Try it yourself to compare the results.
3. count() :- Now lets see how many entries we have by the company name “Wetpaint”.
So we have only one document.
4. Comparison operators :-
“$eq” : Equal to
“$neq”: Not equal to
“$gt”: Greater than
“$gte”: Greater than equal to
“$lt”: Less than
“$lte”: Less than equal to
Lets see how this works.
5. findOne() :- To get a single document from a collection we use this function.
6. insert() :- This is used to insert documents in a collection.
Now lets check if we have been able to insert this document or not.
Notice that a unique id has been added to the document by default. The given id has to be unique or else there will be an error. To provide a user defined id use “_id”.
So, with that we come to the end of the discussion on the MongoDB. Hopefully it helped you understand the topic, for more information you can also watch the video tutorial attached down this blog. The blog is designed and prepared by Niharika Rai, Analytics Consultant, DexLab AnalyticsDexLab Analytics offers machine learning courses in Gurgaon. To keep on learning more, follow DexLab Analytics blog.
This is another blog added to the series of time series forecasting. In this particular blog I will be discussing about the basic concepts of ARIMA model.
So what is ARIMA?
ARIMA also known as Autoregressive Integrated Moving Average is a time series forecasting model that helps us predict the future values on the basis of the past values. This model predicts the future values on the basis of the data’s own lags and its lagged errors.
When a data does not reflect any seasonal changes and plus it does not have a pattern of random white noise or residual then an ARIMA model can be used for forecasting.
There are three parameters attributed to an ARIMA model p, q and d :-
p :- corresponds to the autoregressive part
q:- corresponds to the moving average part.
d:- corresponds to number of differencing required to make the data stationary.
In our previous blog we have already discussed in detail what is p and q but what we haven’t discussed is what is d and what is the meaning of differencing (a term missing in ARMA model).
Since AR is a linear regression model and works best when the independent variables are not correlated, differencing can be used to make the model stationary which is subtracting the previous value from the current value so that the prediction of any further values can be stabilized . In case the model is already stationary the value of d=0. Therefore “differencing is the minimum number of deductions required to make the model stationary”. The order of d depends on exactly when your model becomes stationary i.e. in case the autocorrelation is positive over 10 lags then we can do further differencing otherwise in case autocorrelation is very negative at the first lag then we have an over-differenced series.
The formula for the ARIMA model would be:-
To check if ARIMA model is suited for our dataset i.e. to check the stationary of the data we will apply Dickey Fuller test and depending on the results we will using differencing.
In my next blog I will be discussing about how to perform time series forecasting using ARIMA model manually and what is Dickey Fuller test and how to apply that, so just keep on following us for more.
So, with that we come to the end of the discussion on the ARIMA Model. Hopefully it helped you understand the topic, for more information you can also watch the video tutorial attached down this blog. The blog is designed and prepared by Niharika Rai, Analytics Consultant, DexLab AnalyticsDexLab Analytics offers machine learning courses in Gurgaon. To keep on learning more, follow DexLab Analytics blog.
Machine learning has become a popular term as this advanced technology is full of immense potential. Before explaining the intuition behind machine learning let’s understand the meaning of the term first which is becoming so popular in this era of scientific innovation and is a trend that everybody wants to follow.
What is Machine Learning?
Machine learning if explained in a very layman language is a program running behind an application which has an ability to learn from what is sees and the errors that it makes and then tries to improve itself through trial and error. A programming language like Python and a method of calculation (statistics) is what helps propel this application in the right direction.
Now that you know what machine learning is, let’s discuss about what is the intuition behind building a machine learning algorithm or a program.
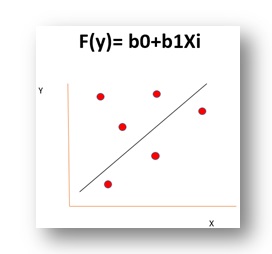
In my previous blog I have discussed about a statistical concept called Linear Regression which follows given a X independent variable, prediction of a Y dependent variable is possible if we understand the rate at which X and Y are changing and the direction towards which they are moving i.e. we understand the hidden pattern they are following, we will be able to predict the value of Y when X= 15.
