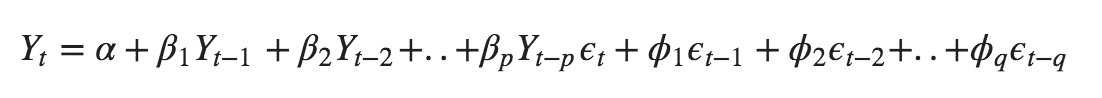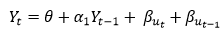In our previous blog we discussed about few of the basic functions of MQL like .find() , .count() , .pretty() etc. and in this blog we will continue to do the same. At the end of the blog there is a quiz for you to solve, feel free to test your knowledge and wisdom you have gained so far.
Given below is the list of functions that can be used for data wrangling:-
updateOne() :- This function is used to change the current value of a field in a single document.
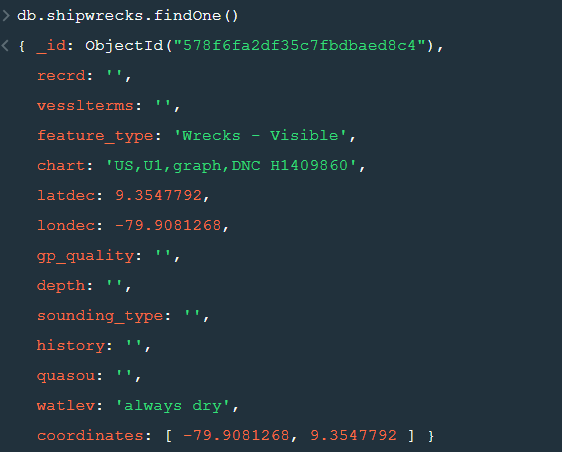
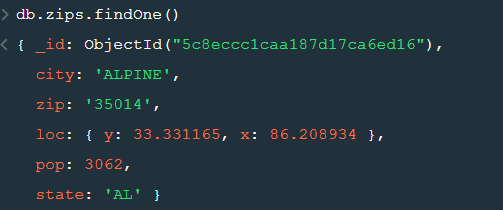
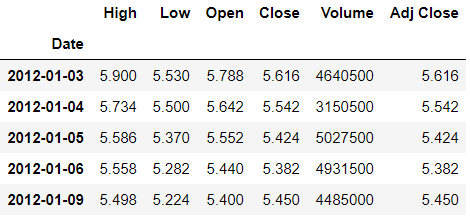
After changing the database to “sample_geospatial” we want to see what the document looks like? So for that we will use .findOne() function.
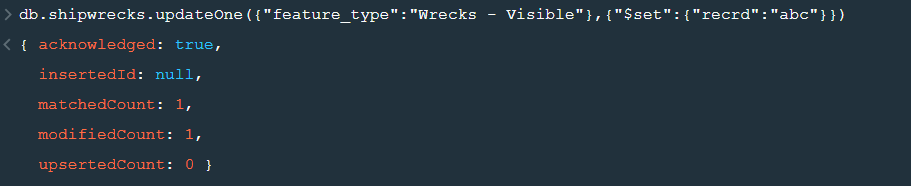
Now lets update the field value of “recrd” from ‘ ’ to “abc” where the “feature_type” is ‘Wrecks-Visible’.
Now within the .updateOne() funtion any thing in the first part of { } is the condition on the basis of which we want to update the given document and the second part is the changes which we want to make. Here we are saying that set the value as “abc” in the “recrd” field . In case you wanted to increase the value by a certain number ( assuming that the value is integer or float) you can use “$inc” instead.
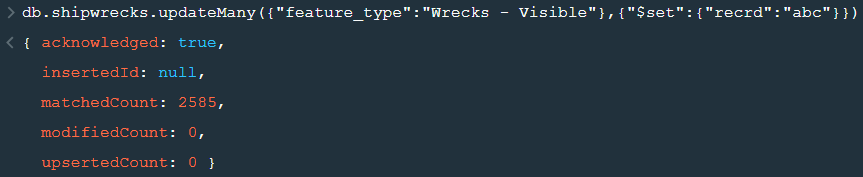
2. updateMany() :- This function updates many documents at once based on the condition provided.
3. deleteOne() & deleteMany() :- These functions are used to delete one or many documents based on the given condition or field.
4. Logical Operators :-
“$and” : It is used to match all the conditions.
“$or” : It is used to match any of the conditions.
The first code matches both the conditions i.e. name should be “Wetpaint” and “category_code” should be “web”, whereas the second code matches any one of the conditions i.e. either name should be “Wetpaint” or “Facebook”. Try these codes and see the difference by yourself.
So, with that we come to the end of the discussion on the MongoDB Basics. Hopefully it helped you understand the topic, for more information you can also watch the video tutorial attached down this blog. The blog is designed and prepared by Niharika Rai, Analytics Consultant, DexLab AnalyticsDexLab Analytics offers machine learning courses in Gurgaon. To keep on learning more, follow DexLab Analytics blog.
