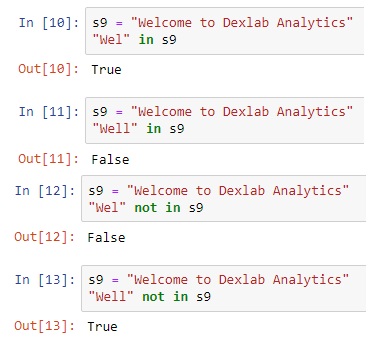
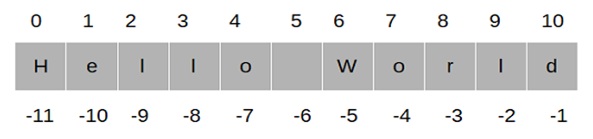
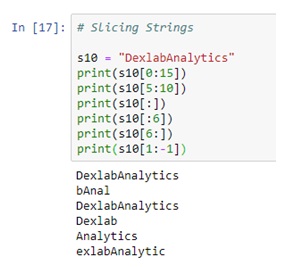
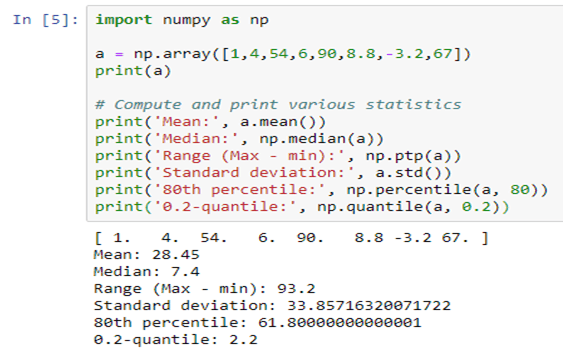
The world’s fight against extreme weather conditions and climate change is at the forefront of all discussions and debates on the environment. In fact, climate change is the biggest concern we are faced with today, and studying the climate has increasingly become the primary preoccupation of scientists and researchers. They have received a shot in the arm with the increase in the scope of artificial intelligence and deep learning in predicting weather patterns.
Take for instance the super cyclone Amphan that has ravaged West Bengal and Orissa. Had it not been for weather forecasting techniques, meteorologists would never had predicted the severity of the cyclone and the precautionary evacuation of thousands of people from coastal areas would not have been taken, leading to massive loss of lives. This is where the importance of weather forecasting lies.
Digitizing the prediction model
Traditionally, weather forecasting depends on a combination of observations of the current state of the weather and data sets from previous observations. Meteorologists prepare weather forecasts collecting a wealth of data and running it through prediction models. These sets of data come from hundreds of observations like temperature, wind speed, and precipitation produced by weather stations and satellites across the globe. Due to the digitization of these weather models, accuracy has improved much more than it was a few decades ago. And with the recent introduction of machine learning, forecasting has become an even more accurate and exact science.
Machine Learning
Machine learning can be utilized to make comparisons between historical weather forecasts and observations in real time. Also, machine learning can be used to make models account for inaccuracies in predictions, like overestimated rainfall.
At weather forecast institutions, prediction models use gradient boosting that is a machine learning technique for building predictive models. This is used to correct any errors that come into play with traditional weather forecasting.
Deep Learning
Machine Learning and Deep Learning are increasingly being used for nowcasting, a model of forecasting in the real time, traditionally within a two-hour time span. It provides precipitation forecasts by the minute. With deep learning, a meteorologist can anywhere in the vicinity of a weather satellite (which runs on deep learning technology) use nowcasting rather than just those who live near radar stations (which are used in traditional forecasting).
Extreme Weather Events
Deep learning is being used not only for predicting usual weather patterns, it is being used to predict extreme weather conditions as well. Rice University engineers have designed a deep learning computer system that has trained itself to predict, in accurate terms, extreme weather conditions like heat waves or cold waves. The computer system can do so up to five days in advance. And the most fascinating part is it uses the least information about current weather conditions to make predictions.
This system could effectively guide NWP (numerical weather prediction) that currently does not have the ability to predict extreme weather conditions like heat waves. And it could be a super cheap way to do so as well.
According to sciencedaily.com, with further development, the system could serve as an early warning system for weather forecasters, and as a tool for learning more about the atmospheric conditions that lead to extreme weather, said Rice’s Pedram Hassanzadeh, co-author of a study about the system published online in the American Geophysical Union’s Journal of Advances in Modeling Earth Systems.

Thus, it is no surprise then that machine learning and deep learning is being widely adopted the world over. In India, is it being taken up as a form of study and training in metropolitans like Delhi and Gurgaon. For the best Machine Learning course in Delhi and deep learning course in delhi, check out the DexLab Analytics website today.
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.