Today we are going to learn about the new feature of Scikit-learn version 0.22 called KNN Imputation. This feature now enables us to support imputation for completing missing values using k-Nearest Neighbours (KNN). To track our tutorials on other new releases from scikit-learn, read our blog here and here.
Introduction
Each sample’s missing values are imputed using the mean value from nearest neighbours found in the training set. Two samples are close if the features that are neither missing are close. By default, a Euclidean distance metric that supports missing values, nan_euclidean_distances, is used to find the nearest neighbours.
Input and Output
So, what we do first is to import libraries like NumPy and run them. Then we create as many rows as we wish to. Then we run the function KNN Imputer and we can decide how many neighbours we want. We first, as is the procedure to use scikit-learn goes, create an object and then run it. Then we can directly put the input values in imputer.fit_transform and get the output values in the form of patterns detected in the input values.
The code sheet for this tutorial is provided in a Github repository here
For more on this do watch the video attached herewith. This tutorial was brought to you by DexLab Analytics. DexLab Analytics is a premiere Machine Learning institute in Gurgaon.
In the first part of this blog, we covered Parametric and Non-Parametric Machine Learning algorithms and Supervised and Unsupervised Machine Learning Algorithms. If you haven’t gone through it yet, check it out here: dexlabanalytics.com/blog/machine-learning-algorithms-with-python-part-i
In this blog we are going learn about Semi Supervised Machine Learning algorithms.
What are Semi Supervised ML algorithms?
Those algorithms in which only half of the historical data’s target data has been specified are called semi-supervised algorithms. The way to go about solving this is by making a model on the basis of the portion of historical data that has the target specified and then apply this model to the rest of the data to predict the outcomes. Now, combine the two sets of data, get the target variable and make a model on the basis of this target variable.
New Nomenclature
In the equation Y= B0 + B1X, Y is called the Target Variable while in statistics it is called the Dependent Variable. And X is called Features or Attributes whereas in statistics it is called Independent Variable. B0 and B1 are called Weights while in statistics they are called Coefficients (Intercept and Slope, respectively).
In the equation Ÿ – Y = error, the error in statistics is called Residual but in Machine Learning it is called Cost Function. And the elements of the historical data set that in statistics are known as Records or Observations, in machine learning are known as Instances.
What is Bias Variance Trade-Off?
In parametric algorithms like linear regressions, several assumptions are made before building a model. These assumptions can be things like having only those inputs that have a relationship with the target variable or the fact that the error should be random. The benefit of this process is the fact that Ÿ or the predicted results are consistent and there is not much variance in them.
Now, if we are to take a Decision Tree or any other non-parametric Machine Learning algorithm, a small change in the data set forces a large variance in the Target variable. But, unlike in parametric ML algorithms, there are no basic assumptions in non-parametric assumptions. So, in such a case, the error or mean square error, is a combination of the square of bias and variance.
MSE = Bias2 + Variance
Increasing any one (the square of the bias) will lead to a decrease in the other (variance) and vice versa.
In this case, we need to balance or trade off the two – the square of the bias and the variance.
While the bias cannot be changed much, we can control the variance by increasing or decreasing the parameters of the experiment.
What is Overfitting and Underfitting?
Overfitting is the condition when the accuracy figure of the ‘trained’ data set is larger in number than the accuracy figure of the ‘tested’ unseen data set. This is an undesirable condition. Underfitting is the opposite wherein the accuracy figure of the trained data is lower than that of the tested unseen data. This is also undesirable. What we seek to aim at is an equal accuracy in both the tested and trained models.
To limit Overfitting we must –
Use a resampling technique to estimate model accuracy by repeating experiments with the data and then drawing an average of the accuracy figures.
Hold back a validation data set to test your model on and increase the number of models to experiment on the trained data set.
We would like to conclude out second part of this tutorial here. For more on this, visit the third blog on Machine Learning Algorithms with Python.
Our industry experts introduce beginners to Machine Learning Algorithms with Python. In this blog, we will go through various Machine Learning Algorithms to understand the concepts better. This is the first part of a series.
Machine Learning, a subset of Artificial Intelligence, is a process of data analysis that automates analytical model building. It is a branch of artificial intelligence based on the idea that computing systems can learn from data, identify patterns in them and make intelligent decisions with minimal human intervention.
Parametric and Non-Parametric ML Algorithms
We first divide the mathematical methods for decision making in to sections – parametric and non-parametric algorithms. Parametric has a functional form while non-parametric has no functional form.
