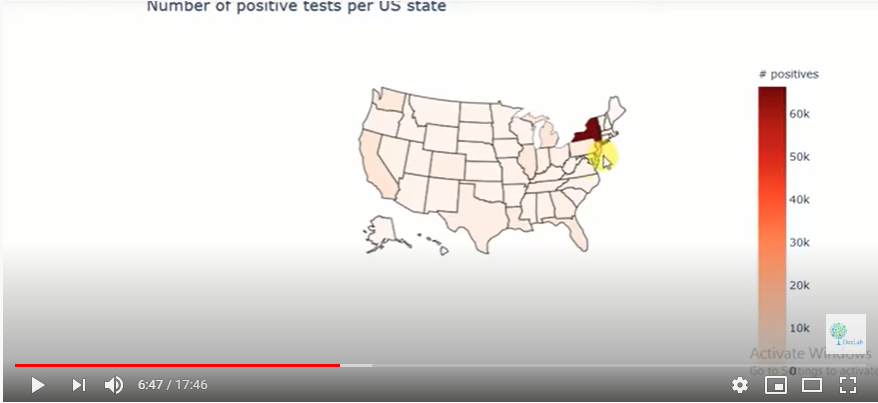
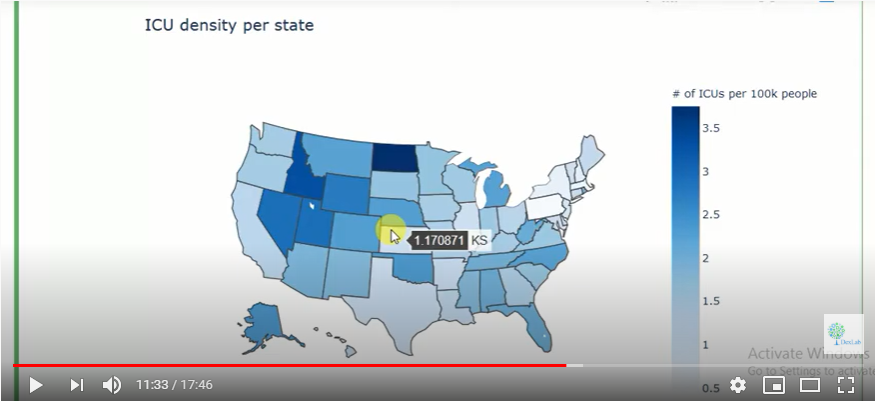
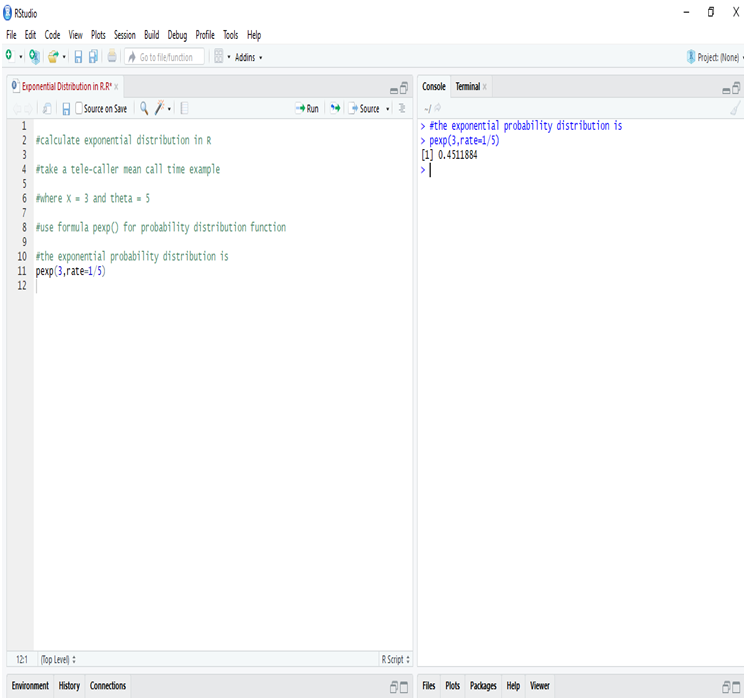
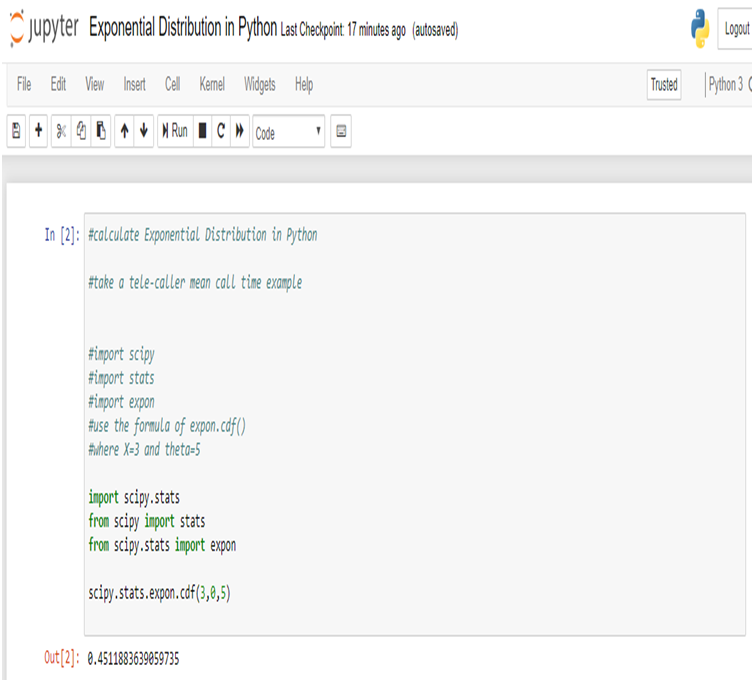
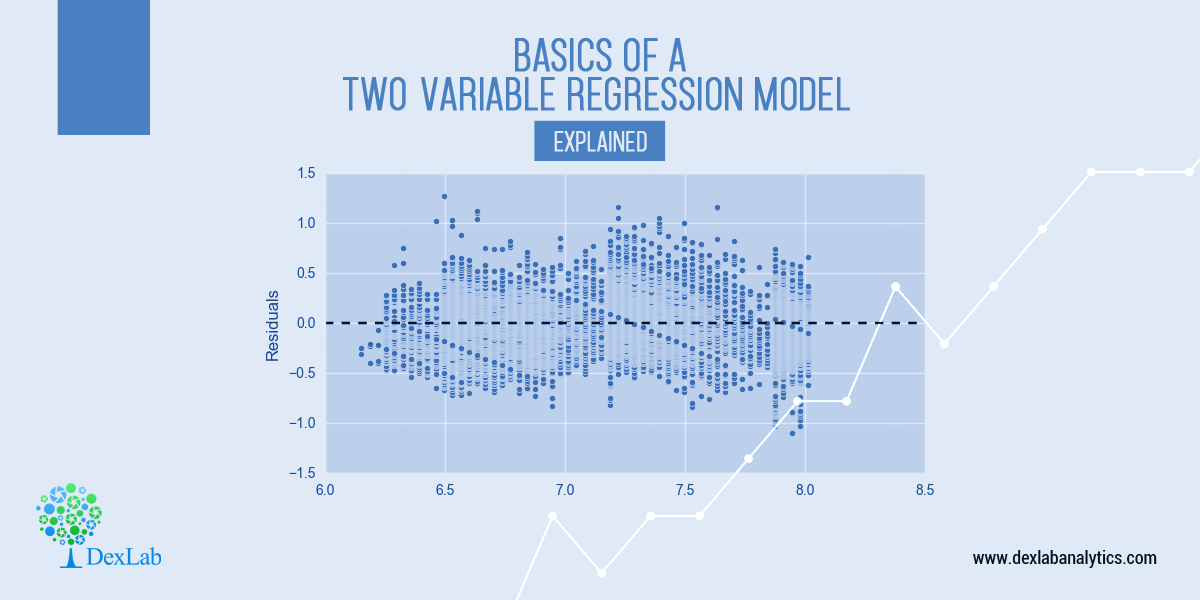
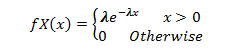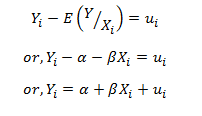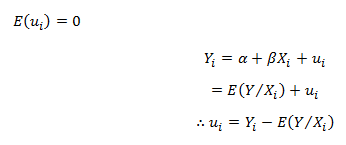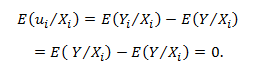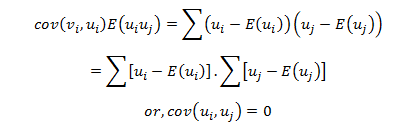Ever since the world woke up to discover the significance of data, there has been tremendous advancement in this field each taking us further towards the utilization of accumulated data to achieve a higher level of efficiency. Predictive analytics is all about extracting hidden information in data and combining technologies like machine learning, artificial intelligence, data analysis, statistical modeling to predict future trends.
