A time series is a sequence of numerical data in which each item is associated with a particular instant in time. Many sets of data appear as time series: a monthly sequence of the quantity of goods shipped from a factory, a weekly series of the number of road accidents, daily rainfall amounts, hourly observations made on the yield of a chemical process, and so on. Examples of time series abound in such fields as economics, business, engineering, the natural sciences (especially geophysics and meteorology), and the social sciences.
Univariate time series analysis- When we have a single sequence of data observed over time then it is called univariate time series analysis.
Multivariate time series analysis – When we have several sets of data for the same sequence of time periods to observe then it is called multivariate time series analysis.
The data used in time series analysis is a random variable (Yt) where t is denoted as time and such a collection of random variables ordered in time is called random or stochastic process.
Stationary: A time series is said to be stationary when all the moments of its probability distribution i.e. mean, variance , covariance etc. are invariant over time. It becomes quite easy forecast data in this kind of situation as the hidden patterns are recognizable which make predictions easy.
Non-stationary: A non-stationary time series will have a time varying mean or time varying variance or both, which makes it impossible to generalize the time series over other time periods.
Non stationary processes can further be explained with the help of a term called Random walk models. This term or theory usually is used in stock market which assumes that stock prices are independent of each other over time. Now there are two types of random walks: Random walk with drift : When the observation that is to be predicted at a time ‘t’ is equal to last period’s value plus a constant or a drift (α) and the residual term (ε). It can be written as Yt= α + Yt-1 + εt The equation shows that Yt drifts upwards or downwards depending upon α being positive or negative and the mean and the variance also increases over time. Random walk without drift: The random walk without a drift model observes that the values to be predicted at time ‘t’ is equal to last past period’s value plus a random shock. Yt= Yt-1 + εt Consider that the effect in one unit shock then the process started at some time 0 with a value of Y0 When t=1 Y1= Y0 + ε1 When t=2 Y2= Y1+ ε2= Y0 + ε1+ ε2 In general, Yt= Y0+∑ εt In this case as t increases the variance increases indefinitely whereas the mean value of Y is equal to its initial or starting value. Therefore the random walk model without drift is a non-stationary process.
So, with that we come to the end of the discussion on the Time Series. Hopefully it helped you understand time Series, for more information you can also watch the video tutorial attached down this blog. DexLab Analytics offers machine learning courses in delhi. To keep on learning more, follow DexLab Analytics blog.
NumPy also known as numerical python, is a library consisting of multidimensional array objects and a collection of routines for processing those arrays. Using NumPy, mathematical and logical operations on arrays can be performed without it which was not possible. For example-
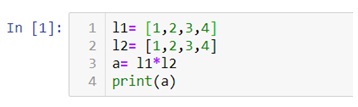
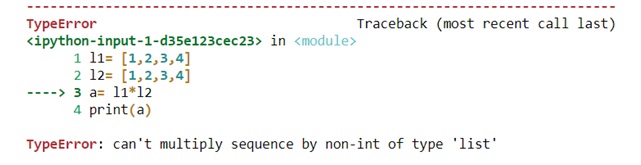
Multiplication of two lists will cause an error as a data structure like lists, tuple, dictionaries and sets do not allow mathematical operations.
Therefore we need NumPy to covert our data structures like lists into 1d, 2d, 3d or nd arrays so that mathematical operations can be performed. U
We can use .array() methods to create these arrays.
Now let’s check out few examples and also perform few mathematical operations to have a better understanding.
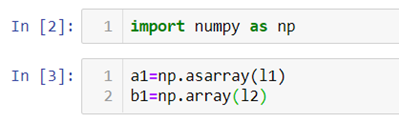
In the above code we first import NumPy library and then use .array() method to two 1d-array a1 and b1 using the list we previously created.
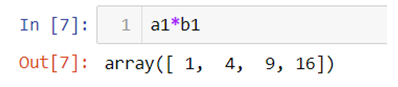
Now let’s multiply a1 and b1 array.
Now let’s use .array() method to directly create an array.
Arrays can be created using lists, tuples and dictionaries as you can see in the above example.
Now for 2-d arrays recall that we can also make list of lists. Let’s use that to create 2d-arrays.
2d-arrays can also be created using tuples.
Remember that we are not using these as matrices because matrix multiplication is an entirely different thing we are just trying to perform mathematical operations which were otherwise not possible.
Random Module
Numpy also has various ways with which we can create array of random numbers which then can be used in number of ways like generating a data for practice purposes or for building beautiful graphs for a presentation.
