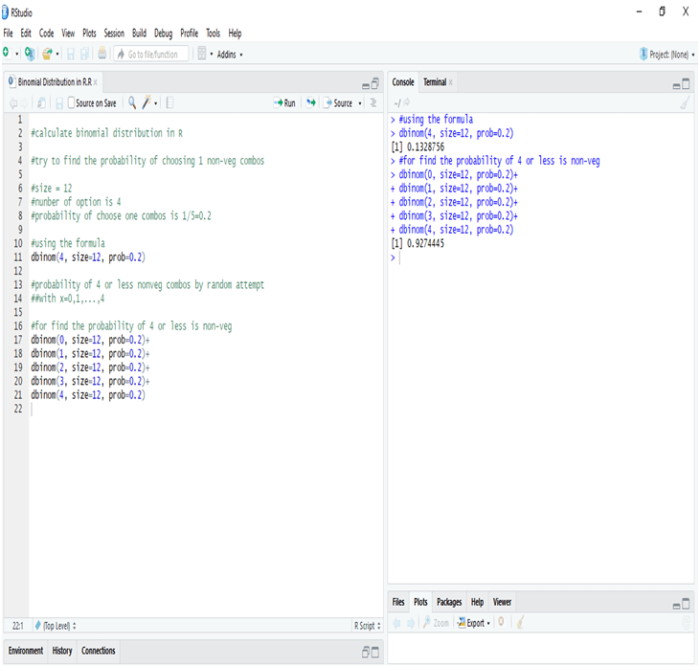
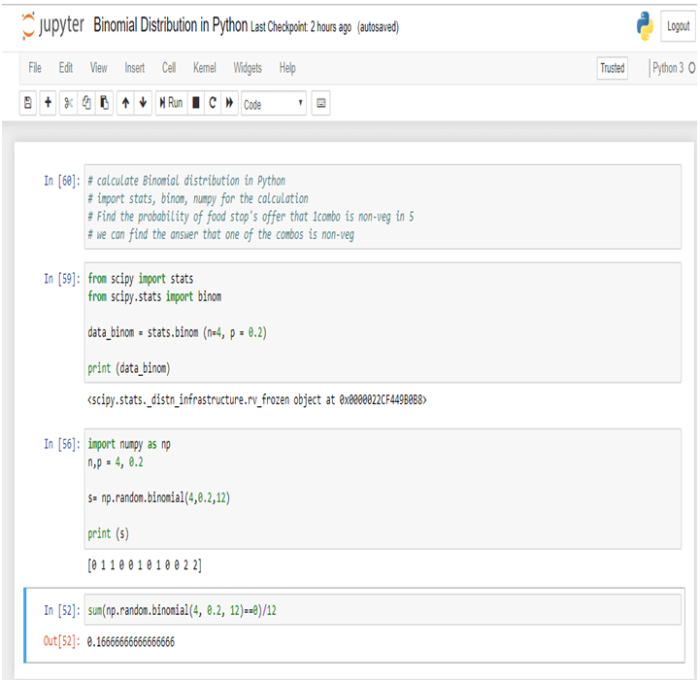
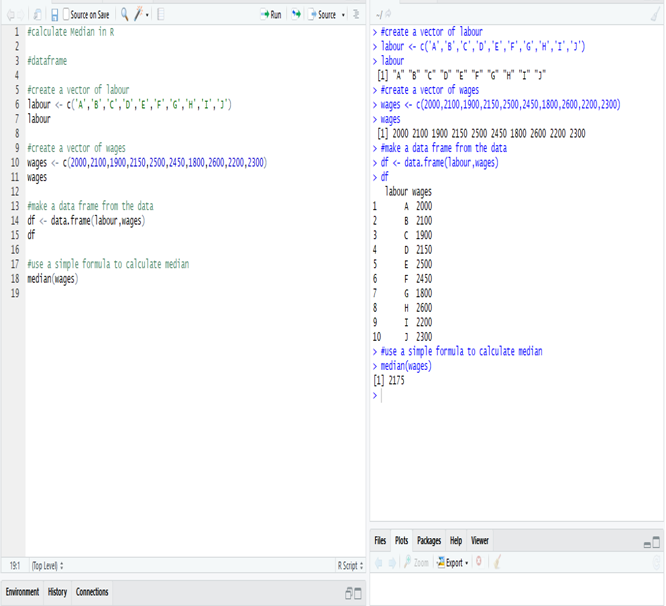
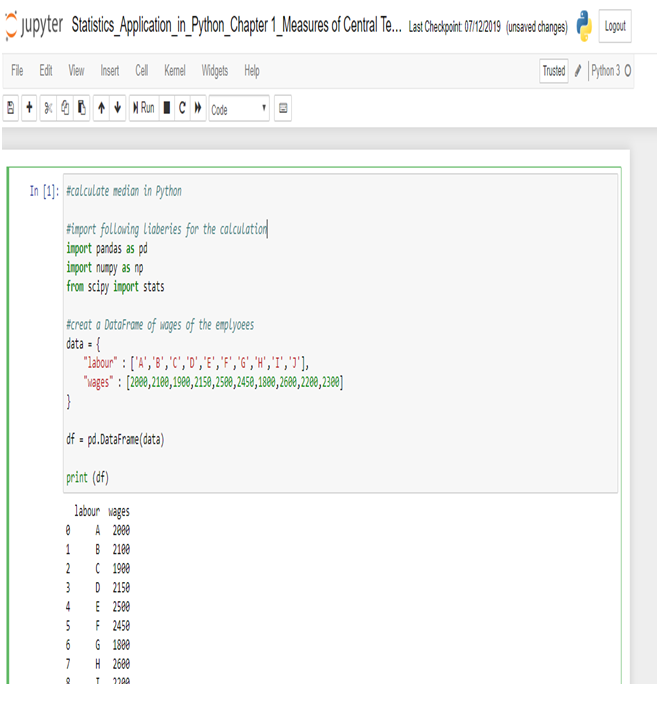
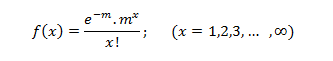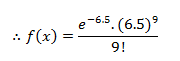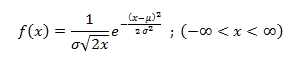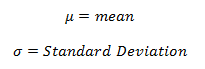Statistics is a branch of mathematics which deals with the collection, analysis, interpretation and presentation of masses of numerical data. Statistics is a tool used to communicate our understanding of data. It helps us understand the world better, make assertions, and communicate our confidence in the statements we are making.
Two main statistical methods are used in data analysis:
- Descriptive statistics: This method is used to summarize data from a sample using measures such as the mean or standard deviation
- Inferential statistics: With this method, you can conclude data that are subject to random variation (e.g., observational errors, sampling variation).
This article is about the descriptive statistics which are used to describe and summarize the datasets. We are also going to see the available Python libraries to get those numerical quantities.
This whole topic will be covered in a series of two blogs. This first blog is about the types of measures in descriptive statistics. Furthermore, we will also see the built-in Python “Statistics” library, which has a relatively small number of the most important statistics functions.
Descriptive statistics can be defined as the measures that summarize a given data, and these measures can be broken down further into the measures of central tendency and the measures of dispersion. Measures of central tendency include mean, median, and the mode, while the measures of dispersion include standard deviation and variance.
We will cover the following topics in descriptive statistics:
- Measures of Central Tendency
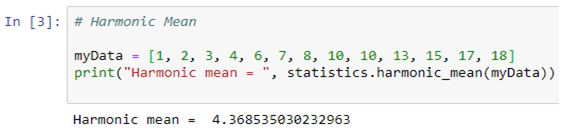
- Mean
- Median
- Mode