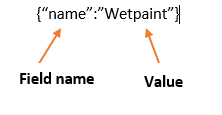
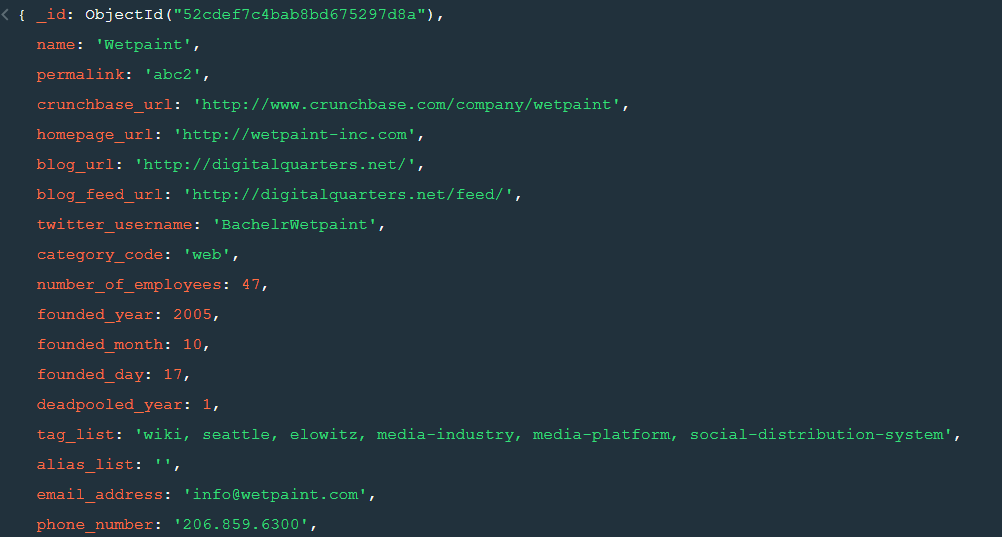
MongoDB is a document based database program which was developed by MongoDB Inc. and is licensed under server side public license (SSPL). It can be used across platforms and is a non-relational database also known as NoSQL, where NoSQL means that the data is not stored in the conventional tabular format and is used for unstructured data as compared to SQL and that is the major difference between NoSQL and SQL. MongoDB stores document in JSON or BSON format. JSON also known as JavaScript Object notation is a format where data is stored in a key value pair or array format which is readable for a normal human being whereas BSON is nothing but the JSON file encoded in the binary format which is quite hard for a human being to understand. Structure of MongoDB which uses a query language MQL(Mongodb query language):- Databases:- Databases is a group of collections. Collections:- Collection is a group fields. Fields:- Fields are nothing but key value pairs Just for an example look at the image given below:-
Here I am using MongoDB Compass a tool to connect to Atlas which is a cloud based platform which can help us write our queries and start performing all sort of data extraction and deployment techniques. You can download MongoDB Compass via the given link https://www.mongodb.com/try/download/compass
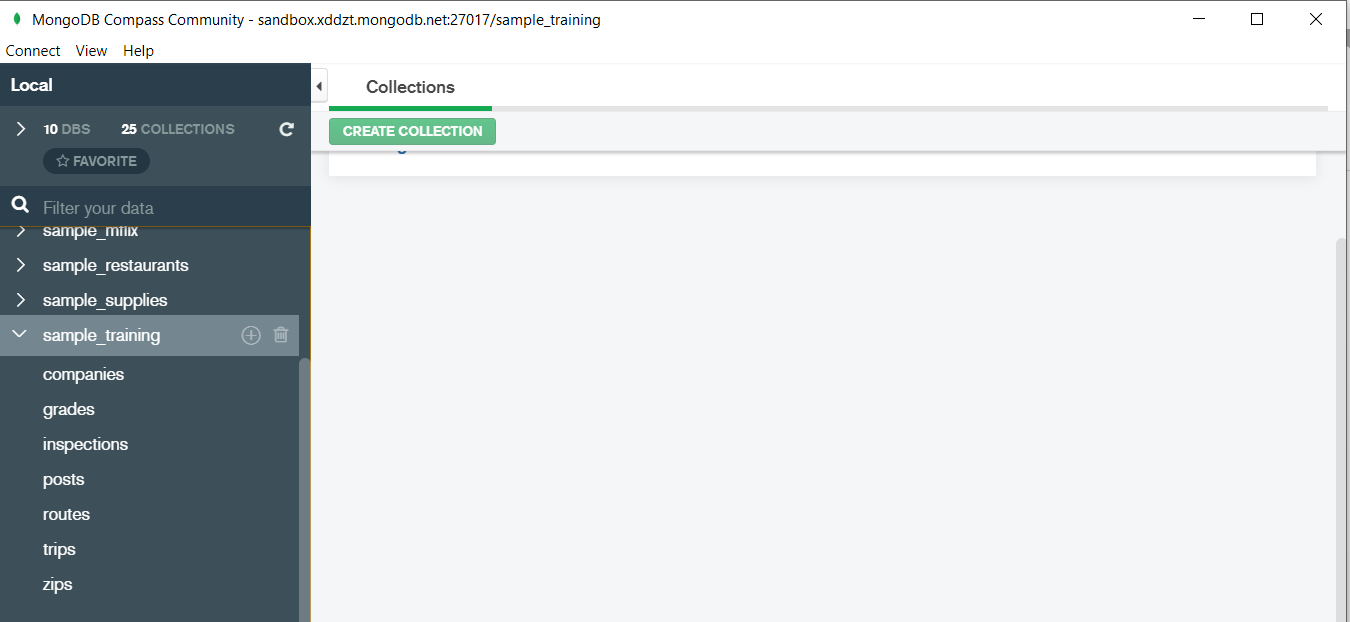
In the above image in the red box we have our databases and if we click on the “sample_training” database we will see a list of collections similar to the tables in sql.
