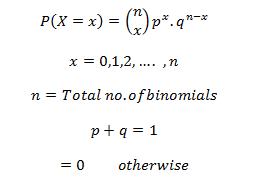
Gauss, the famous French Mathematician is responsible for developing one of the most significant distributions in all of statistics, i.e. – The Normal Distribution. Please refer to the blog on Central Limit Theorem: www.dexlabanalytics.com/blog/the-almighty-central-limit-theorem. It will help you fully grasp the significance of the Normal Distribution. However, if you want to revisit our series of blogs by following it from the start, you can reach STATISTICAL APPLICATION IN R & PYTHON: CHAPTER 1 – MEASURE OF CENTRAL TENDENCY right now!
Essentially, the Normal Distribution provides “approximations” to most other distributions such as the Binomial, Poisson, Gamma, Exponential, etc. This is to say as sample sizes get statistically large enough, most distributions approximate into a normal shaped curve.
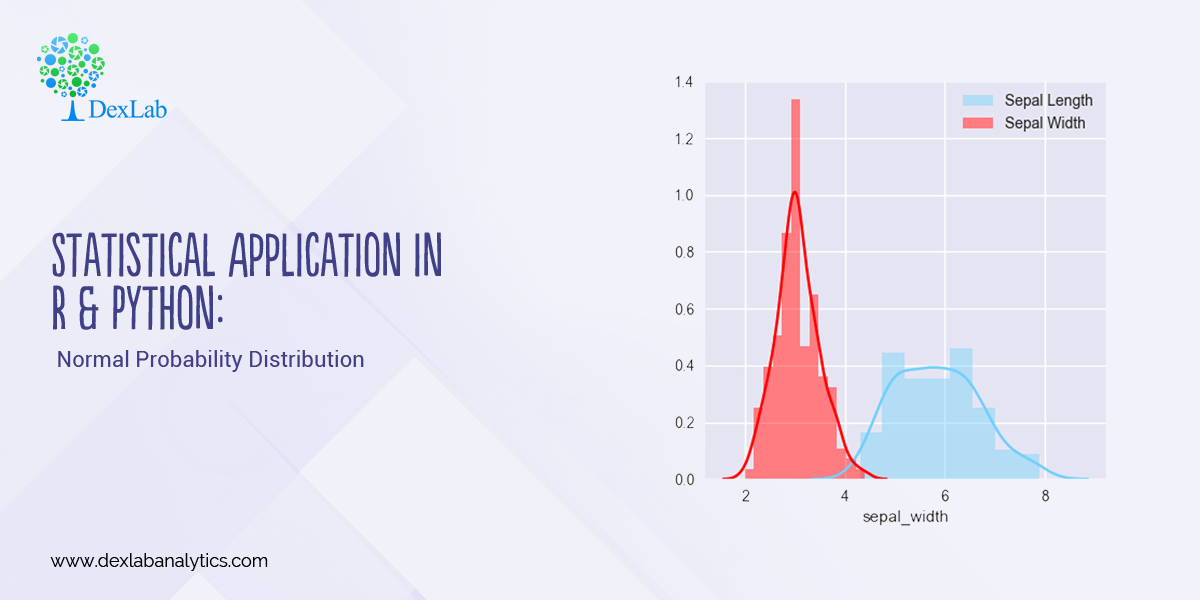
Every distribution has important features known as its “parameters”. Normal distribution has two parameters. These are Mean ( ) and Variance (σ²). The normal distribution has a bell-shaped curve, where the probability of likelihood peaks at its mean in the middle.
The Normal Distribution has vast practical applications in the field of Business, Finance, Medicine, and Physics and so on. Things like weights, heights, IQ scores follow the Normal Distribution.
Normal Distribution, Gaussian distribution, is a continuous probability distribution and is defined by the Probability Density Function (PDF).
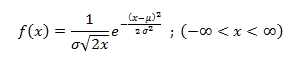
Where,
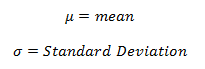

Application:
Assume that the credit score fits a Normal Distribution.
Suppose Mr. Arjun’s last 10 month’s credit score are:
789, 635, 739, 687, 724, 810, 817, 735, 819, 820
What is the probability that the percentage of credit score will 825 or more in the 11th month?
