Computer Vision is one of the most revolutionary and advanced technologies that deep learning has birthed. It is the computer’s ability to classify and recognize objects in pictures and even videos like the human eye does. There are five main techniques of computer vision that we ought to know about for their amazing technological prowess and ability to ‘see’ and perceive surroundings like we do. Let us see what they are.
Image Classification
The main concern around image classification is categorization of images based on viewpoint variation, image deformation and occlusion, illumination and background clutter. Measuring the accuracy of the description of an image becomes a difficult task because of these factors. Researchers have come up with a novel way to solve the problem.
They use a data driven approach to classify the image. Instead of classifying what each image looks like in code, they feed the computer system with many image classes and then develop algorithms that look at these classes and “learn” about the visual appearance of each class. The most popular system used for image classification is Convolutional Neural Networks (CNNs).
Object Detection
Object detection is, simply put, defining objects within images by outputting bounding boxes and labels or tags for individual objects. This differs from image classification in that it is applied to several objects all at once rather than identifying just one dominant object in an image. Now applying CNNs to this technique will be computationally expensive.
So the technique used for object detection is region-based CNNs of R-CNNs. In this technique, first an image is scanned for objects using an algorithm that generates hundreds of region proposals. Then a CNN is run on each region proposal and only then is each object in each region proposal classified. It is like surveying and labelling the items in a warehouse of a store.
Object Tracking
Object tracking refers to the process of tracking or following a specific object like a car or a person in a given scene in videos. This technique is important for autonomous driving systems in self-driving cars. Object detection can be divided into two main categories – generative method and discriminative method.
The first method uses the generative model to describe the evident characteristics of objects. The second method is used to distinguish between object and background and foreground.
Semantic Segmentation
Crucial to computer vision is the process of segmentation wherein whole images are divided or segmented into pixelgroups that are subsequently labeled and classified.
The science tries to understand the role of each pixel in the image. So, for instance, besides recognizing and detecting a tree in an image, its boundaries are depicted as well. CNNs are best used for this technique.
Instance Segmentation
This method builds on semantic segmentation in that instead of classifying just one single dominant object in an image, it labels multiple images with different colours.
When we see complicated images with multiple overlapping objects and different backgrounds, we apply instance segmentation to it. This is done to generate pixel studies of each object, their boundaries and backdrops.
Conclusion
Besides these techniques to study and analyse and interpret images or a series of images, there are many more complex techniques that we have not delved into in this blog. However, for more on computer vision, you can peruse the DexLab Analytics website. DexLab Analytics is a premiere Deep Learning training institute In Delhi.
The severe cyclonic storm Nisarga approached the Maharashtra coast around Alibagh in Raigadh with “a sustained wind speed of 100-110 kmph” on June 3, 2020. Then it made landfall at Alibagh at around noontime. Landfall simply means that the storm, after having intensified over the ocean, has moved on to land.
Though the storm mellowed down in intensity as it approached the Maharashtra coast, government bodies took all precautions and evacuation work was done in advance on the basis of forecasts done by meteorologists and scientists.
To save lives and property, it is imperative to predict cyclones and the intensity with which they will strike. Deep Learning, a branch of artificial Intelligence, is helping scientists make breakthroughs in the science of forecasting cyclones.
Image Source: outlookindia.com
Existing Storm Forecast Models
Most conventional dynamical models make accurate short term predictions but they are computationally demanding and “current statistical forecasting models have much room for improvement given that the database of past hurricanes is constantly growing”, says a report.
A tropical cyclone forecast involves the prediction of several interrelated features like track, intensity, rainfall, storm surge etc. The development of current hurricane and cyclone forecasts have advanced over the years but they are largely statistical in nature. The main limitation of this method is the complexity and non-linearity of atmospheric systems.
Deep Learning Models
Recurrent Neural Networks in deep learning models have been, of late, used to study increasingly complicated systems instead of the traditional methods of forecasting because they promise more accuracy. RNNs are a class of artificial neural networks where the modification of weights allows the model to learn intricate dynamic temporal behaviours, says another report.
An RNN with the capability of modelling complex non-linear temporal relationships of a hurricane or a cyclone could increase the accuracy of predicting future cyclonic path forecasts.
Machine Learning
Generally speaking, there are two methods or approaches to detecting extreme weather events like tropical cyclones – the data driven method which includes machine learning and the model driven approach which includes numerical simulation.
“The model-driven approach has the limitation that the prediction error increases with lead time because numerical models are inherently dependent on initial values. On the other hand, machine learning, as a data-driven approach, requires a large amount of high-quality training data,” says areport.
High quality data is easy to procure given the large amounts of data generated from weather stations on a daily basis the world over. So the machine learning method is easier to work and generate results from.