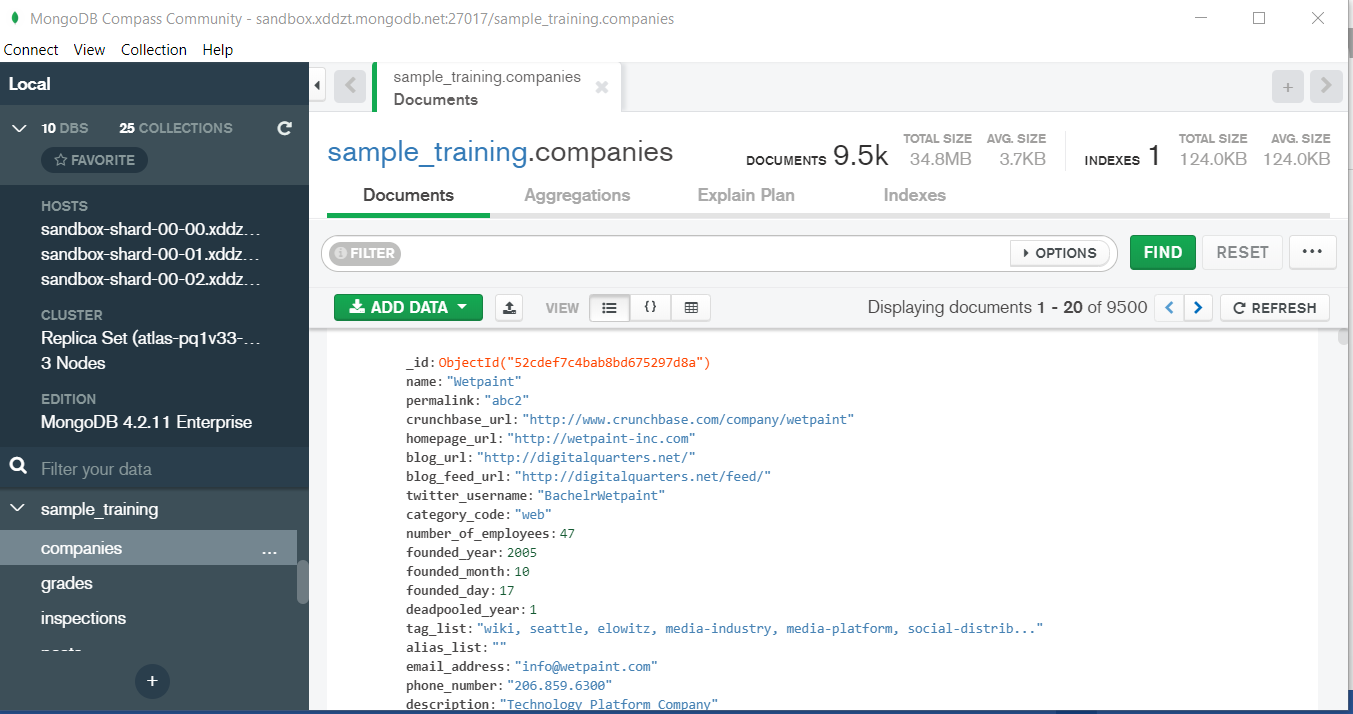
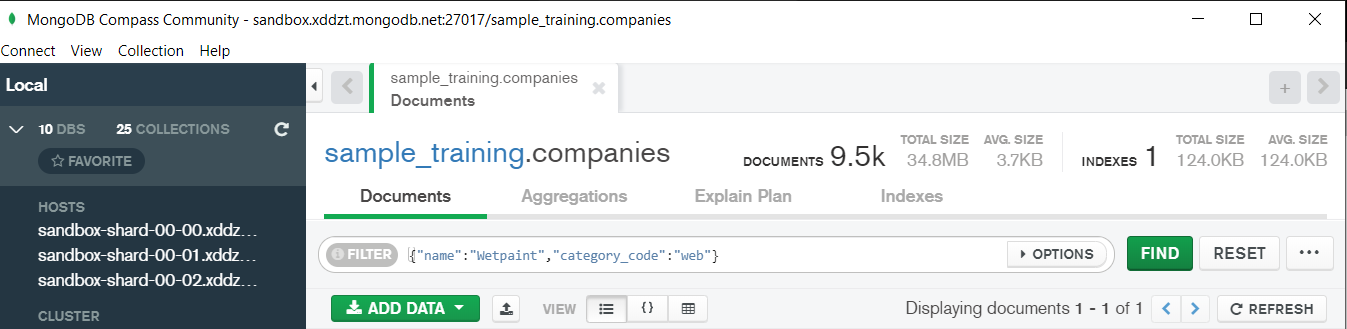
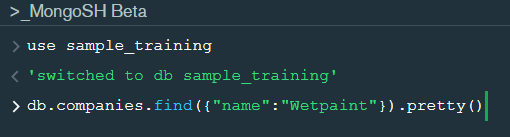
Now lets write our first query and see what data in “companies” collection looks like but before that select the “companies” collection.
