
Databricks recently embraced the Apache Spark 2.4, a latest version. They are integrating it into their platform of analytics. Also, the company is on its way to unveil another runtime feature that would simplify the intricacies of deep learning.
Needless to say, Databricks is one of the most powerful supporters of version 2.4 of Spark, the notable stream processing framework. The latest upgraded version features improvement in the performance of machine learning framework running on Spark as well as distributed deep learning. It also includes modifications that would instantly address dependency issues related to deep learning tasks.
Project Hydrogen is an ambitious initiative; it’s under this tag the Spark upgrades were fused and introduced as a new scheduling mode, known as ‘barrier execution’. It encourages developers to embed training in lieu of distributed deep learning posed as an Apache Spark workload.
In context to above, Reynold Xin, a staunch Spark contributor and co-founder at Databricks said, “This is the largest change to Spark’s scheduler since the inception of the project.” He further mentioned that the upgrades will actually help reduce the complexities of machine learning structures and ensure high efficacy.
The latest runtime detail categorized HorovodRunner is developed to rationalize scaling and streamlining of distributed deep learning workloads. It is performed from a single machine to huge clusters. Previously, drifting from single-node workloads to huge distributed training on GPU or CPU clusters needed a bunch of full code rewrites – it was exceedingly challenging enough. Undeniably, HorovodRunner reduces training as well as programming time cutting down them from hours to a few minutes. This was claimed by the professionals working at Databricks.
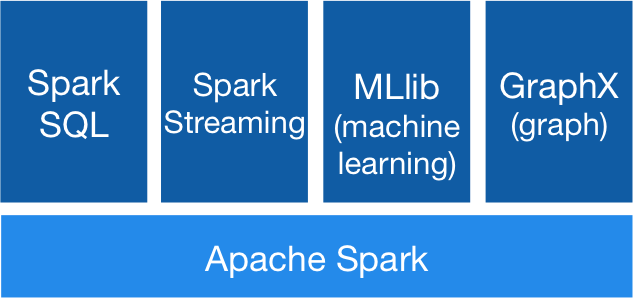
Besides Horovod, Databricks is found to be saying that its platform offers native integration with TensorFlow, Kera and several other machine learning programs coupled with MLib and GraphFrames super machine learning algorithms.
On top of all this, a few weeks back, Databricks associated itself with a versatile cloud data integrator Talend with a sole aim to integrate the cloud service with their own data analytics platform to allow data scientists leverage the cluster computing framework – it would help process large data sets at scale.
About Apache Spark:
Apache Spark is a robust, well-integrated analytics engine efficient in processing large datasets. Crafted for high speed, productivity and generic use, it is considered as one of the most popular projects in motion under Apache software umbrella. It is also one of the most volatile and active open source big data projects.
DexLab Analytics is a top-notch Apache Spark training institute in Gurgaon. It provides top of the line in-demand skill training on a plethora of new-age IT related courses, such as data science, data analytics courses, big data, risk analytics and more.
The blog was sourced from ― www.datanami.com/2018/11/19/databricks-upgrades-spark-support-adds-ml-runtime
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.