Months | Credit Score |
January | 789 |
February | 635 |
March | 739 |
April | 687 |
May | 724 |
June | 810 |
July | 817 |
August | 735 |
September | 819 |
| October | 820 |

Calculating Normal Distribution in R:
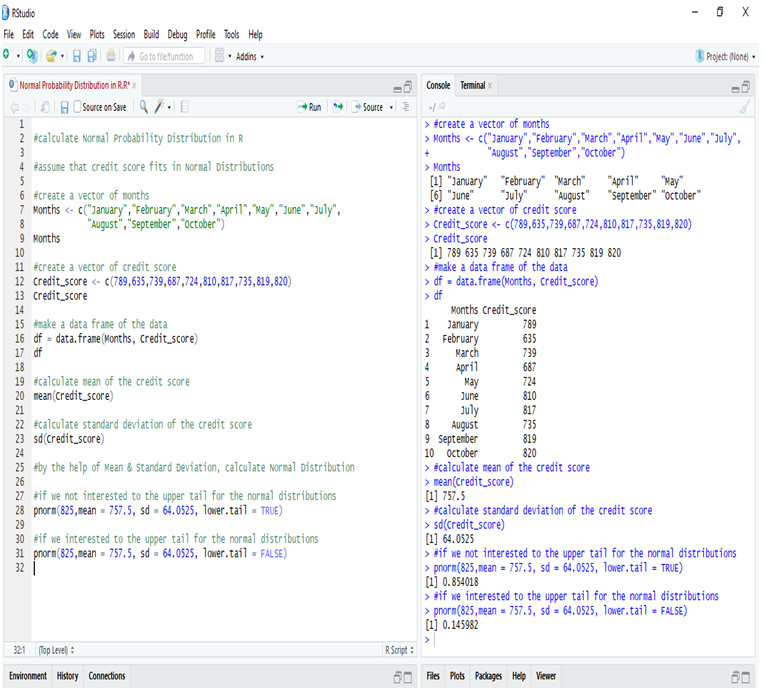
If we go to calculate Normal Probability Distribution in R, we can predict that the probability of the 11th month credit score will be 825 or greater than that is 14.60%, whereas in another case, the probability of the 11th month credit score will be 825 or less than that is 85.40%.
Calculate Normal Distribution in Python:
Make a data frame of the data and calculate Mean and Standard Deviation for calculate Normal Distribution.