Now in our filter cell we can write the following query:-
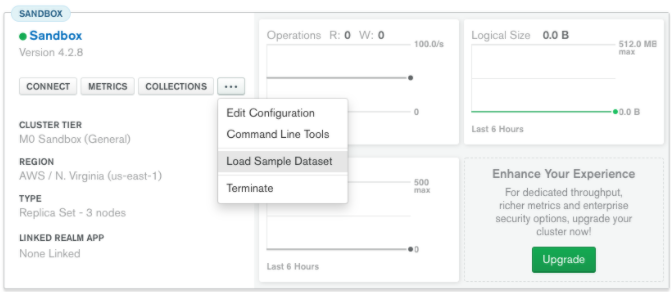
In the above query “name” and “category_code” are the key values also known as fields and “Wetpaint” and “web” are the pair values on the basis of which we want to filter the data. What is cluster and how to create it on Atlas? MongoDB cluster also know as sharded cluster is created where each collection is divided into shards (small portions of the original data) which is a replica set of the original collection. In case you want to use Atlas there is an unpaid version available with approximately 512 mb space which is free to use. There is a pre-existing cluster in MongoDB named Sandbox , which currently I am using and you can use it too by following the given steps:- 1. Create a free account or sign in using your Google account on https://www.mongodb.com/cloud/atlas/lp/try2-in?utm_source=google&utm_campaign=gs_apac_india_search_brand_atlas_desktop&utm_term=mongodb%20atlas&utm_medium=cpc_paid_search&utm_ad=e&utm_ad_campaign_id=6501677905&gclid=CjwKCAiAr6-ABhAfEiwADO4sfaMDS6YRyBKaciG97RoCgBimOEq9jU2E5N4Jc4ErkuJXYcVpPd47-xoCkL8QAvD_BwE 2. Click on “Create an Organization”. 3. Write the organization name “MDBU”. 4. Click on “Create Organization”. 5. Click on “New Project”. 6. Name your project M001 and click “Next”. 7. Click on “Build a Cluster”. 8. Click on “Create a Cluster” an option under which free is written. 9. Click on the region closest to you and at the bottom change the name of the cluster to “Sandbox”. 10. Now click on connect and click on “Allow access from anywhere”. 11. Create a Database User and then click on “Create Database User”. username: m001-student password: m001-mongodb-basics 12. Click on “Close” and now load your sample as given below :
Loading may take a while…. 13. Click on collections once the sample is loaded and now you can start using the filter option in a similar way as in MongoDB Compass In my next blog I’ll be sharing with you how to connect Atlas with MongoDB Compass and we will also learn few ways in which we can write query using MQL.
So, with that we come to the end of the discussion on the MongoDB. Hopefully it helped you understand the topic, for more information you can also watch the video tutorial attached down this blog. The blog is designed and prepared by Niharika Rai, Analytics Consultant, DexLab AnalyticsDexLab Analytics offers machine learning courses in Gurgaon. To keep on learning more, follow DexLab Analytics blog.
In this particular blog we will discuss about few of the basic functions of MQL (MongoDB Query Language) and we will also see how to use them? We will be using MongoDB Compass shell (MongoSH Beta) which is available in the latest version of MongoDB Compass.
Connect your Atlas cluster to your MongoDB Compass to get started. Latest version of MongoDB Compass will have this shell, so if you don’t find this shell then please install the latest version for this to work.
Now lets start with the functions.
find() :- You need this function for data extraction in the shell.
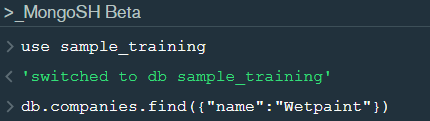
In the shell we need to first write the “use database name” code to access the database then use .find() to extract data which has name “Wetpaint”
For the above query we get the following result:-
The above result brings us to another function .pretty() .
2. pretty() :- this function helps us see the result more clearly.
Try it yourself to compare the results.
3. count() :- Now lets see how many entries we have by the company name “Wetpaint”.
So we have only one document.
4. Comparison operators :-
“$eq” : Equal to
“$neq”: Not equal to
“$gt”: Greater than
“$gte”: Greater than equal to
“$lt”: Less than
“$lte”: Less than equal to
Lets see how this works.
5. findOne() :- To get a single document from a collection we use this function.
6. insert() :- This is used to insert documents in a collection.
Now lets check if we have been able to insert this document or not.
Notice that a unique id has been added to the document by default. The given id has to be unique or else there will be an error. To provide a user defined id use “_id”.
So, with that we come to the end of the discussion on the MongoDB. Hopefully it helped you understand the topic, for more information you can also watch the video tutorial attached down this blog. The blog is designed and prepared by Niharika Rai, Analytics Consultant, DexLab AnalyticsDexLab Analytics offers machine learning courses in Gurgaon. To keep on learning more, follow DexLab Analytics blog.
This is another blog added to the series of time series forecasting. In this particular blog I will be discussing about the basic concepts of ARIMA model.
So what is ARIMA?
ARIMA also known as Autoregressive Integrated Moving Average is a time series forecasting model that helps us predict the future values on the basis of the past values. This model predicts the future values on the basis of the data’s own lags and its lagged errors.
When a data does not reflect any seasonal changes and plus it does not have a pattern of random white noise or residual then an ARIMA model can be used for forecasting.
There are three parameters attributed to an ARIMA model p, q and d :-
p :- corresponds to the autoregressive part
q:- corresponds to the moving average part.
d:- corresponds to number of differencing required to make the data stationary.
In our previous blog we have already discussed in detail what is p and q but what we haven’t discussed is what is d and what is the meaning of differencing (a term missing in ARMA model).
Since AR is a linear regression model and works best when the independent variables are not correlated, differencing can be used to make the model stationary which is subtracting the previous value from the current value so that the prediction of any further values can be stabilized . In case the model is already stationary the value of d=0. Therefore “differencing is the minimum number of deductions required to make the model stationary”. The order of d depends on exactly when your model becomes stationary i.e. in case the autocorrelation is positive over 10 lags then we can do further differencing otherwise in case autocorrelation is very negative at the first lag then we have an over-differenced series.