Given below is a list of type of random numbers you can generate
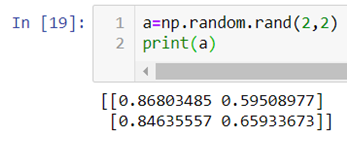
.rand() :- This particular method helps you generate uniformly distributed random numbers i.e. numbers between 0 and 1 where each number between 0 and 1 will have equal probability to be in the sample dataset.
The above code generates a 2d-array with values between 0 and 1.
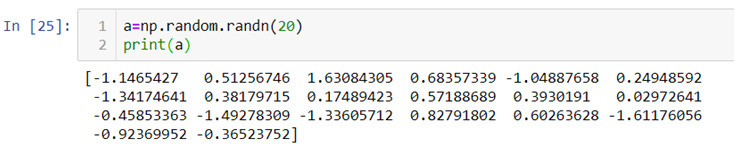
.randn():- This method generates normally distributed random numbers i.e. numbers between -3 and +3 where mean=median=mode and ploted gives a bell shaped curve.
Here the 20 random numbers are generated ranging between -3 and + 3.
Note:- Remember that the data is randomly picked from the normally distributed values between -3 and +3 so the graph is not bell shaped but the original data from which the values are being picked randomly is bell shaped with mean=median-mode.
.randint():-This method generates random integers between a given range.
So, with that we come to the end of the discussion on the Numpy. Hopefully it helped you understand Numpy, for more information you can also watch the video tutorial attached down this blog. DexLab Analytics offers machine learning courses in delhi. To keep on learning more, follow DexLab Analytics blog.
Artificial Intelligence, or, its more popular acronym AI is no longer a term to be read about in a sci-fi book, it is a reality that is reshaping the world by introducing us to virtual assistants, helping us be more secure by enabling us with futuristic measures. The evolution of AI has been pretty consistent and as we are busy navigating through a pandemic-ridden path towards the future, adapting to the “new normal”, and becoming increasingly reliant on technology, AI assumes a greater significance.
The AI applications which are already being implemented has resulted in a big shift, causing an apprehension that the adoption of AI technology on a larger scale would eventually lead to job cuts, whereas in reality, it would lead to the creation of new jobs across industries. Adoption of AI technology would push the demand for a workforce that is highly skilled, enrolling in an artificial intelligence course in delhi could be a timely decision.
Now that we are about to reach the end of 2020, let us take a look at the possible impacts of AI in the future.
AI will create more jobs
Yes, contrary to the popular apprehension AI would end up creating jobs in the future. However, the adoption of AI to automate tasks means yes, there would be a shift, and a job that does not need special skills will be handled by AI powered tools. Jobs that could be done without error, completed faster, with a higher level of efficiency, in short better than humans could be performed by robots. However, with that being said there would be more specialized job roles, remember AI technology is about the simulation of human intelligence, it is not the intelligence, so there would be humans in charge of carrying out the AI operated areas to monitor the work. Not just that but for developing smarter AI application and implementation there should be a skilled workforce ready, a report by World Economic Forum is indicative of that. From design to maintenance, AI specialists would be in high demand especially the developers. The fourth industrial revolution is here, industries are gearing up to build AI infrastructure, it is time to smell the coffee as by the end of 2022 there will be millions of AI jobs waiting for the right candidates.
Dangerous jobs will be handled by robots
In the future, hazardous works will be handled by robots. Now the robots are already being employed to handle heavy lifting tasks, along with handling the mundane ones that require only repetition and manual labor. Along with automating these tasks, the robot workforce can also handle the situation where human workers might sustain grave injuries. If you have been aware and interested then you already heard about the “SmokeBot”. In the future, it might be the robots who will enter the flaming buildings for assessment before their human counterparts can start their task. Manufacturing plants that deal with toxic elements need robot workers, as humans run a bigger risk when they are exposed to such chemicals. Furthermore, the nuclear plants might have a robot crew that could efficiently handle such tasks. Other areas like pipeline exploration, bomb defusing, conducting rescue operations in hostile terrain should be handled by AI robots.