Conclusion
So what was difficult to do, that is find suitable metrics to study and detect the path of tropical cyclones earlier, has now become easier to do and scientists have been able to achieve accuracy in their predictions through the use of neural networks and artificial intelligence in general. For more on the subject, do read our blog here and here. Dexlab Analytics is a premier Deep Learning training institute in Delhi.
Artificial intelligence (AI) and machine learning are today thought to be one of the biggest innovations since the microchip. With the advancement of the science of neural networks, scientists are making extraordinary breakthroughs in machine learning through what is termed as deep learning. These sciences are making life easier and more streamlined for us in more ways than one. Here are a few examples.
1. Smart Gaming
Artificial Intelligence and Machine Learning are used in smart gaming techniques, especially in games that primarily require the use of mental abilities like chess. Google DeepMind’s AlphaGo learnt to play chess, and defeat champions like Lee Sedol (in 2016) by not only studying the moves of masters but by learning how to play the game by practising against itself innumerable times.
2. Automated Transportation
When we fly in an airplane, we experience automated transportation in the sense that a human pilot is only flying the plane for a couple of minutes during take-off and landing. The rest of the flight is maneuvered by a Flight Management System, a synchronization of GPS, motion sensors and computer systems that track flight position. Google Maps has already revolutionized local transport by studying coordinates from smart phones to determine how fast or slow a vehicle is moving and therefore how much traffic there is on a given road at any point of time.
3. Dangerous Jobs
AI technology powered robots are taking over dangerous jobs like bomb disposal and welding. In bomb disposal, today, robots need to be controlled by humans. But scientists believe there will soon come a time when these tasks would be completed by robots themselves. This technology has already saved hundreds of lives. In the field of welding, a hazardous job which entails working in high levels of noise and heat in a toxic environment, robots are helping weld with greater accuracy.
4. Environmental Protection
Machine Learning and artificial intelligence run on big data, large caches of data and mind boggling statistics generated by computer systems. When put to use in the field of environmental protection, these technologies could be used to extract actionable solutions to untenable problems like environmental degradation. For instance, “IBM’s Green Horizon Project studies and analyzes environmental data from thousands of sensors and sources to produce accurate, evolving weather and pollution forecasts.”
5. Robots as Friends
A company in Japan has invented what it calls a robot companion named Pepper who can understand and feel emotions and empathy. Introduced in 2014, Pepper went on sale in 2015 and all the 1000 units were sold off immediately. “The robot was programmed to read human emotions, develop its own, and help its human friends stay happy,” a report says. Robots could also assist the aged in becoming independent and take care of themselves, says a computer scientist at Washington State University.
6. Health Care
Hospitals across the world are mulling over the adoption of AI and ML to treat patients so there are reduced instances of hospital related accidents and spread of diseases like sepsis. AI’s predictive models are helping in the fight against genetic diseases and heart ailments. Also, Deep Learning models which “quickly provide real-time insights and…are helping healthcare professionals diagnose patients faster and more accurately, develop innovative new drugs and treatments, reduce medical and diagnostic errors, predict adverse reactions, and lower the costs of healthcare for providers and patients.”
7. Digital Media
Machine learning has revolutionized the entertainment industry and technology has already found buyers in streaming services such as Netflix, Amazon Prime, Spotify, and Google Play. “ML algorithms are…making use of the almost endless stream of data about consumers’ viewing habits, helping streaming services offer more useful recommendations.”
These technologies will assist with the production of media too. NLP (Natural Language Processing) algorithms help write and compose trending news stories, thus cutting on production time. Moreover, a new MIT-developed AI model named Shelley “helps users write horror stories through deep learning algorithms and a bank of user-generated fiction.”
8. Home Security and Smart Stores
AI-integrated cameras and alarm systems are taking the home security world by storm. The cutting-edge systems “use facial recognition software and machine learning to build a catalog of your home’s frequent visitors, allowing these systems to detect uninvited guests in an instant.” Brick and Mortar stores are likely to adopt facial recognition for payments by shoppers. Biometric capabilities are largely being adopted to enhance the shopping experience.
Big data is all around us, be it generated by our news feed or the photos we upload on social media. Data is the new oil and therefore, today, more than ever before, there is a need to study, organize and extract knowledgeable and actionable insights from it. For this, the role of data scientists has become even more crucial to our world. In this article we discuss the various skills, both technical and non-technical a data scientist needs to master to acquire a standing in a competitive market.
Technical Skills
Python and R
Knowledge of these two is imperative for a data scientist to operate. Though organisations might want knowledge of only one of the two programming languages, it is beneficial to know both. Python is becoming more popular with most organisations. Machine Learning using Python is taking the computing world by storm.
GitHub
Git and GitHub are tools for developers and data scientists which greatly help in managing various versions of the software. “They track all changes that are made to a code base and in addition, they add ease in collaboration when multiple developers make changes to the same project at the same time.”