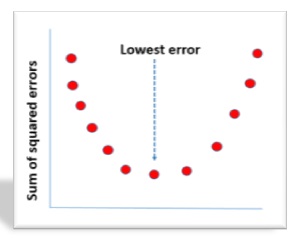
In the process of all that, we need to reduce the error between the predicted Y and the observed Y which we had to train our model but this is not possible with only calculating the slope i.e. b1 a single time and this is where machine learning comes in handy.
The idea behind machine learning is to learn from the past mistakes and try to find the best possible coefficients i.e. b0 and b1 so that we are able to reduce the distance between predicted and observed y which leads to the minimization of error in predictions which we are making. This intuition remains the same throughout all the machine learning algorithms only the problem in question and the methodology to solve the problem changes.
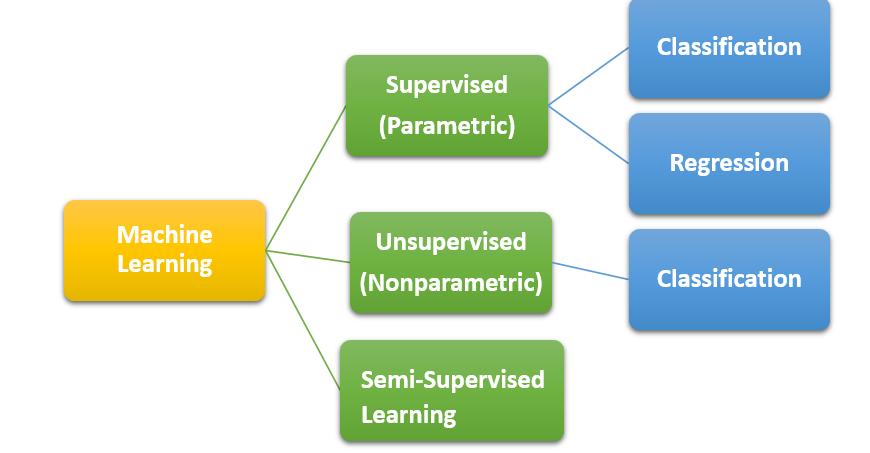
Now let’s quickly look at the branches of Machine Learning.
Branches of Machine Learning
Supervised (Parametric) Machine Learning Algorithm:- Under this branch both the independent variable X and the dependent variable Y is given in the form of Y = f(X) and this branch can further be divided based on the kind of problem we are dealing with i.e. whether the variable Y is continuous or a category.
Unsupervised (Non-parametric) Machine Learning Algorithm:- Under this branch you do not have the Y variable i.e. Y ≠ f(X) and you can only solve classification problems.
Semi-Supervised Machine Learning Algorithms:- This is the most difficult to solve as under this kind of problem the data which is available for the analysis has missing values of Y which makes it quite difficult to train the algorithm as the possibility of false prediction is very high.
So, with that this discussion here on machine learning wraps up, hopefully, it helped you understand the intuition behind machine learning, also check out the video tutorial attached down the blog to learn more. The field of machine learning is full of opportunities, DexLab Analytics offers machine learning course in delhi ncr, keep on following the blog to enhance your knowledge as we continue to update it with interesting and informative posts for you.
If you are aware of the growth opportunities awaiting you in the Machine Learning domain, you must be in a rush to master the Machine Learning skills. Now, there are courses available that aim to sharpen the students with skills they would need to work in a challenging environment. However, some often prefer the self-study mode for developing knowledge in this highly specialized domain. No matter which way you prefer to learn, ultimately your passion and dedication would matter the most, because in both ways you need to put in the hard work and really toil hard to make any progress.
Is self-study a feasible option?
If you have already been through some course and want to go to the advanced level through self-study that’s a different issue, but, for those who are just starting out without any background in science, does it even make any sense to opt for self-study?
Given the way Machine Learning technology is moving fast and creating a demand for professionals with highly specialized industry knowledge, do you think self-study would be enough? Do you think a self-study plan to learn something you have no idea about would work? How much time would you need to devote? What should be your learning route? And how do you know this is the right path to follow?
Before we dive deeper into the discussion, we need to go through some prerequisites for Machine Learning study plan.
Machine learning is a broad field and assuming you are a beginner with no prior knowledge in this domain, you have to be familiar with mathematics, statistics, programming languages, meaning undergoing a Python certification training</strong>, must be proficient in data handling including analysis and modeling, you have to work on algorithms. So, can you pick up all of these skills one by one via self-study? Add to the list the latest Machine Learning tools and applications you need to grasp.