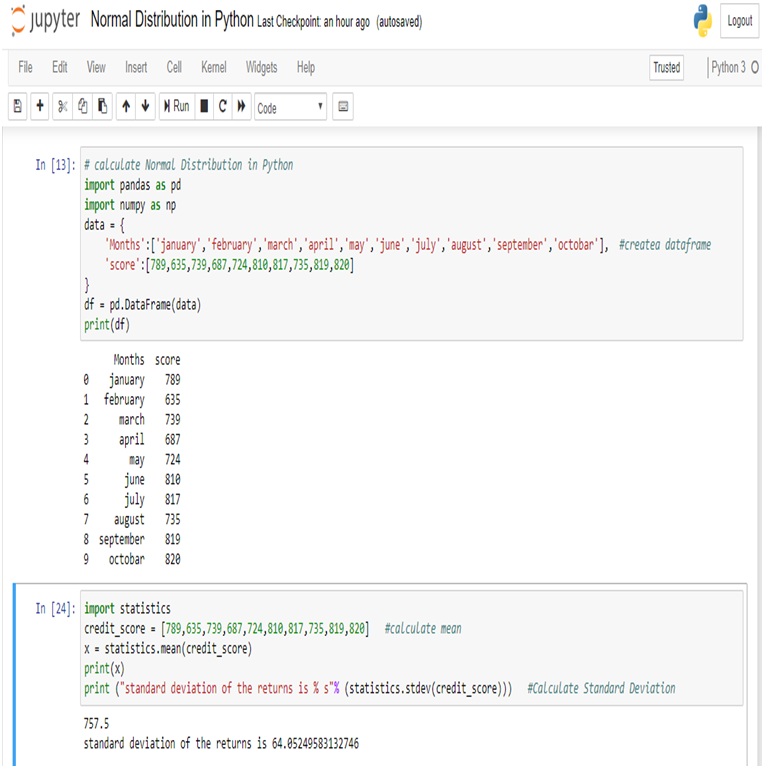
Now, we can easily calculate Normal Distribution in Python
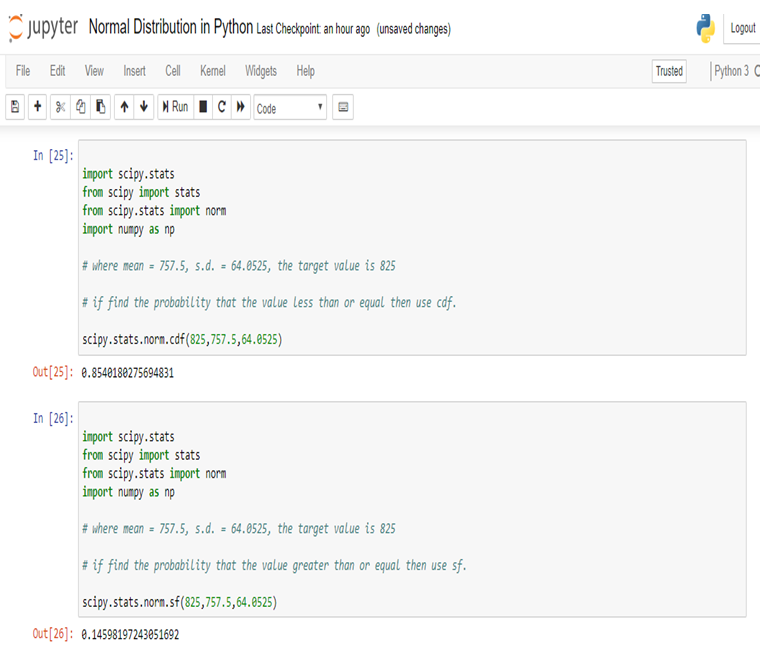
So, in calculating the Normal Probability Distribution in Python, we can predict that the probability of the 11th month credit score will be 825 or greater than that is 14.60%, whereas in another case, the probability of the 11th month credit score will be 825 or less than that is 85.40%.
Conclusion:
Normal Distribution is used for calculating parameters. It is represented by the bell curve, where the total area of the curve is 1. Normal Distribution has its use in Finance, Business, Salaries, Blood Pressures, Measurement etc and many other fields.
