I’m a data scientist by profession with an actuarial background.
I graduated with a degree in Criminology; it was during university that I fell in love with the power of statistics. A typical problem would involve estimating the likelihood of a house getting burgled on a street, if there has already been a burglary on that street. For the layman, this is part of predictive policing techniques used to tackle crime. More technically, “It involves a Non-Markovian counting process called the “Hawkes Process” which models for “self-exciting” events (like crimes, future stock price movements, or even popularity of political leaders, etc.)
Being able to predict the likelihood of future events (like crimes in this case) was the main thing which drew me to Statistics. On a philosophical level, it’s really a quest for “truth of things” unfettered by the inherent cognitive biases humans are born with (there are 25 I know of).

Arguably, Actuaries are the original Data Scientists, turning data in actionable insights since the 18th Century when Alexander Webster with Robert Wallace built a predictive model to calculate the average life expectancy of soldiers going to war using death records. And so, “Insurance” was born to provide cover to the widows and children of the deceased soldiers.
Of course, Alan Turing’s contribution cannot be ignored, which eventually afforded us with the computational power needed to carry out statistical testing on entire populations – thereby Machine Learning was born. To be fair, the history of Data Science is an entire blog of its own. More on that will come later.
The aim of this series of blogs is to initiate anyone daunted by the task of acquiring the very basics of Statistics and Mathematics used in Machine Learning. There are tonnes of online resources which will only list out the topics but will rarely explain why you need to learn them and to what extent. This series will attempt to address this problem adopting a “first principle” approach. Its best to refer back to this article a second time after gaining the very basics of each Topic discussed below:
We will be discussing:
- Central Limit Theorem
- Bayes Theorem
- Probability Theory
- Point Estimation – MLE’s
- Confidence Intervals
- P-values and Significance Test.
This list is by no means exhaustive of the statistical and mathematical concepts you will need in your career as a data scientist. Nevertheless, it provides a solid grounding going into more advanced topics.
Without further due, here goes:
Central Limit Theorem
Central Limit Theorem (CLT) is perhaps one of the most important results in all of Statistics. Essentially, it allows making large sample inference about the Population Mean (μ), as well as making large sample inference about population proportion (p).
So what does this really means?
Consider (X1, X2, X3……..Xn) samples, where n is a large number say, 100. Each sample will have its own respective sample Mean (x̅). This will give us “n” number of sample means. Central Limit Theorem now states:
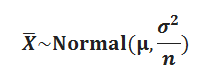
&![]()
Try to visualise the distribution “of the average of lots of averages”… Essentially, if we have a large number of averages that have been taken from a corresponding large number of samples; then Central Limit theorem allows us to find the distribution of those averages. The beauty of it is that we don’t have to know the parent distribution of the averages. They all tend to Normal… eventually!
Similarly if we were to add up independent and identically distributed (iid) samples, then their corresponding distribution will also tend to a Normal.
Very often in your work as a data scientist a lot of the unknown distributions will tend to Normal, now you can visualise how and more importantly why!
Stay tuned to DexLab Analytics for more articles discussing the topics listed above in depth. To deep dive into data science, I strongly recommend this Big Data Hadoop institute in Delhi NCR. DexLab offers big data courses developed by industry experts, helping you master in-demand skills and carve a successful career as a data scientist.
About the Author: Nish Lau Bakshi is a professional data scientist with an actuarial background and a passion to use the power of statistics to tackle various pressing, daily life problems.
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.