Smarter healthcare facilities
AI implementation which has already begun would continue to transform the healthcare services. With AI being in place CT scan and MRI images could be more precise pointing out even minuscule changes that earlier went undetected. Drug development could also be another area that would see vast improvement and in a post-pandemic world, people would need to be better prepared to fight against such viruses. Real-time detection could prevent many health issues going severe and keeping a track of the health records preventive measures could be taken. One of the most crucial changes that could be revolutionary, is the personalized medication which could only be driven by AI technology. This would completely change the way healthcare functions. Now that we are seeing chat bots for handling sales queries, the future healthcare landscape might be ruled by virtual assistants specifically developed for offering assistance to the patients. There are going to be revolutionary changes in this field in the future, thereby pushing the demand for professionals skilled in deep learning for computer vision with python.
Smarter finance
We are already living in an age where we have robo advisors, this is just the beginning and the growing AI implementation would enable an even smarter analytics system that would minimize the credit risk and would allow banks and other financial institutes to minimize the risk of fraud. Smarter asset management, enhanced customer support are going to be the core features. Smarter ML algorithms would detect any and every oddity in behavior or in transactions and would help prevent any kind of fraud from happening. With analytics being in place it would be easier to predict the future trends and thereby being more efficient in servicing the customers. The introduction of personalized services is going to be another key feature to look out for.
Retail space gets a boost
The retailers are now aiming to implement AI applications to offer smart shopping solutions to the future buyers. Along with coming up with personalized shopping suggestions for the customers and showing them suggestions based on their shopping pattern, the retailers would also be using the AI to predict the future trends and work accordingly. Not just that but they can easily maintain the supply and demand balance with the help of AI solutions and stock up items that are going to be in demand instead of items that would not be trendy. The smarter assistants would ensure that the customer queries are being handled and they could also be helping them with shopping by providing suggestions and information. From smart marketing to smarter delivery, the future of retail would be dominated by AI as the investment in this space is gradually going up.
The future is definitely going to be impacted by the AI technology in more ways than one. So, be future ready and get yourself upskilled as it is the need of the hour, stay updated and develop the skill to move towards the AI future with confidence.
If you are aware of the growth opportunities awaiting you in the Machine Learning domain, you must be in a rush to master the Machine Learning skills. Now, there are courses available that aim to sharpen the students with skills they would need to work in a challenging environment. However, some often prefer the self-study mode for developing knowledge in this highly specialized domain. No matter which way you prefer to learn, ultimately your passion and dedication would matter the most, because in both ways you need to put in the hard work and really toil hard to make any progress.
Is self-study a feasible option?
If you have already been through some course and want to go to the advanced level through self-study that’s a different issue, but, for those who are just starting out without any background in science, does it even make any sense to opt for self-study?
Given the way Machine Learning technology is moving fast and creating a demand for professionals with highly specialized industry knowledge, do you think self-study would be enough? Do you think a self-study plan to learn something you have no idea about would work? How much time would you need to devote? What should be your learning route? And how do you know this is the right path to follow?
Before we dive deeper into the discussion, we need to go through some prerequisites for Machine Learning study plan.
Machine learning is a broad field and assuming you are a beginner with no prior knowledge in this domain, you have to be familiar with mathematics, statistics, programming languages, meaning undergoing a Python certification training</strong>, must be proficient in data handling including analysis and modeling, you have to work on algorithms. So, can you pick up all of these skills one by one via self-study? Add to the list the latest Machine Learning tools and applications you need to grasp.
There will be help available in the form of:
There would be vast resources, in forms of e-books, lectures, video tutorials, most of these are free and easily accessible.
There are forums, groups out there which you can join and access help
You can take part in online competitions
Think it through. How long will it take for you to get from one stage to the next?
Even though there being no dearth of resources available you would be struggling with your progress and most importantly you would struggle to keep up with the pace the technology is moving ahead. Picking up a programming language, grasping and mastering concepts of linear algebra, probability, data is going to be a mammoth task.
What difference a certification course can make?
To begin with these courses are designed for people coming from different backgrounds, so, you having or, not having any prior knowledge in mathematics, statistics wouldn’t matter as you would be taught everything from scratch be it math or, Machine Learning Using Python.
The programs are designed for both working professionals as well as for beginners, all you need to do is choose the one that suits your specific level.
These courses are designed to transform you into an industry-ready professional and you would be under the guidance of professionals who are more than familiar with the nuances of the way the industry functions.
The modules would follow a strict schedule and your training path would be well planned out covering all the areas you need to master.
You would learn via hands-on training and get to handle projects. Nothing makes you skilled like hands-on training.
Your journey towards a smarter future needs to be through a well mapped-out path, so, be smart about it. DexLab Analytics offers industry-ready courses on Data Science, Machine Learning course in Gurgaon and AI with Python. Take advantage of the courses that are taught by instructors who have both expertise and experience. Time is indeed money, so, stop wasting time and get down to learning.
