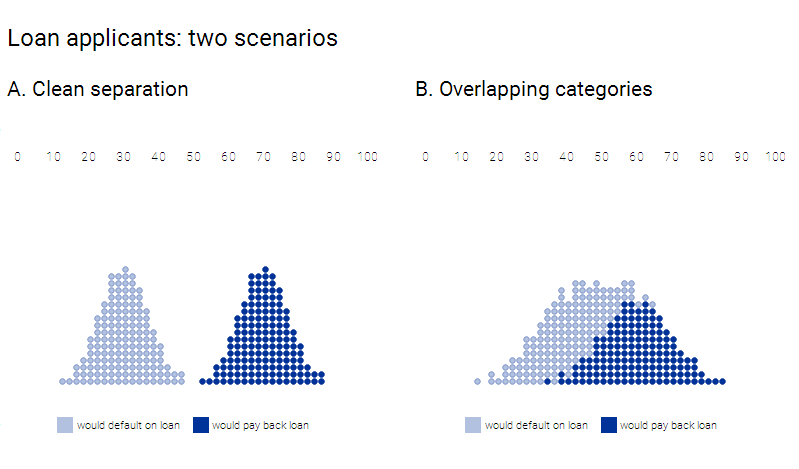
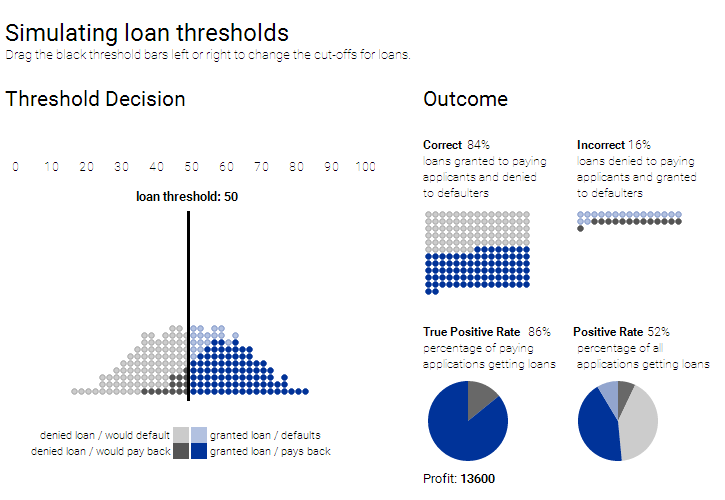
Recently, Deep Learning has gone up from just being a niche field to mainstream. Over time, its popularity has skyrocketed; it has established its position in conquering Go, learning autonomous driving, diagnosing skin cancer, autism and becoming a master art forger.
Before delving into the nuances of neural networks, it is important to learn the story of its evolution, how it came into limelight and got re-branded as Deep Learning.
The Timeline:
Warren S. McCulloch and Walter Pitts (1943): “A Logical Calculus of the Ideas Immanent in Nervous Activity”
Here, in this paper, McCulloch (neuroscientist) and Pitts (logician) tried to infer the mechanisms of the brain, producing extremely complicated patterns using numerous interconnected basic brain cells (neurons). Accordingly, they developed a computer-programmed neural model, known as McCulloch and Pitt’s model of a neuron (MCP), based on mathematics and algorithms called threshold logic.

Marvin Minsky (1952) in his technical report: “A Neural-Analogue Calculator Based upon a Probability Model of Reinforcement”
Being a graduate student at Harvard University Psychological Laboratories, Minsky executed the SNARC (Stochastic Neural Analog Reinforcement Calculator). It is possibly the first artificial self-learning machine (artificial neural network), and probably the first in the field of Artificial Intelligence.
Marvin Minsky & Seymour Papert (1969): “Perceptron’s – An Introduction to Computational Geometry” (seminal book):
In this research paper, the highlight has been the elucidation of the boundaries of a Perceptron. It is believed to have helped usher into the AI Winters – a time period of hype for AI, in which funds and publications got frozen.
Kunihiko Fukushima (1980) – “Neocognitron: A Self-organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position” (this concept is an important component for Convolutional Neural Network – LeNet)
Fukushima conceptualized a whole new, much improved neural network model, known as ‘Neocognitron’. This name is derived from ‘Cognitron’, which is a self-organizing multi layered neural network model proposed by [Fukushima 1975].
David B. Parker (April 1985 & October 1985) in his technical report and invention report – “Learning – Logic”
David B. Parker reinvented Backpropagation, by giving it a new name ‘Learning Logic’. He even reported it in his technical report as well as filed an invention report.
Yann Le Cun (1988) – “A Theoretical Framework for Back-Propagation”
You can derive back-propagation through numerous ways; the simplest way is explained in Rumelhart et al. 1986. On the other hand, in Yann Le Cun 1986, you will find an alternative deviation, which mainly uses local criteria to be minimized locally.
J.S. Denker, W.R. Garner, H.P. Graf, D. Henderson, R.E. Howard, W. Hubbard, L.D. Jackel, H.S. Baird, and I. Guyon at AT&T Bell Laboratories (1989): “Neural Network Recognizer for Hand-Written ZIP Code Digits”
In this paper, you will find how a system ascertains hand-printed digits, through a combination of neural-net methods and traditional techniques. The recognition of handwritten digits is of crucial notability and of immense theoretical interest. Though the job was comparatively complicated, the results obtained are on the positive side.
Yann Le Cun, B. Boser, J.S. Denker, D. Henderson, R.E. Howard, W. Hubbard, L.D. Jackel at AT&T Bell Laboratories (1989): “Backpropagation Applied to Handwritten ZIP Code Recognition”
A very important real-world application of backpropagation (handwritten digit recognition) has been addressed in this report. Significantly, it took into account the practical need for a chief modification of neural nets to enhance modern deep learning.
Besides Deep Learning, there are other kinds of architectures, like Deep Belief Networks, Recurrent Neural Networks and Generative Adversarial Networks etc., which can be discussed later.
For comprehensive Machine Learning training Gurgaon, reach us at DexLab Analytics. We are a pioneering data science online training platform in India, bringing advanced machine learning courses to the masses.
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.