
Amazon, Yahoo and eBay has embraced Apache Spark. It’s a technology worth taking a note of. A bulk of organizations prefers running Spark on clusters along with thousands of nodes. Till date, the biggest known cluster consists of more than 8000 nodes.
Introducing Apache Spark
Spark is basically an Apache project tagged as ‘lightning fast cluster computing’. It features a robust open-source community and is the most popular Apache project right now.
Spark is equipped with a faster and better data processing platform. It runs programs faster in memory as well as on disk as compared to Hadoop. Furthermore, Spark lets users write code as quickly as possible – after all, you’ve more than 80 high-level operators for coding!

Key elements of Spark are:
- It offers APIs in Java, Scala and Python in support with other languages
- Seamlessly integrates with Hadoop ecosystem and other data sources
- It runs on clusters controlled by Apache Mesos and Hadoop YARN
Spark core
Ideal for wide-scale parallel and distributed data processing, Spark Core is responsible for:
- Communicating with storage systems
- Memory management and fault recovery
- Arranging, assigning and monitoring jobs present in a cluster
The nuanced concept of RDD (Resilient Distributed Dataset) was first initiated by Spark. An RDD is an unyielding, fault-tolerant versatile collection of objects that are easily operational in parallel. It can include any kind of object, and supports mainly two kinds of operations:
- Transformations
- Actions
Spark SQL
A major Spark component, SparkSQL queries data either through SQL or through Hive Query Language. It first came into operations as an Apache Hive port to run on top of Spark, replacing MapReduce, but now it’s being integrated with Spark Stack. Along with providing support to numerous data sources, it also fabricates several SQL queries with code transformations, which makes it a very strong and widely-recognized tool.
Spark Streaming:
Ideal for real time processing of streaming data – Spark Streaming receives input data streams, which is then divided into batches only to be processed by Spark engine to unleash final stream of results, all in batches.
Look at the picture below:
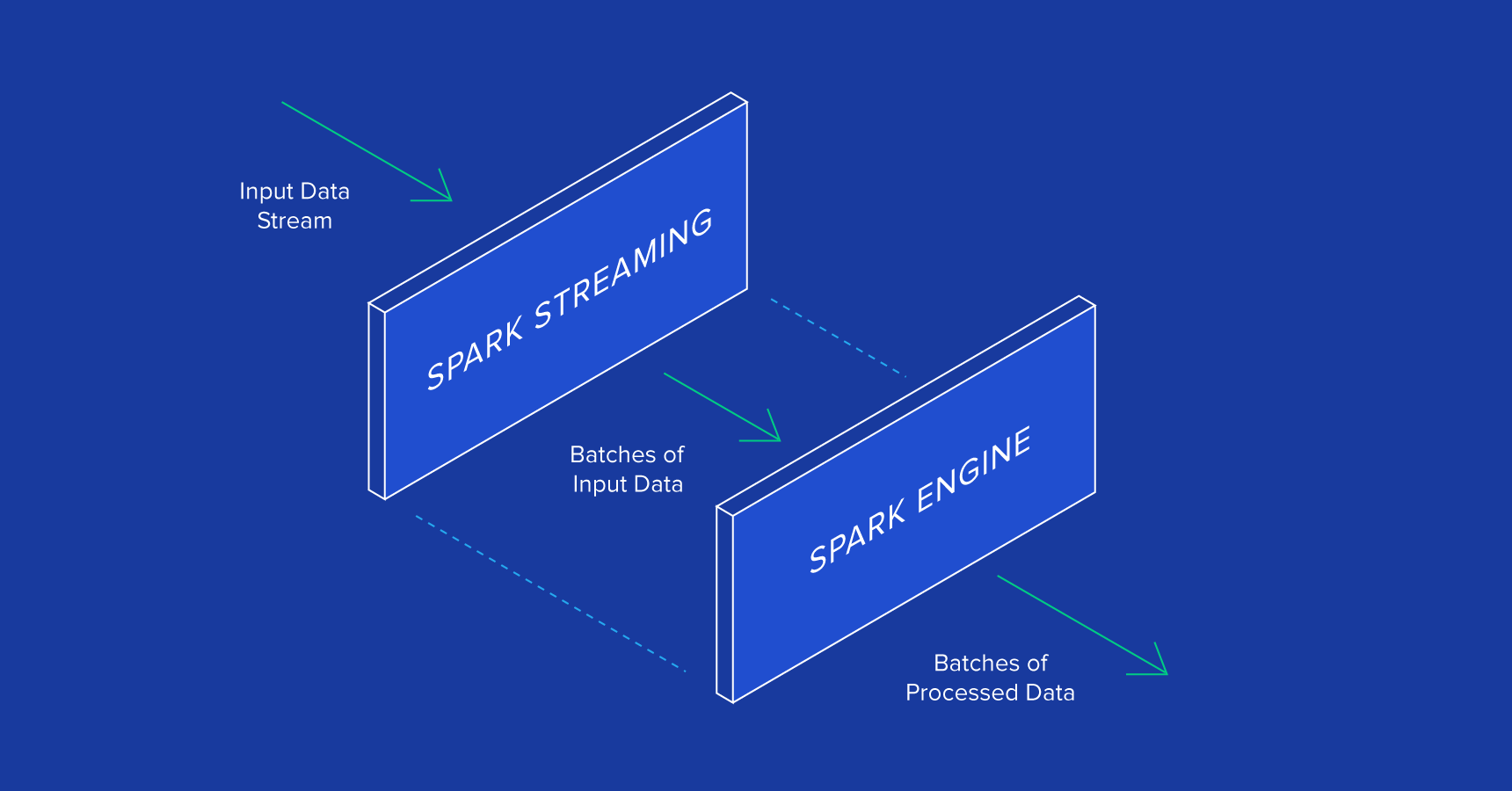
The Spark Streaming API resembles Spark Core – as a result, it becomes easier for programmers to tackle for batch and streaming data, effortlessly.
MLib
MLib is a versatile machine learning library that comprises of numerous fetching algorithms that are designed to scale out on a cluster for regression, classification, clustering, collaborative filtering and more. In fact, some of these algorithms specialize in streaming data, such as linear regression using ordinary least squares or k-means clustering.
GraphX
An exhaustive library for fudging graphs and performing graph-parallel operations, GraphX is the most potent tool for ETL and other graphic computations.
Want to learn more on Apache Spark? Spark Training Course in Gurgaon fits the bill. No wonder, Spark simplifies the intensive job of processing high levels of real-time or archived data effortlessly integrating associated advanced capabilities, such as machine learning – hence Apache Spark Certification Training can help you process data faster and efficiently.
The blog has been sourced from ― www.toptal.com/spark/introduction-to-apache-spark
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.