The formula for the ARIMA model would be:-
To check if ARIMA model is suited for our dataset i.e. to check the stationary of the data we will apply Dickey Fuller test and depending on the results we will using differencing.
In my next blog I will be discussing about how to perform time series forecasting using ARIMA model manually and what is Dickey Fuller test and how to apply that, so just keep on following us for more.
So, with that we come to the end of the discussion on the ARIMA Model. Hopefully it helped you understand the topic, for more information you can also watch the video tutorial attached down this blog. The blog is designed and prepared by Niharika Rai, Analytics Consultant, DexLab AnalyticsDexLab Analytics offers machine learning courses in Gurgaon. To keep on learning more, follow DexLab Analytics blog.
ARMA(p,q) model in time series forecasting is a combination of Autoregressive Process also known as AR Process and Moving Average (MA) Process where p corresponds to the autoregressive part and q corresponds to the moving average part.
Autoregressive Process (AR) :- When the value of Yt in a time series data is regressed over its own past value then it is called an autoregressive process where p is the order of lag into consideration.
Where,
Yt = observation which we need to find out.
α1= parameter of an autoregressive model
Yt-1= observation in the previous period
ut= error term
The equation above follows the first order of autoregressive process or AR(1) and the value of p is 1. Hence the value of Yt in the period ‘t’ depends upon its previous year value and a random term.
Moving Average (MA) Process :- When the value of Yt of order q in a time series data depends on the weighted sum of current and the q recent errors i.e. a linear combination of error terms then it is called a moving average process which can be written as :-
yt = observation which we need to find out
α= constant term
βut-q= error over the period q .
ARMA (Autoregressive Moving Average) Process :-
The above equation shows that value of Y in time period ‘t’ can be derived by taking into consideration the order of lag p which in the above case is 1 i.e. previous year’s observation and the weighted average of the error term over a period of time q which in case of the above equation is 1.
How to decide the value of p and q?
Two of the most important methods to obtain the best possible values of p and q are ACF and PACF plots.
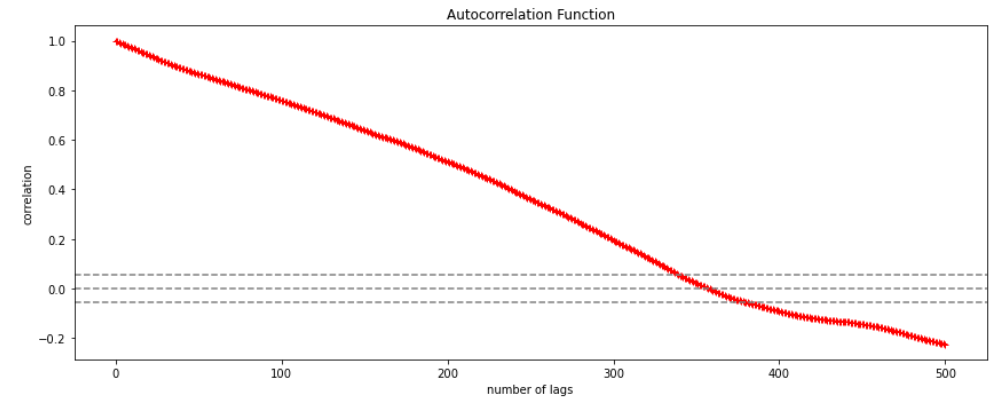
ACF (Auto-correlation function) :- This function calculates the auto-correlation of the complete data on the basis of lagged values which when plotted helps us choose the value of q that is to be considered to find the value of Yt. In simple words how many years residual can help us predict the value of Yt can obtained with the help of ACF, if the value of correlation is above a certain point then that amount of lagged values can be used to predict Yt.
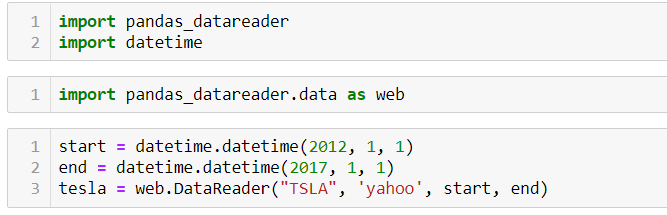
Using the stock price of tesla between the years 2012 and 2017 we can use the .acf() method in python to obtain the value of p.
.DataReader() method is used to extract the data from web.
The above graph shows that beyond the lag 350 the correlation moved towards 0 and then negative.
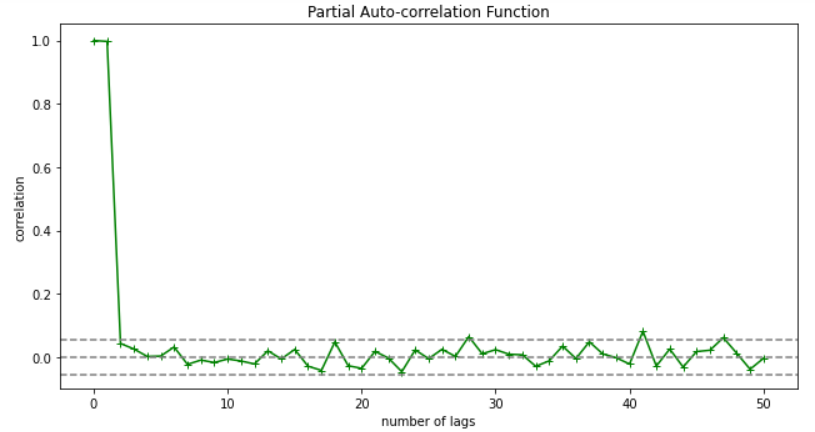
PACF (Partial auto-correlation function) :- Pacf helps find the direct effect of the past lag by removing the residual effect of the lags in between. Pacf helps in obtaining the value of AR where as acf helps in obtaining the value of MA i.e. q. Both the methods together can be use find the optimum value of p and q in a time series data set.