Functional form comprises a simple formula like 2+2=4 or Y=F(X). So if you input a value, you are to get a fixed output value. That means, if the data set is changed or being changed, there is not much variation in the results. But in non-parametric algorithms, a small change in data sets can result in a large change in the results.
But we do not desire this. We do not want this massive change in results in investments, for instance. We have various ways to solve this difficulty. For example, in statistics, you must have learnt the Central Limit Theorem – As the number of samples increase, the data will start following the normal distribution.
Here is an experiment on decision making with the help of non-parametric algorithm. We first take a random sample, and we apply an algorithm to it to get a result. We repeat this process several times and get an average of the results. In this way, the variation in our results goes down considerably. We will get a central tendency.
Take for example stock market data where prices are totally random. There is no fixed pattern to it. It is a manmade phenomenon. In the same way, we can make predictions in data sets only when there is a particular pattern. It becomes that much more difficult to make predictions in the absence of a clear pattern. In such a case, we take thousands of samples and work them to get a result before investing. We can use a Decision Tree like Random Forest for this.
Supervised and Unsupervised Algorithms
Now, secondly, we can term ML algorithms as supervised or unsupervised algorithms. Suppose we have data under sub-heads – Name, Age, Gender and Salary and Period of Service. Now, consider the model wherein we are asked to predict the period of service of an employee based on data provided under the rest of the sub-heads based on existing employee data.
Now, in this example, the period of service is the Target. The data sets on the basis of which the prediction will be made – Name, Age, Gender, Salary – is the Input. In such a model, where the target variable is specified, we term it as supervised machine learning algorithm. We do this according to a formula – Y=B0 + B1X1.
In unsupervised learning, the target variable is not provided and all we can do is divide the historical data in clusters. For example, Google Translate runs on a supervised model as do chatbots. Data is not only the new oil, it is everything. And there will come a time of data colonisation whereby the organisation with the best data will rule. The better the date, the better our ML models. Who has the best data sets in the world? Google and Amazon, among others, do.
So this is it, about supervised and unsupervised machine learning. For more on this, do watch our intensive video tutorial on ML algorithms.
(Translated till first 28:00 minutes)
This is the first blog of the series, stay tuned with Dexlab Analytics to read through the whole video we’ll covering in our upcoming blogs!
Today we are going to learn about the new releases from Scikit-learn version 0.22, a machine learning library in Python. We, through this video tutorial, aim to learn about the much talked about new release wherein ROC-AUC curve supports Multi Class Classification. Prior to this version, Scikit-learn did not have a function to plot the ROC curve.
To access our previous tutorial on the plotting of the ROC curve, click here.
The ROC-AUC score function can also be used in multi-class classification. Two averaging strategies are currently supported: the one-vs-one (OvO) algorithm computes the average of the pairwise ROC AUC scores and the one-vs-rest (OvR) algorithm computes the average of the ROC AUC scores for each class against all other classes.
In both cases, the multiclass ROC AUC scores are computed from probability estimates that a sample belongs to a particular class according to the model. The OvO and OvR algorithms support weighting uniformly (average=’macro’) and weighting by prevalence (average=’weighted’).
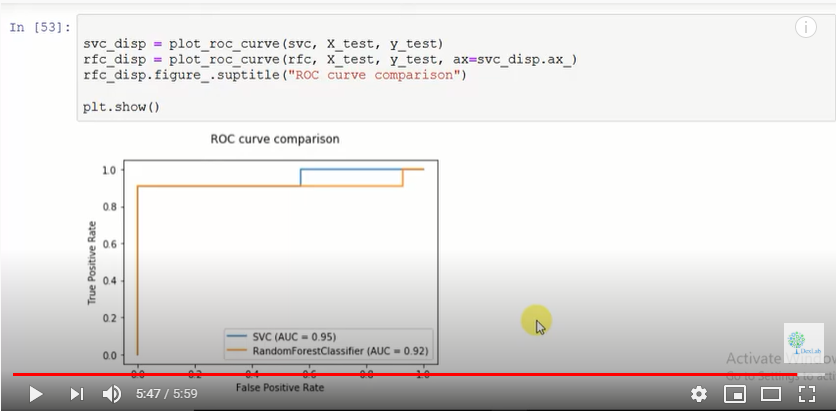
To begin with, we import multi classification, SVC and roc_auc_score. Then we specify the number of classes we want in the multi-classification function. Then we apply the SVC function and finally the roc_auc_score one. This function will give us the probable prediction for all the classes and we will then choose the one that has the highest probability. When we run it we get a ROC_AUC score of 0.99.
The code sheet is provided in a Github repository here.
