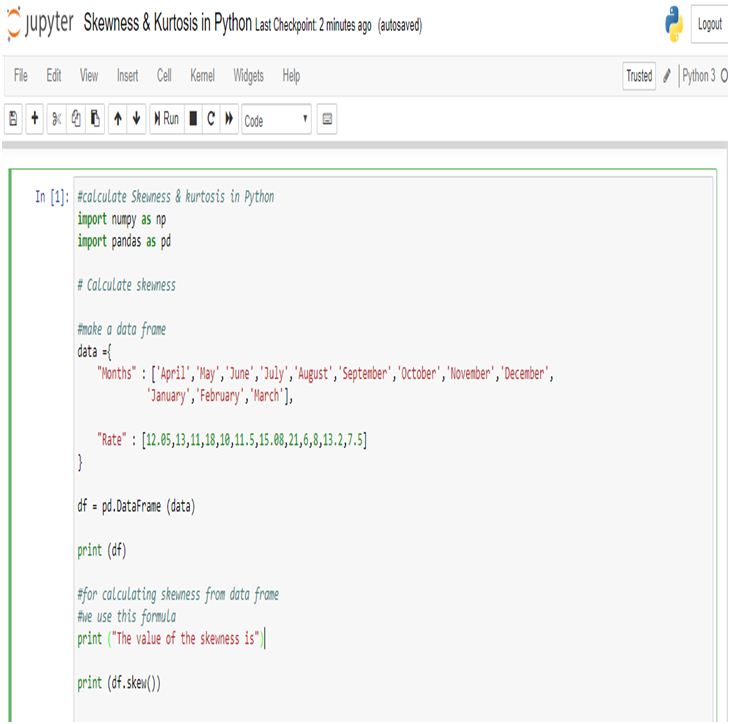
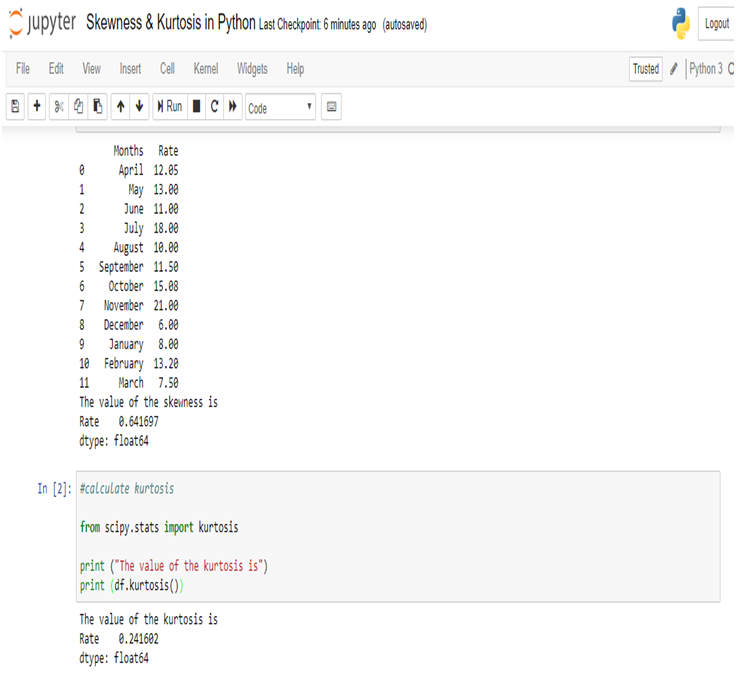
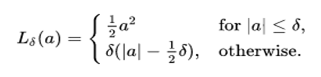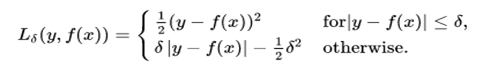Among all the decisions we make in our lives, choosing the right career path seems to be the most crucial one. Except for a couple of clueless souls, most students know by the time they clear their boards what they aspire to be. A big chunk of them veer towards engineering, MBA, even pursue masters degree in academics and post completion of their studies they settle for relevant jobs. So far that used to be the happily ever after career story, but, in the last couple of years there seems to be a big paradigm shift and it is causing a stir across industries. Professionals having an engineering background, or, masters degree are opting for a mid-career switch and a majority of them are opting for the data science domain by pursuing a Data Science course. So, what’s pushing them towards DS? Let’s investigate.