There will be help available in the form of:
There would be vast resources, in forms of e-books, lectures, video tutorials, most of these are free and easily accessible.
There are forums, groups out there which you can join and access help
You can take part in online competitions
Think it through. How long will it take for you to get from one stage to the next?
Even though there being no dearth of resources available you would be struggling with your progress and most importantly you would struggle to keep up with the pace the technology is moving ahead. Picking up a programming language, grasping and mastering concepts of linear algebra, probability, data is going to be a mammoth task.
What difference a certification course can make?
To begin with these courses are designed for people coming from different backgrounds, so, you having or, not having any prior knowledge in mathematics, statistics wouldn’t matter as you would be taught everything from scratch be it math or, Machine Learning Using Python.
The programs are designed for both working professionals as well as for beginners, all you need to do is choose the one that suits your specific level.
These courses are designed to transform you into an industry-ready professional and you would be under the guidance of professionals who are more than familiar with the nuances of the way the industry functions.
The modules would follow a strict schedule and your training path would be well planned out covering all the areas you need to master.
You would learn via hands-on training and get to handle projects. Nothing makes you skilled like hands-on training.
Your journey towards a smarter future needs to be through a well mapped-out path, so, be smart about it. DexLab Analytics offers industry-ready courses on Data Science, Machine Learning course in Gurgaon and AI with Python. Take advantage of the courses that are taught by instructors who have both expertise and experience. Time is indeed money, so, stop wasting time and get down to learning.
Artificial Intelligence or, AI is an advanced technology that is busy taking the world in its strides. With virtual assistants, face recognition, NLP, object detection, data crunching becoming familiar terms it is no wonder that this dynamic technology is being integrated into the very fabric of our society. Almost every sector is now adopting AI technology, be it running business operations or, ensuring error-free diagnosis in the healthcare domain, the exponential growth of this technology is pushing the demand for skilled AI professionals who can monitor and manage the AI operations of an organization.
Since AI is an expansive term and branches off in multiple directions, the job opportunities available in this field are also diverse. According to recent studies, AI jobs are going to be the most in-demand jobs in the near future. Multiple job roles are available that come with specific job responsibilities. So, let’s have a look at some of these.
Machine Learning Engineer
An machine learning engineer is supposed to be one of the most in-demand jobs available in this field, the basic job of an ML engineer center round working on self-running software, and they need to work with a huge pile of data. In an organization, the machine learning engineers need to collaborate with data scientists and ensure that real-time data is being put to use for churning out accurate results. They need to work with data science models and develop algorithms that can process the data and offer insight. Mostly their job responsibility revolves around working with current machine learning frameworks and working on it to make it better. Re-training machine learning models is another significant responsibility they need to shoulder.
If recent statistics are to be believed the salary of a machine learning hovers around ₹681,881 in India.
Artificial Intelligence Engineer
AI engineers are indeed a specialized breed of professionals who are in charge of AI infrastructure and work on AI models. They work on designing models and then test and finally, they need to deploy these models. Automating functionalities is also important and most importantly they must understand the key problems that need AI solutions. AI engineers need to write programs, so they need to be familiar with several programming languages, having a background in Machine Learning Using Python could be a big help. Another important responsibility is creating smart AI algorithms for developing an AI system, as per the specific requirement that needs to be solved using that system.
In India, an AI engineer could expect the salary to be around ₹7,86,105 per year, as per Glassdoor figures.
Data Scientist
A data scientist is going to be in charge of the data science team and need to work on the huge volumes of data to analyze and extract information, build and combine models and employ machine learning, data mining, techniques along with utilizing numerous tools including visualization tools to help an organization reach its business goals. The data scientists need to work with raw data and he needs to be in charge of automating the collection procedure and most importantly they need to process and prepare data for further analysis, and present the insight to the stakeholders.
A data scientist could earn around ₹ 7,41,962 per year in India as per the numbers found on Indeed.
AI Architect
An AI architect needs to work with the AI architecture and assess the current status in order to ensure that the solutions are fulfilling the current requirements and would be ready to scale up to adapt to the changing set of requirements that would arise in the future. They must be familiar with the current AI framework that they need to employ to develop an AI infrastructure that is sustainable. Along with working with a large amount of data, an AI architect must be employing machine learning algorithms and posses a thorough knowledge of the product development, and suggest suitable applications and solutions.