Sifting through stored datasets comprising structured and unstructured data, predictive analytics identifies the patterns hidden and analyzes those patterns to make predictions about trends and thereby helps to identify opportunities as well as risk factors. Not just forecasting, but predictive analytics also helps you find associations that could lead you to a new breakthrough. Having undergone big data training in gurgaon, could actually prove to be a big boost for someone planning on working in this specialized field. Now, when you have access to data-based forecasting, it is easy for you to identify both negative and positive trends and in turn, it helps you take the right decisions.
Businesses especially rely heavily on predictive analytics for market analysis, targeting their customers, and assessing risk factors. Unlike before when these business strategies were based on mere guesswork, now the think-tank has access to data to anticipate an outcome.
Predictive analytics models: Predictive analytics models could be classified into two broad categories as follows
Classification models: In this model data is categorized on the basis of some specified criterion.
Regression models: Regression models focus on identifying patterns that already exist, or, that has been continuing for a while.
So, what are the processes involved in Predictive analytics?
Predictive analytics process could be broken down to different stages and let’s take a look at what the steps are
Defining the Project: This is the first stage when you decide what kind of outcome you are expecting. Besides setting out clear business objectives you also need to be clear about the deliverables as these will have a bearing on your data collection.
Collecting all Data: This is the second stage where data from different sources are collected.
Analyzing Data: In this stage, the data collected is cleaned and gets structured and also gets transformed and modeled.
Statistics: A statistical model is used to test the assumptions, hypotheses, as well as findings.
Modeling: Through multi-model evaluation best option is chosen from an array of available options. So, the idea is to create an accurate predictive model.
Deployment: This is the stage of deploying the predictive model and create an option for deploying the results for productive purposes in reality.
monitoring: the final and an important stage where the models created are monitored and tested with new data sets to check whether the models still have relevance.
The applications of predictive analytics
Predictive analytics models have found usage across industries
- In the financial sector, predictive analytics could be used for credit risk measurement, detecting fraud as well as for minimizing the risk, and also for retaining customers.
- In the field of healthcare predictive analytics could be used for detecting severe health complications that might develop in a patient in the future.
- In business predictive analytics could be used for short-term or, long-term sales forecasting. In fact, the reaction of the customer could be anticipated and changes could be made accordingly.
- When a huge investment is involved predictive analytics could help to identify the problematic areas that could pose risk. Accurate risk assessment could help a company secure a better ROI.
- Predictive analytics could help companies with their customer service, marketing campaigns, sales goals. Companies can strategize better to retain customers and improve their relations with them.
- With predictive analytics in place, it would be easier to predict equipment maintenance needs and it could also be used for forecasting an equipment failure.

Predictive analytics is being adopted in a number of industries ranging from insurance to healthcare. The forecasting that one gets is highly accurate. However, building a reliable dataset and building a reliable model is essential. Having trained personnel on the team who have done data analyst course in delhi, could be helpful.
.