In the last blog that covered Part 1 of the visualization series using Python programming language, we have learned the basics of the Matplotlib Library. Now that our grasp on the basics is strong we would move further. Let’s break it all down with a more formal introduction of Matplotlib’s Object Oriented API. This means we will instantiate figure objects and then call methods or attributes from that object.
Introduction to the Object Oriented Method
The main idea in using the more formal Object Oriented method is to create figure objects and then just call methods or attributes off of that object. This approach is nicer when dealing with a canvas that has multiple plots on it.
How to make multiple plots using .add_axes()
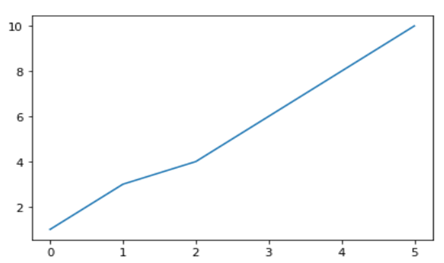
To begin, we create a figure instance. Then we can add axes to that figure where .figure()is a method which helps us create an empty canvas and then we use .add_axes() method to give the position where the plot is to be made. The positional arguments [left, bottom, width, height] help us decide from where the graph should begin within the canvas and what should be the width and the height of the graph. Since the area of the graph is 100% (1.0), the range of the positional argument should be between 0 and 1 and in case you want to plot the graph half within and half outside the canvas, you can go beyond the specified range depending upon your needs.
Let’s quickly get to the coding part now.
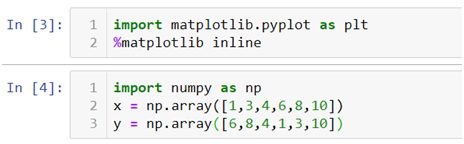
- In the above line of codes we are simply importing the Matplotlib library and creating a data which we want to plot.

- plt.figure()method is helping us create an empty canvas and then we are giving the positional values to the .add_axes() method. As you can see we are using a variable named fig to save our canvas and then using the same variable as an object to add an axes to the canvas. Now all we need to do is use that axes to build are graph by adding x and y data.
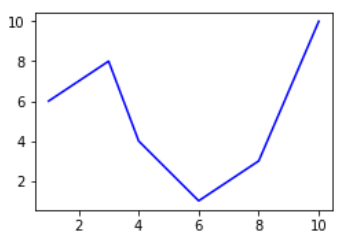
- Now you must be wondering why we aren’t able to see a plot in the corner of the canvas? It is because this procedure works only if we were to build multiple plots. So now let’s see how we can use the .add_axes() method to build multiple plots on top of each other.

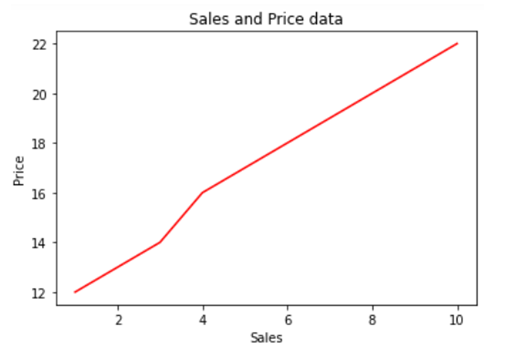
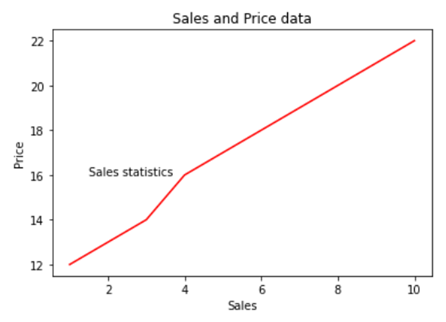
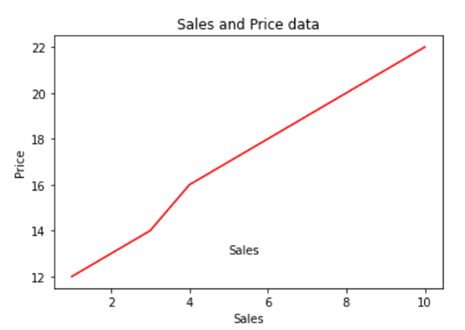
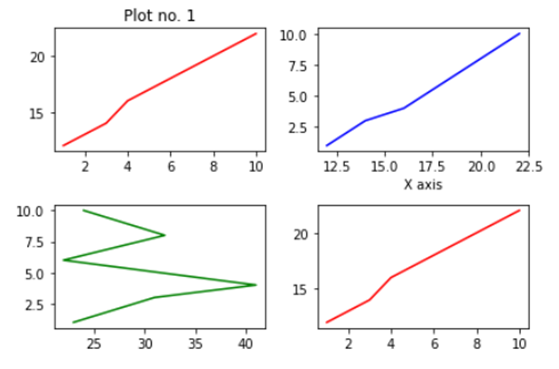
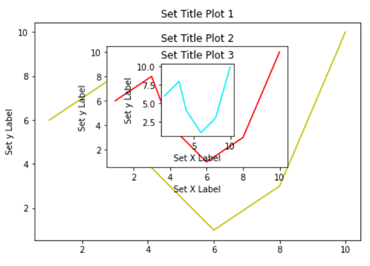
- In the above line of codes we are creating three axes and each axes is smaller than the other so that we are able to plot multiple graphs on top of each other.

- Here we are making three different graphs and each graph has its own title and x axis and y axis labels. But to add title and axis labels we are now using .set_title(), .set_xlabel(), and .set_ylabel() instead of .title(), .xlabel() and .ylabel(). In axes2.plot() we are also using RGB color instead of using the predefined color in .plot() method. You can use your favorite color too by simply typing RGB color picker in your Google search and copy pasting the color code in the .plot() method. After running the above code we get the following graph:-
How to make multiple plots using .subplots()
.subplots() method is similar to the previous .subplot() method, the only difference is that now we use it on a canvas.

- In the .subplots() we do not mention the plot number instead we use plot indexing method to build graph.

- As you can see we are accessing the index number to build our plot and then using .tight_layout() method to keep the graphs from overlapping. After running the above code we get the following graphs:-
Do not forget to check out the video tutorial attached below to learn how this method works. Keep following the series to upgrade your skills and to explore more informative posts on topics like Python Programming training you need to follow the Dexlab Analytics blog.
.