Here, we have used Normal Distribution to predict Mr. Arjun’s 11th month credit score, and set the target (825). By Normal Distribution we can predict the percentage of possibility to achieve the target.
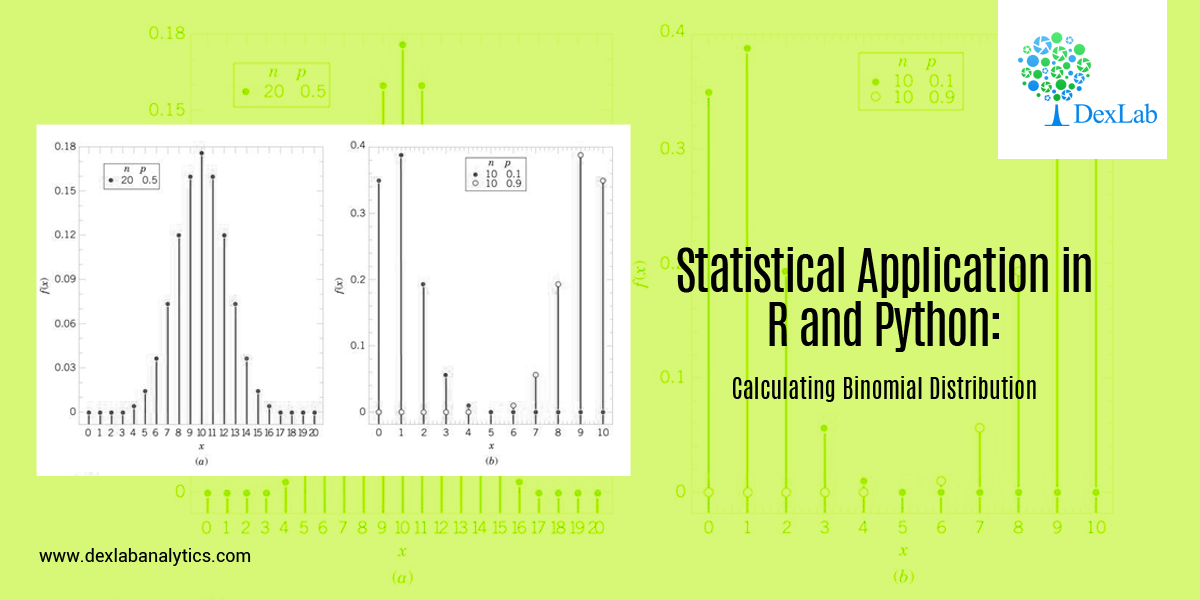
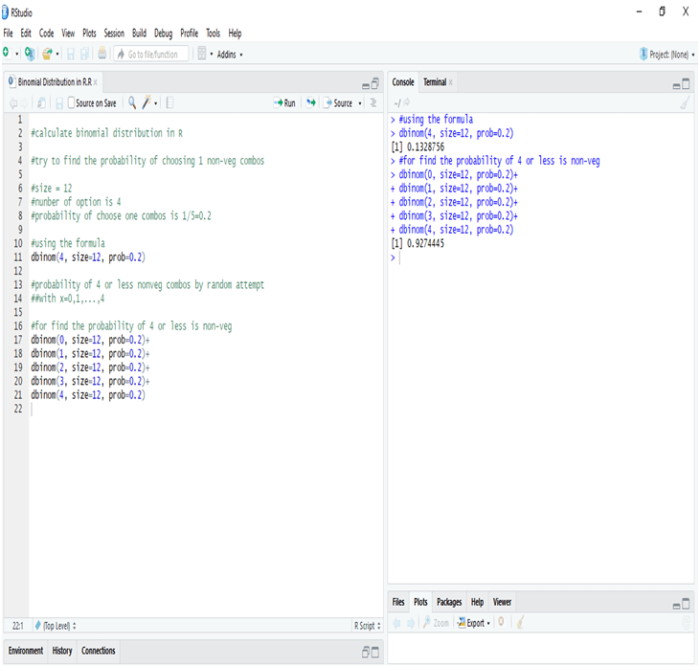
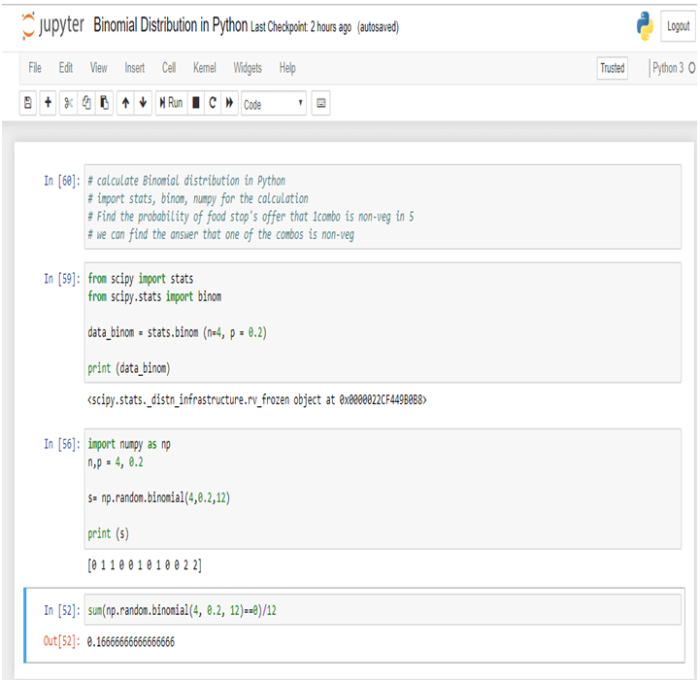
Calculating Binomial Distribution might be tricky for many but with Dexlab Analytics it won’t be hassle anymore. So, get hold of our STATISTICAL APPLICATION IN R AND PYTHON: CALCULATING BINOMIAL DISTRIBUTION blog, to get around all your problems.
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.