What’s causing the career switch?
No matter which field someone has chosen for career, achieving stability is a common goal. However, in many fields be it engineering, or, something else the job opportunities are not unlimited yet the number of job seekers is growing every year. So, thereby one can expect to face a stiff competition grabbing a well-paid job.
There have been many layoffs in recent times especially due to the unprecedented situation the world is going through. Even before that there were reports of job cuts and certain sectors not doing well would directly impact the career of thousands. Even if we do not concentrate on the extremes, the growth prospect in most places could be limited and achieving the desired salary or, promotion oftentimes becomes impossible. This leads to not only frustration but uncertainty as well.
The demand for big data
If you haven’t been living as a hermit, then you are aware of the data explosion that impacted nearly every industry. The moment everyone understood the power of big data they started investing in research and in building a system that can handle, store and process data which is a storehouse of information. Now, who is going to process data to extract the information? And here comes the new breed of data experts, namely the data scientists, who have mastered the technology having undergone Data Science training and are able to develop models and parse through data to deliver the insights companies are looking for to make informed decisions. The data trend is pushing the boundaries and as cutting edge technologies like AI, machine learning are percolating every aspect of the industries, the demand for avant-garde courses like natural language processing course in gurgaon, is skyrocketing.
Lack of trained industry ready data science professionals
Although big data has started trending as businesses started gathering data from multiple sources, there are not many professionals available to handle the data. The trend is only gaining momentum and if you just check the top job portals such as Glassdoor, Indeed and go through the ads seeking data scientists you would immediately know how far the field has traveled. With more and more industries turning to big data, the demand for qualified data scientists is shooting up.
Why data science is being chosen as the best option?
In the 21st century data science is a field which has plethora of opportunities for the right people and this is one field which is not only growing now but is also poised to grow in future as well. The data scientist is one of the most highest paid professional in today’s job market. According to the U.S. Bureau of Labor Statistics report by the year 2026 there is a possibility of creation of 11.5 million jobs in this field.
Now take a look at the Indian context, from agriculture to aviation the demand for data scientists would continue to grow as there is a severe shortage of professionals. As per a report the salary of a data scientist could hover around ₹1,052K per annum and remember the field is growing which means there is not going to be a dearth of job opportunities or, lucrative pay packages.

The shift
Considering all of these factors there has been a conscious shift in the mindset of the professionals, who are indeed making a beeline for institutes that offer data science certification. By doing so they hope to-
- Access promising career opportunities
- Achieve job satisfaction and financial stability
- Earn more while enjoying job security
- Work across industries and also be recruited by industry biggies
- Gain valuable experience to be in demand for the rest of their career
- Be a part of a domain that promises innovation and evolution instead of stagnation
Keeping in mind the growing demand for professionals and the dearth of trained personnel, premier institutes like DexLab Analytics have designed courses that are aimed to build industry-ready professionals. The best thing about such courses is that you can hail from any academic background, here you will be taught from scratch so that you can grasp the fundamentals before moving on to sophisticated modules.
Along with providing data science certification training, they also offer cutting edge courses such as, artificial intelligence certification in delhi ncr, Machine Learning training gurgaon. Such courses enable the professionals enhance their skillset to make their mark in a world which is being dominated by big data and AI. The faculty consists of skilled professionals who are armed with industry knowledge and hence are in a better position to shape students as per industry demands and standards.
The mid-career switch is happening and will continue to happen. There must be professionals who have the expertise to drive an organization towards the future by unlocking their data secrets. However, something must be kept in mind if you are considering a switch, you need to be ready to meet challenges, along with knowledge of Python for data science training, you need to have a vision, a hunger and a love for data to be a successful data scientist.
.