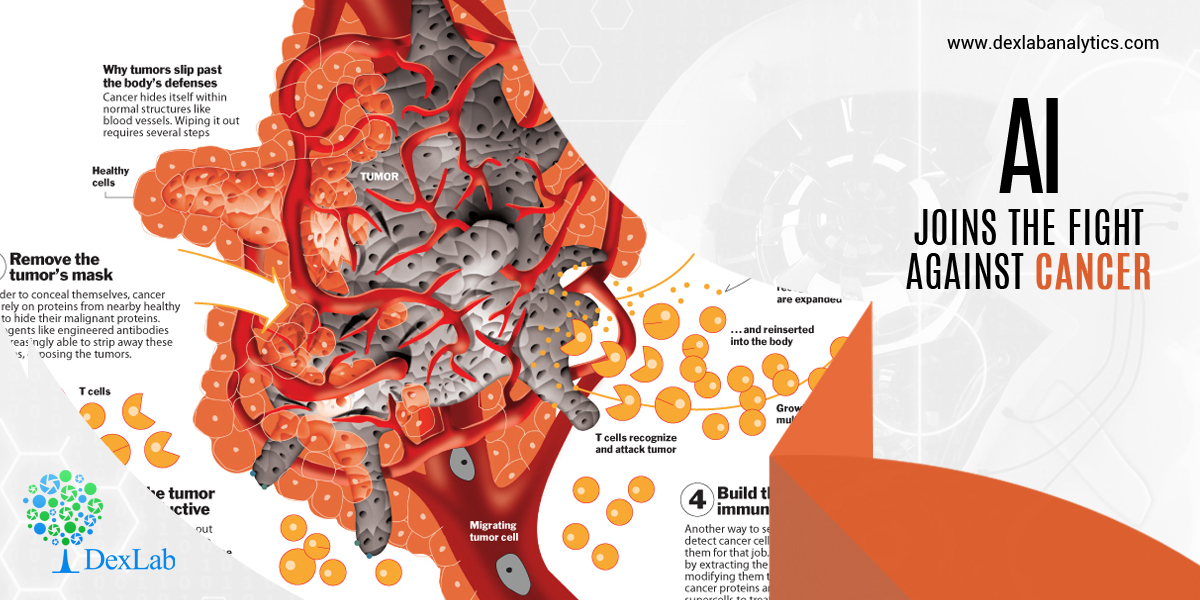
Cancer is the emperor of all maladies. Finding a cure to it is one of the biggest challenges in the world of medicine. More and more men and women, one in five men and one in six women worldwide likely to be afflicted, are falling prey to the malady. It is something that has spurred on the fight against the disease even more intensely. AI and machine learning has increased the scope of groundbreaking research in the field and it is worth knowing a little about.
One reason why AI, which has made inroads into numerous sectors of the economy, has made immense advancements in the field of medical oncology is the vast amount of data generated during cancer treatment. With the assistance of AI, say scientists, this vast trove of data can be mined and worked to improve methods of diagnosis and preventive cures and treatments.
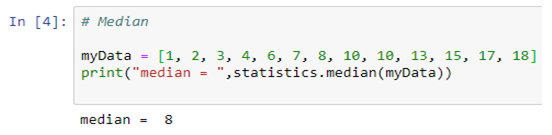
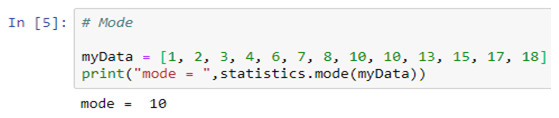
Detection of Cancer
Machine learning can lead to early detection and timely treatment in many cases. Because cancer is treated in stages, unlike other diseases, machine learning can come in handy when it comes to detection of precancerous lesions in tissues.
AI utilizing tools can assist radiologists in graphically and visually studying images by revealing suspicious lesions. This process not only reduces the work load of radiologists but it also makes possible the detection of miniscule lesions which could otherwise be overlooked.
Detection of Breast Cancer
“DeepMind and Google Health collaborated to develop a new AI system that helps in detecting breast cancer accurately at a nascent stage. Being the most common cancer in women, breast cancer, has seen an alarming rise over the past few years. Though early detection can improve a patient’s prognosis significantly, mammography, which is the best screening test currently available, is not entirely error-proof”, says a report.
To correct this, researchers at DeepMind and Google Health designed an algorithm on mammogram images and noticed AI systems reduced the recurrence of errors. They discovered that AI systems functioned better than human radiologists. A few startups in India are also laboring in the arena of cancer detection.
Predicting Cancer Evolution
Besides detection, AI is useful in the treatment of cancer as well. It is critical to the survival of patients in that it is used to predict growth and evolution of cancers which could help doctors prepare a treatment plan and save lives.
Identifying Effective Treatments
AI can play a significant role in the overall treatment of the patient, especially precision medicine which is the administering of personalized medicine from a pool of generic medication beneficial to the patient. AI can also be used to design new drugs.
Thus, AI has created a huge potential for changing the mode of treatment of cancer patients. According to the report, Exscientia is the first company, globally, to have overtaken conventional drug designing processes by automating the whole process using AI. Another company is trying to do the same in Bangalore.

It is no surprise then that AI is being even more widely adopted across sectors of healthcare and medicine. More and more professionals, the world over, are enrolling in courses teaching AI, deep learning and machine learning. For the best such institute in India, or for the best artificial intelligence training institute in Gurgaon, do not forget to visit the DexLab website today.
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.