In India an AI architect could expect to make around ₹3,567K per year as per Glassdoor statistics is concerned.
There are so many job opportunities available in the AI domain, and here only a few job roles have been described. There are plenty more diverse job opportunities await you out there, grab those, just get artificial intelligence certification in delhi ncr and be future-ready.
Today’s workspace has turned volatile in trying to adjust to the new normal. Along with struggling to stay indoors while living a virtual life, adopting new manners of social distancing, people are also having to deal with issues like job loss, pay cut, or, worse, lack of vacancies. Different sectors are getting hit, except for those driven by cutting edge technology like Data Science, Artificial intelligence. The need to transition into a digital world is greater than ever. As per the World Economic Forum, there would be a greater push towards “digitization” as well as “automation”. This signifies the need for professionals with a background in Data Science, Artificial Intelligence in the future that is going to be entirely data-reliant.
So, what are you going to do? Sit back and wait till the storm passes over or are you going to utilize this downtime to upskill yourself with a Data Science course? With the PM stressing on how the “skill, re-skill and upskill” being the need of the hour, you can hardly afford to lose more time. Since Data Science is one of the comparatively steadier fields, that is growing despite all odds, it is time to acquire data literacy to stay relevant in a workspace that is increasingly becoming data-driven. From healthcare to manufacturing, different sectors are busy decoding the data in hand to go digital in a pandemic ridden world, and employers are looking for people who are willing to push the envelope harder to remain relevant.
What is data literacy?
Before progressing, you must understand what data literacy even means. Data literacy basically refers to having an in-depth knowledge of data that helps the employees work with data to derive actionable information from it and channelizing that to make informed decisions. However, data literacy has a wider meaning and it is not limited to the data team comprising data scientists, no, it takes all the employees in its ambit, so, that the data flow throughout the organization is seamless. Without there being employees who know their way around data, an organization can never realize its dream of initiating a data-driven culture. Having a background in Data science using Python training is the key to achieving data literacy.
The demand for data scientists and data analysts is soaring up
Despite the ominous presence of the pandemic, the demand for Data Science professionals is there and in August, the demand for Data Analysts and Data Scientists soared. As per a recent study, in India, a Data Science professional can expect no less than ₹9.5 lakh per annum. With prestigious institutes like Infosys, IBM India, Cognizant Technology Solutions, Accenture hiring, it is now absolutely mandatory to undergo Data Science training to grab the job opportunities.
Getting Data Science certification can help you close the gap
The skill gap is there, but, that does not mean it could not be taken care of. On the contrary, it is absolutely possible and imperative that you take the necessary step of upskilling yourself to be ready for the Data Science field. Having a working knowledge of data is not enough, you must be familiar with the latest Data Science tools, must possess the knowledge to work with different models, must be familiar with data extraction, data manipulation. All of these skills and more, you would need to master before you go seeking a well-paying job.
Self-study might seem like a tempting idea, but, it is not a practical solution, if you want to be industry-ready then you must know what the industry is expecting from a Data Science professional, and only a faculty comprising industry experts can give you that knowledge while guiding you through a well designed Python for data science training course.
An institute such as DexLab Analytics understands the need of the hour and has a great team of industry professionals and experts to help aspiring Data Scientists and Data Analysts fulfill their dream. Along with offering state-of-the-art Data Science certification courses, they also provide courses like Machine Learning Using Python.
No matter which way you look, upskilling is the need of the hour as the world is busy embracing the power of Data Science. Stop procrastinating and get ready for the future.
The world has finally woken up and smelled the power of data science and now we are living in a world that is being driven by data. There is no denying the fact that new technologies are coming to the fore that are born out of data-driven insight and numerous sectors are also turning towards data science techniques and tools to increase their operational efficiency.
This in turn is also pushing a demand for skilled people in various sectors who are armed with Data Science course or, Retail Analytics Courses to be able to sift through mountains of data to clean it, sort it and analyze it for uncovering valuable information. Decisions that were earlier taken often on the basis of erroneous data or, assumption can now be more accurate thanks to application of data science.
Now let’s take a look at which sectors are benefitting the most from data science
Healthcare
The healthcare industry has adopted the data science techniques and the benefits could already be perceived. Keeping track of healthcare records is easier not just that but digging through the pile of patient data and its analysis actually helps in giving hint regarding health issues that might crop up in near future. Preventive care is now possible and also monitoring patient health is easier than ever before.