Today we are going to learn about the new releases from Scikit-learn version 0.22, a machine learning library in Python. We, through this video tutorial, aim to learn about the much talked about new release called Plotting API. Prior to this version, Scikit-learn did not have a function to plot the ROC curve.
A new plotting API is available for creating visualizations. The new API allows for quickly adjusting the visuals of a plot without involving any recomputation. It is also possible to add different plots to the same figure. In this tutorial we are going to study the plotting of the ROC curve.
The code sheet is provided in a Github repository here.
We will attempt to plot the ROC curve on two different algorithms and compare which one is a better function. First we choose to make a classification data. Then we go on to plot the ROC curve using SVC classifier and then further plot the curve using a random forest classifier.
Today we are going to learn about the new releases from Scikit-learn version 0.22, a machine learning library in Python. First we learn how to install it on our systems. Then, we come to the much talked about new release called stacking regression.
Now, how does stacking regression work? Well, you have been using machine learning algorithms like Decision Tree or Random Forest. Have you heard of Voter Classifier? It is an algorithm in Scikit-learn. Ensemble algorithm is a combination of two or more algorithms to make it stronger.
When working on a set of data, we must apply all these algorithms to get predicted values. Then we vote out classified predicted values in Voter Classifier. Stacking Classifier is different. What we are doing in it is stacking together the predicted values to make a new input.
Initially, we make prediction by using various algorithms separately. Their results or output are then concatenated together. Then we use this output as a new input and apply the algorithms to it to get target variable. This method is known as stacking regression.
We try this out on a data set that can be taken from a github repository the link to which is given below.
Then we use two algorithms as estimators. Then we use stacking regression to build a model. For more on this do watch the video attached herewith. This tutorial was brought to you by DexLab Analytics. DexLab Analytics is a premiere Machine Learning institute in Gurgaon.
Chatbots or “conversational agents” are software applications that mimic or imitate written or spoken human speech for the purposes of facilitating a conversation or interaction with a human being.
These applications have become one of the most ubiquitous software applications out there with the advancement of machine learning technology and NLP.
“Today’s chatbots are smarter, more responsive, and more useful – and we’re likely to see even more of them in the coming years… chatbots are used most commonly in the customer service space, assuming roles traditionally performed by living, breathing human beings such as Tier-1 support operatives and customer satisfaction reps.”
Conversational agents are becoming a common occurrence partly due to the fact that barriers to entry in creating chatbots such as sophisticated programming knowledge have become redundant.
How Chatbots work
The crux of chatbot technology is natural language processing or NLP, the same technology “that forms the basis of the voice recognition systems used by virtual assistants such as Google Now, Apple’s Siri, and Microsoft’s Cortana.” “Chatbots process the text presented to them by the user…infer what they mean and/or want, and determine a series of appropriate responses based on this information.”
Here are 5 companies using chatbots for various roles like marketing, communicating with marginalized groups and patients suffering from sleeplessness and memory loss.
Endurance
Russian technology company Endurance developed a companion chatbot to help dementia patients cope with decreased verbal ability. Many patients with Alzheimer’s disease use the chatbot to converse with. In turn, the chatbot identifies deviations in conversational patterns of the patient that might indicate a problem with memory and recollection.
Casper
Casper’s Insomnobot 3000 is a conversational agent that aims to help insomniacs by posing as a companion to talk to while the rest of the world sleeps. However, at this point, “Insomnobot 3000 is a little rudimentary.”
UNICEF
International child advocacy nonprofit UNICEF is using chatbots to help people living in developing countries speak out about the most urgent needs in their communities. The bot, named U-Report, focuses on large-scale data gathering via polls. UNICEF then uses feedback as the basis for potential policy recommendations.
MedWhat
This chatbot aims at making medical diagnoses faster, easier, and more transparent for both patients and physicians. MedWhat is powered by a highly sophisticated machine learning system that offers increasingly accurate responses to user questions based on behaviors that it “learns” by interacting with human beings. Also, it acts as a repository of a vast source of medical journals and medical advice.
Roof Ai
Roof Ai is a chatbot that helps real-estate marketers to “automate interacting with potential leads and lead assignment via social media”. The bot identifies potential leads via social media and responds immediately, irrespective of the time of the day. “Based on user input, Roof Ai prompts potential leads to provide a little more information, before automatically assigning the lead to a sales agent.”
Machine Learning is an acquired knowledge science. It has to be taught and studied. For this, it is imperative to have the best books on the subject at hand. However, most books on the subject are expensive and not easily accessible. This is only fair given the amount of hard word that goes into writing these books.