Lets check out how to apply pacf in python.
As you can see in the above graph after the second lag the line moved within the confidence band therefore the value of p will be 2.
So, with that we come to the end of the discussion on the ARMA Model. Hopefully it helped you understand the topic, for more information you can also watch the video tutorial attached down this blog. The blog is designed and prepared by Niharika Rai, Analytics Consultant, DexLab AnalyticsDexLab Analytics offers machine learning courses in Gurgaon. To keep on learning more, follow DexLab Analytics blog.
Data Smoothing is done to better understand the hidden patterns in the data. In the non- stationary processes, it is very hard to forecast the data as the variance over a period of time changes, therefore data smoothing techniques are used to smooth out the irregular roughness to see a clearer signal.
In this segment we will be discussing two of the most important data smoothing techniques :-
Moving average smoothing
Exponential smoothing
Moving average smoothing
Moving average is a technique where subsets of original data are created and then average of each subset is taken to smooth out the data and find the value in between each subset which better helps to see the trend over a period of time.
Lets take an example to better understand the problem.
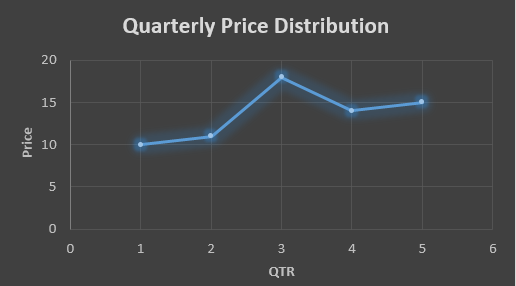
Suppose that we have a data of price observed over a period of time and it is a non-stationary data so that the tend is hard to recognize.
QTR (quarter)
Price
1
10
2
11
3
18
4
14
5
15
6
?
In the above data we don’t know the value of the 6th quarter.
….fig (1)
The plot above shows that there is no trend the data is following so to better understand the pattern we calculate the moving average over three quarter at a time so that we get in between values as well as we get the missing value of the 6th quarter.
To find the missing value of 6th quarter we will use previous three quarter’s data i.e.
MAS = = 15.7
QTR (quarter)
Price
1
10
2
11
3
18
4
14
5
15
6
15.7
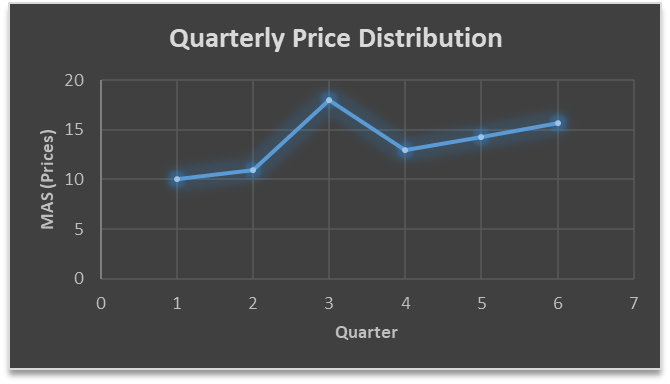
MAS = = 13
MAS = = 14.33
QTR (quarter)
Price
MAS (Price)
1
10
10
2
11
11
3
18
18
4
14
13
5
15
14.33
6
15.7
15.7
….. fig (2)
In the above graph we can see that after 3rd quarter there is an upward sloping trend in the data.
Exponential Data Smoothing
In this method a larger weight ( ) which lies between 0 & 1 is given to the most recent observations and as the observation grows more distant the weight decreases exponentially.
The weights are decided on the basis how the data is, in case the data has low movement then we will choose the value of closer to 0 and in case the data has a lot more randomness then in that case we would like to choose the value of closer to 1.
EMA= Ft= Ft-1 + (At-1 – Ft-1)
Now lets see a practical example.
For this example we will be taking = 0.5
Taking the same data……
QTR (quarter)
Price
(At)
EMS Price(Ft)
1
10
10
2
11
?
3
18
?
4
14
?
5
15
?
6
?
?
To find the value of yellow cell we need to find out the value of all the blue cells and since we do not have the initial value of F1 we will use the value of A1. Now lets do the calculation:-
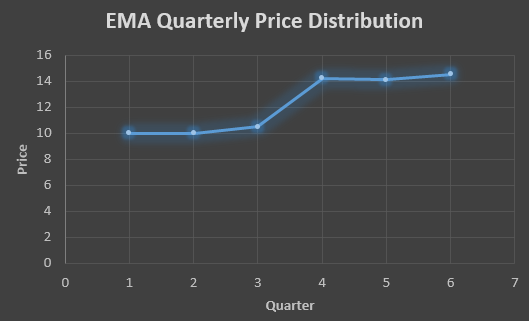
F2=10+0.5(10 – 10) = 10
F3=10+0.5(11 – 10) = 10.5
F4=10.5+0.5(18 – 10.5) = 14.25
F5=14.25+0.5(14 – 14.25) = 14.13
F6=14.13+0.5(15 – 14.13)= 14.56
QTR (quarter)
Price
(At)
EMS Price(Ft)
1
10
10
2
11
10
3
18
10.5
4
14
14.25
5
15
14.13
6
14.56
14.56
In the above graph we see that there is a trend now where the data is moving in the upward direction.