The development in the field can also predict which medication would be suitable for a particular patient. Data analytics and data science application is also enabling the professionals in this sector to offer better diagnostic results.
Retail
This is one industry that is reaping huge benefits from the application of data science. Now sorting through the customer data, survey data it is easier to gauge the customers’ mindset. Predictive analysis is helping the experts in this field to predict the personal preference of the consumers and they are able to come up with personalized recommendations that is bound to help them retain customers. Not just that they can also find the problem areas in their current marketing strategy to make changes accordingly.
Transport
Transport is another sector that is using data science techniques to its advantage and in turn it is increasing its service quality. Both the public and private transportation services providers are keeping track of customer journey and getting the details necessary to develop personalized information, they are also helping people be prepared for unexpected issues and most importantly they are helping people reach their destinations without any glitch.
Finance
If so many industries are reaping benefits, Finance is definitely to follow suit. Dealing with valuable data regarding banking transactions, credit history is essential. Based on the data insight it is possible to offer customers personalized financial advice. Also the credit risk issue could be minimized thanks to the insight derived from a particular customer’s credit history. It would allow the financial institute make an informed decision. However, credit risk analytics training would be required for personnel working in this field.
Telecom
The field of telecom is surely a busy sector that has to deal with tons of valuable data. With the application of data science now they are able to find a smart solution to process the data they gather from various call records, messages, social media platforms in order to design and deliver services that are in accordance with customers’ individualistic needs.
Harnessing the power of data science is definitely going to impact all the industries in future. The data science domain is expanding and soon there would be more miracles to observe. Data Science training can help upskill the employees reduce the skill gap that is bugging most sectors.
The job of a data scientist is one that is challenging, exciting and crucial to an organization’s success. So, it’s no surprise that there is a rush to enroll in a Data Science course, to be eligible for the job. But, while you are at it, you also need to have the awareness regarding the job responsibilities usually bestowed upon the data scientists in a business organization and you would be surprised to learn that the responsibilities of a data scientist differs from that of a data analyst or, a data engineer.
So, what is the role and responsibility of a data scientist? Let’s take a look.
The common idea regarding a data scientist role is that they analyze huge volumes of data in order to find patterns and extract information that would help the organizations to move ahead by developing strategies accordingly. This surface level idea cannot sum up the way a data scientist navigates through the data field. The responsibilities could be broken down into segments and that would help you get the bigger picture.
Data management
The data scientist, post assuming the role, needs to be aware of the goal of the organization in order to proceed. He needs to stay aware of the top trends in the industry to guide his organization, and collect data and also decide which methods are to be used for the purpose. The most crucial part of the job is the developing the knowledge of the problems the business is trying solve and the data available that have relevance and could be used to achieve the goal. He has to collaborate with other departments such as analytics to get the job of extracting information from data.
Data analysis
Another vital responsibility of the data scientist is to assume the analytical role and build models and implement those models to solve issues that are best fit for the purpose. The data scientist has to resort to data mining, text mining techniques. Doing text mining with python course can really put you in an advantageous position when you actually get to handle complex dataset.
Developing strategies
The data scientists need to devote themselves to tasks like data cleaning, applying models, and wade through unstructured datasets to derive actionable insight in order to gauge the customer behavior, market trends. These insights help a business organization to decide its future course of action and also measure a product performance. A Data analyst training institute is the right place to pick up the skills required for performing such nuanced tasks.
Collaborating
Another vital task that a data scientist performs is collaborating with others such as stakeholders and data engineers, data analysts communicating with them in order to share their findings or, discussing certain issues. However, in order to communicate effectively the data scientists need to master the art of data visualization which they could learn while pursuing big data courses in delhi along with deep learning for computer vision course. The key issue here is to make the presentation simple yet effective enough so that people from any background can understand it.
The above mentioned responsibilities of a data scientist just scratch the surface because, a data scientist’s job role cannot be limited by or, defined by a couple of tasks. The data scientist needs to be in synch with the implementation process to understand and analyze further how the data driven insight is shaping strategies and to which effect. Most importantly, they need to evaluate the current data infrastructure of the company and advise regarding future improvement. A data scientist needs to have a keen knowledge of Machine Learning Using Python, to be able to perform the complex tasks their job demands.