In this blog we will be introducing you to the Gaussian Distribution/Normal Distribution. Knowledge of the distribution of your data is quite important as it tells you the trend your data follows and a continuous observation of the trend helps you predict the future observations more accurately.
One of the most important distribution in statistics is Gaussian Distribution also known as Normal Distribution follows, that the mean, median and mode of the data are equal or almost equal. The idea behind this is that the data you collect should not have a very high standard deviation.
How to generate a normally distributed data in Python
First we will import all the necessary libraries
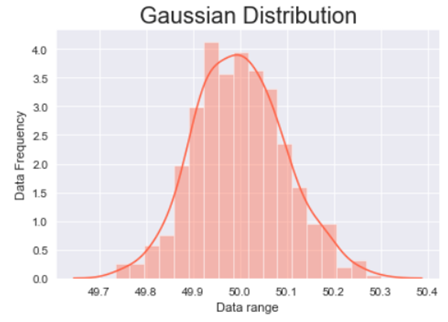
Now we will use .normal() method from Numpy library to generate the data where 50 is the mean, .1 is the deviation and 500 is the number of observations to be generated.
To plot the data and have a look at the data distribution we will be using .distplot() method from the Seaborn library and to make our plot visually better we will be using .set_style() method to change the background of our graph.
In the above line of codes we are also using Matplotlib library to add axis labels and title to the graph. We are also adding an argument fontsize to adjust the size of the font.
The above graph is a bell shaped curve with the peak of the curve in the center of the graph. This is one of the most important assumption of the Gaussian distribution on that the curve is symmetric at the center, some of the other assumptions are:-
Assumptions of the Gaussian distribution:
The mean, median and mode are equal.
Exactly half of the values are to the left of the center and exactly half of the values are to the right.
The total area under the curve is 1.
It has a continuous probability distribution.
68% of the data is -1 to 1 standard deviation away from the mean.
95% of the data is -2 to 2 standard deviation away from the mean.
99.7% of the data is -3 to 3 standard deviation away from the mean.
The last three assumptions can be proven with the help of standard normal distribution.
What is standard normal distribution?
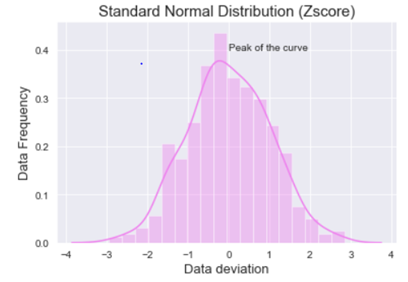
Standard normal distribution also known as Z-score is a special case of normal distribution where we convert the normally distributed data into data deviations. The mean of such a distribution is 0 and the standard deviation is 1.
Let’s see how we can achieve the standard normal distribution in Python.
We will be using the same normally distributed data as above.
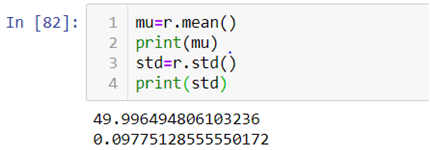
First we will be calculating the mean and standard deviation of the data we created with the help of the above code by using .mean() and .std() method.
Now to calculate the Z-score we will first make an empty list and then append the calculated values one by one in that list with the help of a for-loop.
As you can see in the above code we are first subtracting the value from the mean and then dividing it by the standard deviation.
Now let’s see how the calculated data visually looks like.
When we look at the above graph we can clearly see that the data is by max 3 standard deviations away from the mean.
For further explanation check out the video attached down the blog.
So, with this we come to the end of today’s discussion on Gaussian distribution, hopefully, you found this explanation helpful. For such informative posts keep an eye on the Dexlab Analytics blog. Dexlab Analytics is a premier institute that offers cutting edge courses such as credit risk analysis course in Delhi.
When we take a look at a video or, a bunch of images we know what’s what just by taking one look, it is our innate ability that gradually developed. Well, sophisticated technologies such as object detection can do that too. It might sound futuristic but it is happening now in reality. Object detection is a technique of the AI subset computer vision that is concerned with identifying objects and defining those by placing into distinct categories such as humans, cars, animals etc.
It combines machine learning and deep learning to enable machines to identify different objects. However, image recognition and object detection these terms are often used interchangeably but, both techniques are different. Object detection could detect multiple objects in an image or, in a video. The demand for trained experts in this field is pretty high and having a background in deep learning for computer vision with python can help one build a dream career.