So, with that we come to the end of the discussion on the Data smoothing method. Hopefully it helped you understand the topic, for more information you can also watch the video tutorial attached down this blog. The blog is designed and prepared by Niharika Rai, Analytics Consultant, DexLab AnalyticsDexLab Analytics offers machine learning courses in Gurgaon. To keep on learning more, follow DexLab Analytics blog.
Machine learning has become a popular term as this advanced technology is full of immense potential. Before explaining the intuition behind machine learning let’s understand the meaning of the term first which is becoming so popular in this era of scientific innovation and is a trend that everybody wants to follow.
What is Machine Learning?
Machine learning if explained in a very layman language is a program running behind an application which has an ability to learn from what is sees and the errors that it makes and then tries to improve itself through trial and error. A programming language like Python and a method of calculation (statistics) is what helps propel this application in the right direction.
Now that you know what machine learning is, let’s discuss about what is the intuition behind building a machine learning algorithm or a program.
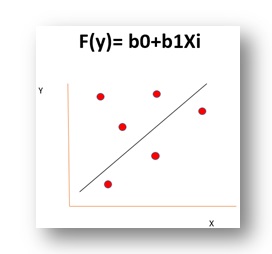
In my previous blog I have discussed about a statistical concept called Linear Regression which follows given a X independent variable, prediction of a Y dependent variable is possible if we understand the rate at which X and Y are changing and the direction towards which they are moving i.e. we understand the hidden pattern they are following, we will be able to predict the value of Y when X= 15.
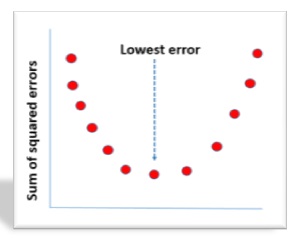
In the process of all that, we need to reduce the error between the predicted Y and the observed Y which we had to train our model but this is not possible with only calculating the slope i.e. b1 a single time and this is where machine learning comes in handy.
The idea behind machine learning is to learn from the past mistakes and try to find the best possible coefficients i.e. b0 and b1 so that we are able to reduce the distance between predicted and observed y which leads to the minimization of error in predictions which we are making. This intuition remains the same throughout all the machine learning algorithms only the problem in question and the methodology to solve the problem changes.
Now let’s quickly look at the branches of Machine Learning.
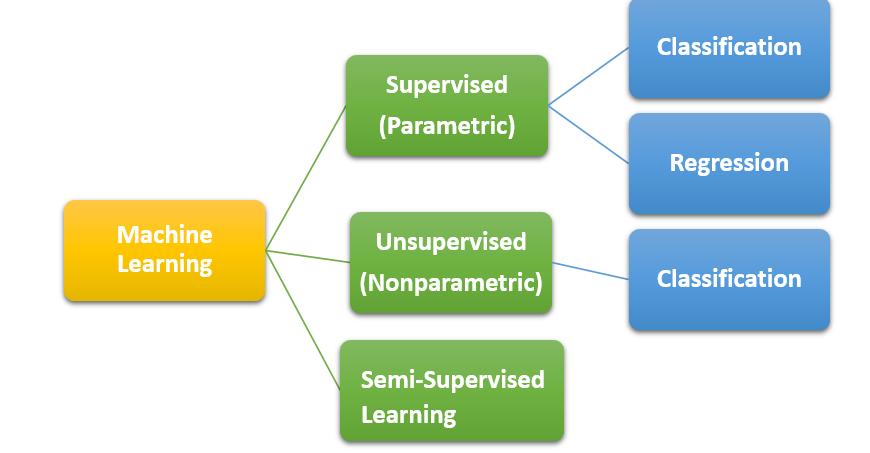
Branches of Machine Learning
Supervised (Parametric) Machine Learning Algorithm:- Under this branch both the independent variable X and the dependent variable Y is given in the form of Y = f(X) and this branch can further be divided based on the kind of problem we are dealing with i.e. whether the variable Y is continuous or a category.
Unsupervised (Non-parametric) Machine Learning Algorithm:- Under this branch you do not have the Y variable i.e. Y ≠ f(X) and you can only solve classification problems.
Semi-Supervised Machine Learning Algorithms:- This is the most difficult to solve as under this kind of problem the data which is available for the analysis has missing values of Y which makes it quite difficult to train the algorithm as the possibility of false prediction is very high.
So, with that this discussion here on machine learning wraps up, hopefully, it helped you understand the intuition behind machine learning, also check out the video tutorial attached down the blog to learn more. The field of machine learning is full of opportunities, DexLab Analytics offers machine learning course in delhi ncr, keep on following the blog to enhance your knowledge as we continue to update it with interesting and informative posts for you.
If you are aware of the growth opportunities awaiting you in the Machine Learning domain, you must be in a rush to master the Machine Learning skills. Now, there are courses available that aim to sharpen the students with skills they would need to work in a challenging environment. However, some often prefer the self-study mode for developing knowledge in this highly specialized domain. No matter which way you prefer to learn, ultimately your passion and dedication would matter the most, because in both ways you need to put in the hard work and really toil hard to make any progress.
Is self-study a feasible option?