- Measures of Dispersion
- Variation
- Standard Deviation
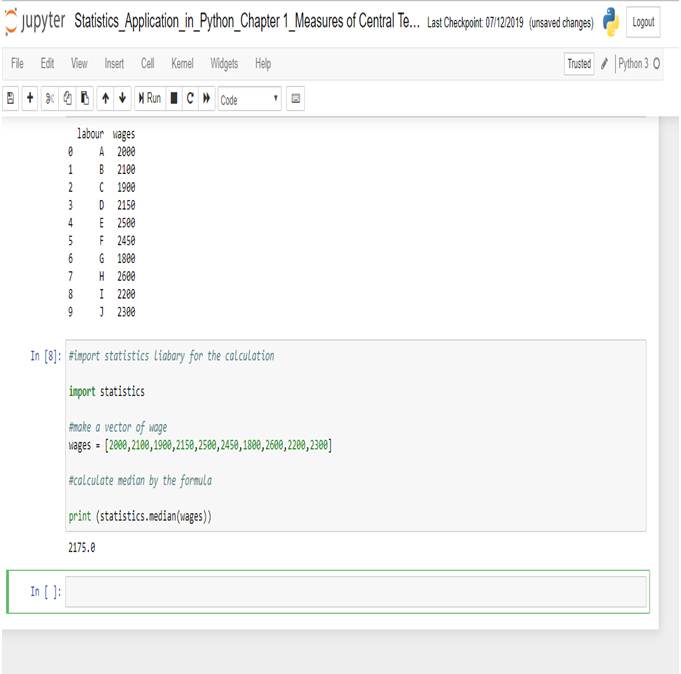
First, we need to import the Python statistics module.
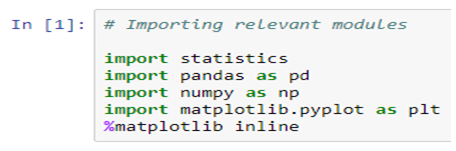
Mean
The arithmetic mean is the sum of data divided by the number of data-points. It is a measure of the central location of data in a set of values that vary in range. In Python, we usually do this by dividing the sum of given numbers with the count of the number present. Python mean function can be used to calculate the mean/average of the given list of numbers. It returns the mean of the data set passed as parameters.
mean( ): Arithmetic mean (“average”) of data.
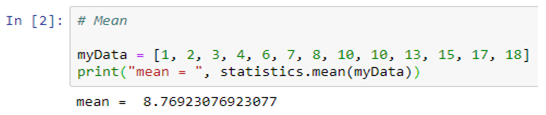
harmonic_mean( ): It is the reciprocal of the arithmetic mean of the reciprocals of the data (say for three numbers a, b and c, 1/mean = 3/(1/a + 1/b + 1/c)).
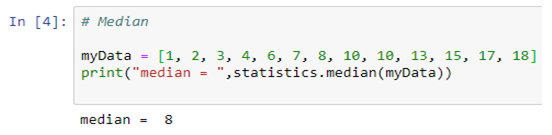
Median
median( ): Median or middle value of data is calculated as the mean of middle two. When the number of data points is odd, the middle data point is returned. The median is a robust measure of a central location and is less affected by the presence of outliers in your data compared to the mean.
median_low( ): Low median of data is calculated when the number of data points is odd. Here the middle value is usually returned. When it is even, the smaller of the two middle values is returned.
median_high( ): High median of data is calculated when the number of data points is odd. Here, the middle value is usually returned. When it is even, the larger of the two middle values is returned.
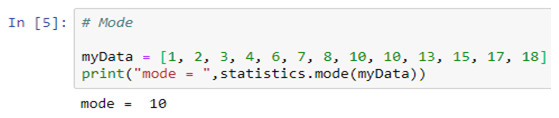
Mode
mode( ): Mode (most common value) of discrete data. The mode (when it exists) is the most typical value and is a robust measure of central location.
Measures of Dispersion
Measures of dispersion are statistics that describe how data varies, usually relative to the typical value. While measures of centre give us an idea of the typical value, measures of spread give us a sense of how much the data tends to diverge from the typical value.