Object detection has found applications across industries. Let’s take a look at some of these applications.
Tracking objects
It is needless to point out that in the field of security and surveillance object detection would play an even more important role. With object tracking it would be easier to track a person in a video. Object tracking could also be used in tracking the motion of a ball during a match. In the field of traffic monitoring too object tracking plays a crucial role.
Counting the crowd
Crowd counting or people counting is another significant application of object detection. During a big festival, or, in a crowded mall this application comes in handy as it helps in dissecting the crowd and measure different groups.
Self-driving cars
Another unique application of object detection technique is definitely self-driving cars. A self-driving car can only navigate through a street safely if it could detect all the objects such as people, other cars, road signs on the road, in order to decide what action to take.
Detecting a vehicle
In a road full of speeding vehicles object detection can help in a big way by tracking a particular vehicle and even its number plate. So, if a car gets into an accident or, breaks traffic rules then it is easier to detect that particular car using object detection model and thereby decreasing the rate of crime while enhancing security.
Detecting anomaly
Another useful application of object detection is definitely spotting an anomaly and it has industry specific usages. For instance, in the field of agriculture object detection helps in identifying infected crops and thereby helps the farmers take measures accordingly. It could also help identify skin problems in healthcare. In the manufacturing industry the object detection technique can help in detecting problematic parts really fast and thereby allow the company to take the right step.
Object detection technology has the potential to transform our world in multiple ways. However, the models still need to be developed further so that these can be applied across devices and platforms in real-time to offer cutting-edge solutions. Pursuing a Python Certification course can help develop the required skills needed for making a career in the field of machine learning.
This is the 3rd part of the ongoing Regex or, regular expression in Python series where we are discussing how to handle textual data. In the second part we introduced you to the re library and in this third segment, we are going to be discussing how to substitute characters or, words with re library.
Re library has a wide range of methods to deal with textual data, one such method is .sub() which helps us substitute alphabets or words based on the patterns we build. This method can be used with .match() method and .search() method, both having differences in the way they extract a pattern.
Difference between .match() & .search()
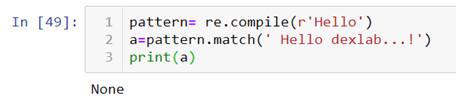
.match() :- This method extracts the required text only at the begging.
.search() :-This can extract the required string from the entire text but only at the first occurrence
In the above code you can see that even though the word “Hello” is in the middle of the text we are able to fetch it because of the special attribute of the .search() method. Here we are again using “Hello dexlab…!” as an example and .compile() is being used to create and apply our pattern.
Now suppose if we want to substitute the word “Hello” with another string “Hi” we will have to use .sub() method from the re library. But there are ways to use this method directly or indirectly.
First let’s see the direct method.
In the above line of code we first mention what we want to substitute and with what and then we add the text.
Second way to do this is by first using .compile() method to build the pattern and then use that pattern to substitute the alphabet or word.
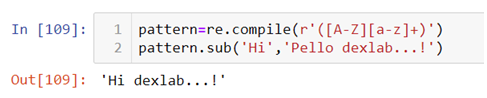
The above pattern in the .complie() method states that there is a word with the first alphabet in uppercase combined with lowercase alphabets to be substituted with the word “Hi”. This pattern can match any string with the same characteristics, for example:-
Look at the text used in the .sub() method, now instead of “Hello” we have “Pello” with the same characteristics substituted with the word “Hi”. But one must not forget this pattern can also be used in the .sub() method directly and the use of .compile() method is optional. .compile() method is used only to create an object based code.
So, this wraps up the discussion on how to substitute characters or, words with re library. Hopefully, you found this blog informative, if you wish to find more Python Certification course topics, keep following the Dexlab Analytics blog.
This is the second part of the Regex series, where we will be continuing on by introducing you to another library in python, the re library. The previous blog introduced you to the Regex library in Python, and you learned about meta-characters and literals which could be used for creating patterns. This particular segment is about introducing the re library to help you with textual data analysis.
Re library in python holds the key to deal with all the problems relating to textual data analysis. This library provides a range of methods that can help you build patterns and extract or substitute the desired string. For example, suppose you want to change all the negative words to positive in a novel, for that all you need to have is a soft copy of the same and then you can import the re library and use its predefined methods first to make a pattern to extract the words and then substitute it to make the required changes.