If you have already been through some course and want to go to the advanced level through self-study that’s a different issue, but, for those who are just starting out without any background in science, does it even make any sense to opt for self-study?
Given the way Machine Learning technology is moving fast and creating a demand for professionals with highly specialized industry knowledge, do you think self-study would be enough? Do you think a self-study plan to learn something you have no idea about would work? How much time would you need to devote? What should be your learning route? And how do you know this is the right path to follow?
Before we dive deeper into the discussion, we need to go through some prerequisites for Machine Learning study plan.
Machine learning is a broad field and assuming you are a beginner with no prior knowledge in this domain, you have to be familiar with mathematics, statistics, programming languages, meaning undergoing a Python certification training</strong>, must be proficient in data handling including analysis and modeling, you have to work on algorithms. So, can you pick up all of these skills one by one via self-study? Add to the list the latest Machine Learning tools and applications you need to grasp.
There will be help available in the form of:
There would be vast resources, in forms of e-books, lectures, video tutorials, most of these are free and easily accessible.
There are forums, groups out there which you can join and access help
You can take part in online competitions
Think it through. How long will it take for you to get from one stage to the next?
Even though there being no dearth of resources available you would be struggling with your progress and most importantly you would struggle to keep up with the pace the technology is moving ahead. Picking up a programming language, grasping and mastering concepts of linear algebra, probability, data is going to be a mammoth task.
What difference a certification course can make?
To begin with these courses are designed for people coming from different backgrounds, so, you having or, not having any prior knowledge in mathematics, statistics wouldn’t matter as you would be taught everything from scratch be it math or, Machine Learning Using Python.
The programs are designed for both working professionals as well as for beginners, all you need to do is choose the one that suits your specific level.
These courses are designed to transform you into an industry-ready professional and you would be under the guidance of professionals who are more than familiar with the nuances of the way the industry functions.
The modules would follow a strict schedule and your training path would be well planned out covering all the areas you need to master.
You would learn via hands-on training and get to handle projects. Nothing makes you skilled like hands-on training.
Your journey towards a smarter future needs to be through a well mapped-out path, so, be smart about it. DexLab Analytics offers industry-ready courses on Data Science, Machine Learning course in Gurgaon and AI with Python. Take advantage of the courses that are taught by instructors who have both expertise and experience. Time is indeed money, so, stop wasting time and get down to learning.
Artificial Intelligence or, AI is an advanced technology that is busy taking the world in its strides. With virtual assistants, face recognition, NLP, object detection, data crunching becoming familiar terms it is no wonder that this dynamic technology is being integrated into the very fabric of our society. Almost every sector is now adopting AI technology, be it running business operations or, ensuring error-free diagnosis in the healthcare domain, the exponential growth of this technology is pushing the demand for skilled AI professionals who can monitor and manage the AI operations of an organization.
Since AI is an expansive term and branches off in multiple directions, the job opportunities available in this field are also diverse. According to recent studies, AI jobs are going to be the most in-demand jobs in the near future. Multiple job roles are available that come with specific job responsibilities. So, let’s have a look at some of these.
Machine Learning Engineer
An machine learning engineer is supposed to be one of the most in-demand jobs available in this field, the basic job of an ML engineer center round working on self-running software, and they need to work with a huge pile of data. In an organization, the machine learning engineers need to collaborate with data scientists and ensure that real-time data is being put to use for churning out accurate results. They need to work with data science models and develop algorithms that can process the data and offer insight. Mostly their job responsibility revolves around working with current machine learning frameworks and working on it to make it better. Re-training machine learning models is another significant responsibility they need to shoulder.
If recent statistics are to be believed the salary of a machine learning hovers around ₹681,881 in India.
Artificial Intelligence Engineer
AI engineers are indeed a specialized breed of professionals who are in charge of AI infrastructure and work on AI models. They work on designing models and then test and finally, they need to deploy these models. Automating functionalities is also important and most importantly they must understand the key problems that need AI solutions. AI engineers need to write programs, so they need to be familiar with several programming languages, having a background in Machine Learning Using Python could be a big help. Another important responsibility is creating smart AI algorithms for developing an AI system, as per the specific requirement that needs to be solved using that system.
In India, an AI engineer could expect the salary to be around ₹7,86,105 per year, as per Glassdoor figures.
Data Scientist
A data scientist is going to be in charge of the data science team and need to work on the huge volumes of data to analyze and extract information, build and combine models and employ machine learning, data mining, techniques along with utilizing numerous tools including visualization tools to help an organization reach its business goals. The data scientists need to work with raw data and he needs to be in charge of automating the collection procedure and most importantly they need to process and prepare data for further analysis, and present the insight to the stakeholders.
A data scientist could earn around ₹ 7,41,962 per year in India as per the numbers found on Indeed.
AI Architect
An AI architect needs to work with the AI architecture and assess the current status in order to ensure that the solutions are fulfilling the current requirements and would be ready to scale up to adapt to the changing set of requirements that would arise in the future. They must be familiar with the current AI framework that they need to employ to develop an AI infrastructure that is sustainable. Along with working with a large amount of data, an AI architect must be employing machine learning algorithms and posses a thorough knowledge of the product development, and suggest suitable applications and solutions.
In India an AI architect could expect to make around ₹3,567K per year as per Glassdoor statistics is concerned.
There are so many job opportunities available in the AI domain, and here only a few job roles have been described. There are plenty more diverse job opportunities await you out there, grab those, just get artificial intelligence certification in delhi ncr and be future-ready.