Big data is the big word, NOW. Data sets are becoming more and more large and complex, making it extremely troublesome to coordinate activities using on-hand database management tools.

The flourishing growth in IT industry has triggered numerous complimentary conditions. One of the conditions is the emergence of Big Data. This two-word seven-letter catch phrase deals with a humongous amount of data, which is of prime importance in the eyes of the company in question. And the resultant effect leads to another branch of science, which is Data Analytics.
What is A/B Testing?
A/B Testing is a powerful assessment tool to determine which version of an app or a webpage helps an individual or his business meet future goals effectively and positively. The decision is not abrupt; it is taken after carefully comparing various versions to reveal out the best of the lot.
Also read: Big Data Analytics and its Impact on Manufacturing Sector
A/B Testing forms an integral part in web development and big data industry. It ensures that the alterations happening on a webpage or any page component are data-driven and not opinion-based.
What do you mean by Association Rule Learning
This comprises of a set of techniques to find out interesting relationships, i.e. ‘association rules’ amidst variables in massive databases. The methods include an assortment of algorithms to initiate and test possible rules.
Also read: What Sets Apart Data Science from Big Data and Data Analytics
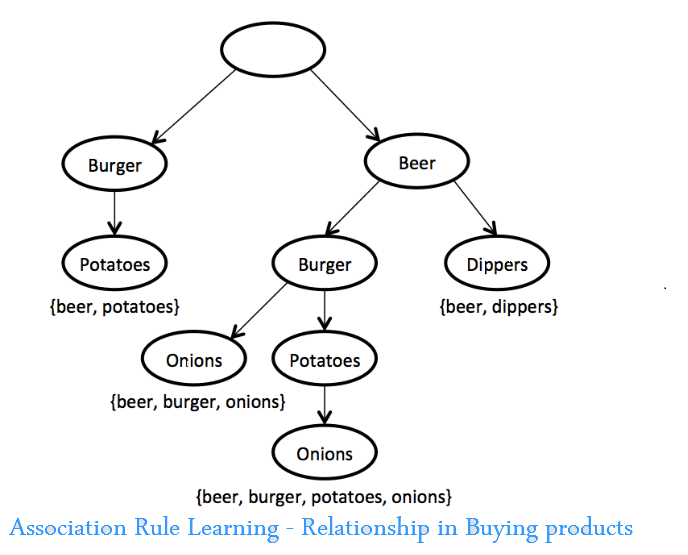
The following flowchart, a market basket analysis is being focused. Here, a retailer ascertains which products are high in demand and eventually use this data for successful marketing.
How to understand Classification Tree Analysis?
Statistical Classification is implemented to:
- Classify organisms into groups
- Automatically allocate documents to categories
- Create profiles of students who enrol for online courses
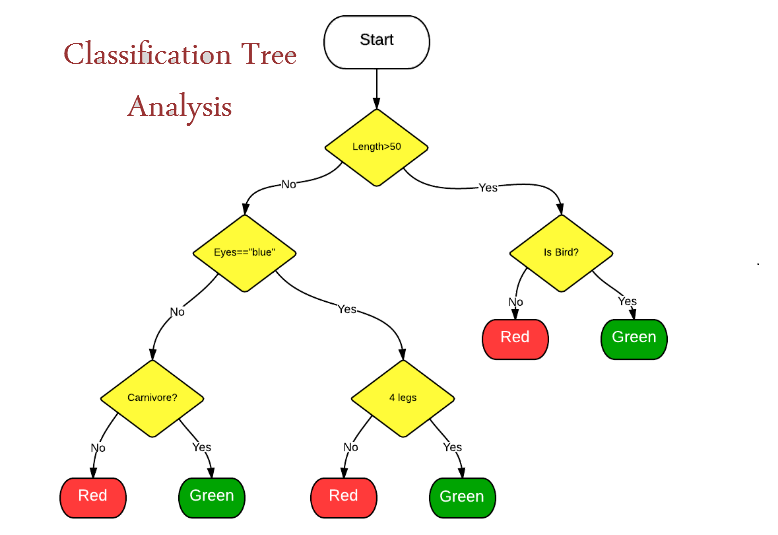
It is a method of recognizing categories, in which the new observation falls into. It needs a training set of appropriately identified observations, aka historical data.
Why should you take a sneak peek into the world of Data Fusion and Data Integration?
Well, this is a complex multi-level process involving correlation, association, combination of information and data from one and many sources, to attain a superior position, determine estimates and finish timely assessments of projects. By combining data from multiple sensors, data integration and fusion helps in improving overall accuracy and direct more specific inferences, which would have otherwise been impossible from a single sensor alone.
Also read: How To Stop Big Data Projects From Failing?
Let’s talk about Data Mining
Identify patterns and strike relationships, with Data Mining. It is nothing but the collective data extraction techniques to be performed on a large chunk of data. Some of the common data mining parameters are Association, Classification, Clustering, Sequence Analysis and Forecasting.
Generally, applications involve mining customer data to deduce segments and understand market basket analyses. It helps understanding the purchase behaviour of customers.
Neural Networks – Resembling biological neural networks
Non-linear predictive models are mostly used for pattern recognition and optimization. Some of the applications ask for supervised learning, whereas some invites unsupervised learning.
To know more about Big Data certification, why don’t you check our extensive Machine Learning Certification courses in Gurgaon! We, at DexLab Analytics have all sorts of courses suiting your professional work skill.
Interested in a career in Data Analyst?
To learn more about Machine Learning Using Python and Spark – click here.
To learn more about Data Analyst with Advanced excel course – click here.
To learn more about Data Analyst with SAS Course – click here.
To learn more about Data Analyst with R Course – click here.
To learn more about Big Data Course – click here.