Here one such method which we are going to use today from the re library is .compile() combined with .match() method to build and extract the pattern with the help of literals and meta-characters explained in the previous blog.
.compile() and .match() Methods
.complie() is used to build the pattern. You can use the meta-characters and literals within the parenthesis to build the pattern of the word which you want to extract or change. This is practically the first step without which not much can be done in re library. But why do we need a pattern and what is it that makes it necessary? To answer this question I am going to use few steps:-
First thing to do is to observe the word or the string and see what is it that makes that specific word or words which you want to extract different from the rest of the text i.e. is the word a combination of digit or alphabet or special character, is there a special character before and after the word etc.
Now recall all the meta-characters we have studied so far.
Combine them with the .complie() method which basically helps us bring the meta-characters together.
Now all there is left for us to do is apply the pattern on the text.
Therefore knowledge of meta-characters is necessary to form patterns to manipulate your textual data.
Now let’s see how to import re library and practically solve few of the Regex questions.
Use the above code to import the Regex library.
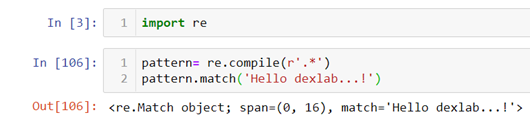
Question 1: How to make a pattern to extract the entire string “Hello dexlab…!!”?
In the above code we are using a combination of. (period)and * where
. (period) means match alpha-numeric or special character
* means match anything zero or more times
When combined together this means that you can match alpha-numeric or special characters zero or more times. Therefore the end result is:-
.match()method has a special property that it can match anything only at the beginning of the line. Suppose I want to extract “Hello” from a string, .match()method will only work when word is at the 0 index.
Question: How to extract and match only special characters?
The above code is matching only the space which is at the 0th index but not all the simultaneous special characters. To make a pattern that can match all the special characters we can use *
You can try ? and + to check the difference it makes on the output.
Question: How to extract numbers and special characters?
Now you must be wondering why the above code did not recognize the special characters after the numbers like @ and space. Here you must remember that the output you get is based on the pattern you make. In the above code we mentioned nothing that matches anything after the numbers. So we further need to expand our line of codes.
Question: How to extract only the output?
You can use the slice operator [] to extract only the text by using 0 index.
You must have picked up the fundamentals of the re library from the blog, watch the video attached below to follow the tutorial step by step. Follow the Regex series to gain expertise in textual data handling. Dexlab Analytics blog has more interesting and informative posts on Python Programming training.
Python is a versatile programming language and it has a rich library. In the visualization series we introduced you to different libraries used for data visualization purposes. Now, we introduce you to the Regex library in Python for handling textual data.
In Python to perform pattern recognition on textual data Regex is a library that provides a range of methods which when used with right pattern gives us the desired results. For example, if you want to change the spelling of colour to color in your text you can easily do so with the help of a given method provided that you form the pattern correctly.
Type of textual data in Regex
Literals:- In Python literals are the characters or words with their original meaning intact like the word dog means a literal dog and there is no hidden meaning behind that word.
Meta-characters:- These are the words or characters which hold special meaning for example \n means a new line or \t means tab separated values.
Given below are few of the meta-characters used in python with their meanings:-
\w – Matches alpha-numeric characters i.e. \w= 1, \w= a, \w\w= a1
\W– Matches special characters i.e. \W= %
Dog[ogn]– Matches a single character within the square bracketsi.e. Dogo, Dogg, Dogn
Dog(ogn) – Matches the entire string within the parenthesisi.e. Dogogn
Dog(ogn|aaa)– Matches either ogn or aaa i.e. Dogogn or Dogaaa
*– Matches 0 or more characters i.e. tre* = tree, tre*= tr, tre*= treeeeee
?– Matches 0 or 1 character i.e. colou?r= color, colou?r= colour
+ – Matches 1 or more character i.e. tre+= tree, tre+= treee, tre+≠tre
. – Matches alpha-numeric or special characters but only one time i.e. tre.= tree, tre.= tre#, tre.=tre1, tre.≠tre#1
The above meta-characters alone or in combination are used to form a pattern which then are used for text mining for example tre.* means match anything 0 or more times that means now we can match tre#1 or tre.
Watch the video tutorial attached below to learn more about the fundamentals of this library.
Hopefully you found the discussion on Regex library helpful and at the end of it you must have become familiar with the way this particular library works. To learn more about python for data analysis, keep on exploring Dexlab Analytics blog, where you will always find informative posts.