These following functions (from the statistics module in python) calculate a measure of how much the population or sample tends to deviate from the typical or average values.

Population Variance
pvariance( ): Returns the population variance of data. Use this function to calculate the variance from the entire population. To estimate the variance from a sample, the variance ( ) function is usually a better choice. When called with the entire population, this gives the population variance σ². When called on a sample instead, this is the biased sample variance s², also known as variance with N degrees of freedom.

Population Standard Deviation
pstdev( ): Return the population standard deviation (the square root of the population variance)

Sample Variance
variance ( ): Returns the sample variance of data, an iterable of at least two real-valued numbers. Variance, or second moment about the mean, is a measure of the variability (spread or dispersion) of data. A large variance indicates that the data is spread out; a small variance indicates it is clustered closely around the mean. If the optional second argument is given to the function, it should be the mean of data. This is the sample variance s² with Bessel’s correction, also known as variance with N-1 degrees of freedom.

Sample Standard Deviation
stdev( ): Returns the sample standard deviation (the square root of the sample variance)

Conclusion
So, this article focuses on describing and summarizing the datasets, also helping you to calculate numerical quantities in Python. It’s possible to get descriptive statistics with pure Python code, but that’s rarely necessary. In the next series of this blog we will see the Python statistics libraries which are comprehensive, popular, and widely used especially for this purpose.
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.