In a situation this critical, it is best to rely on the good old Internet for assistance. There are some good Samaritans who have chosen to make their works freely available to all. Here is a great guide to free ebooks available online so you can brush up on your concepts and be industry ready at the earliest.
Think Stats – Probability and Statistics for Programmers by Allen B Downey
This is an introduction to statistics and probability for those who have a basic grounding in Python programming. “It’s based on a Python library for probability distributions (PMFs and CDFs). To make things easier for the reader, most of the exercises have short programs,” says a report.
Bayesian Reasoning and Machine Learning by David Barber
When it comes to Bayesian statistics, this book is a classic. “This takes a Bayesian statistics approach to machine learning.”This is a book worth checking out for anyone getting into the machine learning field and trying to make a career out of the subject.
An Introduction to Statistical Learning by Gareth James, Daniela Witten, Trevor Hastie and Robert Tibshirani
This popular entry is an introduction to data science through machine learning. “This book gives clear guidance on how to implement statistical and machine learning methods for newcomers to this field. It’s filled with practical real-world examples of where and how algorithms work. For those with an inclination towards R programming, this book even has practical examples in R.”
Understanding Machine Learning by ShaiShalev-Shwartz and Shai Ben-David
“This book gives a structured introduction to machine learning. It looks at the fundamental theories of machine learning and the mathematical derivations that transform these concepts into practical algorithms. Following that, it covers a list of ML algorithms, including…stochastic gradient descent, neural networks, and structured output learning.”
A Programmer’s Guide to Data Mining by Ron Zacharski
This book has chapters covering recommendation systems. “It takes a…visually entertaining look at social filtering and item-based filtering methods and how to use machine learning to implement them. Other concepts like Naive Bayes and Clustering are also covered. There is a chapter on Unstructured Text and how to deal with it, in case you are thinking about getting into Natural Language Processing. Examples in Python are also available in case you want to practice.”
In the midst of a crisis as big as COVID-19 which has as per the current update taken more than 80,000 lives around the world and caused nations to go under a lockdown, machine learning and artificial intelligence has played a vital role in detecting COVID-19 positive cases and helping fast track the tests and analysis of drugs that can be a solution to the problem.
Countries around the world are building algorithms to better understand the molecular structure of the diseaseso that the so-called protein around the SARS-CoV-2, the virus that causes COVID-19, can be blocked.
Use of AI and machine learning around the world
The legendary story of a Canada-based AI named Bluedot is not something one can forget. Buledot is a low cost AI based tool that predicted the outbreak of the disease in December 2019 and also predicted the top 20 destinations where passengers from Wuhan, the origin of pandemic, would arrive.
Deargen a South-Korean company built an AI tool named MT-DTI to test and analyze the molecular bond of the SARS-CoV-2 protein and recommend medication on the basis of the same. Even though their recommendations are yet to be reviewed and tested properly, their find might prove to be a super solution to reduce the number of death counts and covid positive cases.
Insilico Medicine, a Hong-Kong based company instead of building a platform to recommend the currently available medication to break the protein of covid-19 virus and stop it from replicating, built an AI based tool to formulate and test the potency of new and chemically advanced medication to break the chain.
Benevolent AI, a British startup based on its machine learning tool discovered six important covid-19 virus fighting compounds that can prove to be helpful in curing and limiting the spread of the disease. Out of the six compounds discovered, ‘baricitinib’, a compound used to cure rheumatoid arthritis according to the sources, proves to be the safest compound that can be tested on the covid positive volunteers.
Use of AI and machine learning in India
The spread of the covid-19 pandemic in India began by the end of January 2020 and till date more than 5000 cases have been reported. The Government of India declared a lockdown by mid-March 2020 and in the middle of all this when misinformation and rumors were rising day by day, to tackle the problem the Government of India launched its covid-19 tracking app called Aarogya Setuthat means ‘a bridge of health’.
This AI-based app uses bluetooth and the mobile location of the user and informs them if there is any person covid positive within 6 feet of their location or not. The app checks the user’s data in their own database and in case the data matches a corona positive patient then it only notifies their presence keeping their identity anonymous.
India has also launched a whatsapp chatbot and any one using the whatsapp platform can access the chatbot by simply typing “MyGov Corona Helpdesk” and get the relevant and authentic information relating to the symptoms and how they can get help from direct sources.
Apart from the above initiatives to tackle the pandemic, medical practitioners, data analysts and data scientists from around the world are trying to find ways and means and analyzing the database to capture the trends and are working day and night to find best possible cure to fight the disease.