Preparing for Production
Historically, the data scientist was supposed to work in the domain of machine learning. But now data science projects are being more often developed for production systems. “At the same time, advanced types of models now require more and more compute and storage resources, especially when working with deep learning.”
Cloud
Cloud software rules the roost when it comes to data science and machine learning. Keeping your data on cloud vendors like AWS, Microsoft Azure or Google Cloud makes it easily accessible from remote areas and helps quickly set up a machine learning environment. This is not a mandatory skill to have but it is beneficial to be up to date with this very crucial aspect of computing.
Deep Learning
Deep learning, a branch of machine learning, tailored for specific problem domains like image recognition and NLP, is an added advantage and a big plus point to your resume. Even if the data scientist has a broad knowledge of deep learning, “experimenting with an appropriate data set will allow him to understand the steps required if the need arises in the future”. Deep learning training institutes are coming up across the globe, and more so in India.
Math and Statistics
Knowledge of various machine learning techniques, with an emphasis on mathematics and algebra, is integral to being a data scientist. A fundamental grounding in the mathematical foundation for machine learning is critical to a career in data science, especially to avoid “guessing at hyperparameter values when tuning algorithms”. Knowledge of Calculus linear algebra, statistics and probability theory is also imperative.
SQL
Structured Query Language (SQL) is the most widely used database language and a knowledge of the same helps data scientist in acquiring data, especially in cases when a data science project comes in from an enterprise relational database. “In addition, using R packages like sqldf is a great way to query data in a data frame using SQL,” says a report.
AutoML
Data Scientists should have grounding in AutoML tools to give them leverage when it comes to expanding the capabilities of a resource, which could be in short supply. This could deliver positive results for a small team working with limited resources.
Data Visualization
Data visualization is the first step to data storytelling. It helps showcase the brilliance of a data scientist by graphically depicting his or her findings from data sets. This skill is crucial to the success of a data science project. It explains the findings of a project to stakeholders in a visually attractive and non-technical manner.
Non-Technical Skills
Ability to solve business problems
It is of vital importance for a data scientist to have the ability to study business problems in an organization and translate those to actionable data-driven solutions. Knowledge of technical areas like programming and coding is not enough. A data scientist must have a solid foundation in knowledge of organizational problems and workings.
Effective business communication
A data scientist needs to have persuasive and effective communication skills so he or she can face probing stakeholders and meet challenges when it comes to communicating the results of data findings. Soft skills must be developed and inter personal skills must be honed to make you a creatively competent data scientist, something that will set you apart from your peers.
Agility
Data scientist need to be able to work with Agile methodology in that they should be able to work based on the Scrum method. It improves teamwork and helps all members of the team remain in the loop as does the client. Collaboration with team members towards the sustainable growth of an organization is of utmost importance.
Experimentation
The importance of experimentation cannot be stressed enough in the field of data science. A data scientist must have a penchant for seeking out new data sets and practise robustly with previously unknown data sets. Consider this your pet project and practise on what you are passionate about like sports.
This article, the second part of a series, is on the application of artificial intelligence in the field of healthcare. The first part of the series mapped the applications of AI and deep learning in agriculture, with an emphasis on precision farming.
AI has been taking the world by storm and its most crucial application is to the two fields mentioned above. Its application to the field of healthcare is slowly expanding, covering fields of practice such as radiology and oncology.
Stroke Prevention
In a study published in Circulation, a researcher from the British Heart Foundation revealed that his team had trained an artificial intelligence model to read MRI scans and detect compromised blood flow to and from the heart.
And an organisation called the Combio Health Care developed a clinical support system to assist doctors in detecting the risk of strokes in incoming patients.
Brain-Computer Interfaces
Neurological conditions or trauma to the nervous system can adversely affect a patient’s motor sensibilities and his or her ability to meaningfully communicate with his or her environment, including the people around.
AI powered Brain-Computer Interfaces can restore these fundamental experiences. This technology can improve lives drastically for the estimated 5,00,000 people affected by spinal injuries annually the world over and also help out patients affected by ALS, strokes or locked-in syndrome.
Radiology
Radiological imagery obtained from x-rays or CT scanners put radiologists in danger of contracting infection through tissue samples which come in through biopsies. AI is set to assist the next generation of radiologists to completely do away with the need for tissue samples, experts predict.
A report says “(a)rtificial intelligence is helping to enable “virtual biopsies” and advance the innovative field of radiomics, which focuses on harnessing image-based algorithms to characterize the phenotypes and genetic properties of tumors.”
Cancer Treatment
One reason why AI, has made immense advancements in the field of medical oncology is the vast amount of data generated during cancer treatment.
Machine learning algorithms and their ability to study and synthesize highly complex datasets may be able to shed light on new options for targeting therapies to a patient’s unique genetic profile.
Developing countries
Most developing counties suffer from health care systems working on shoe-string budgets with a lack of critical healthcare providers and technicians. AI-powered machines can help plug the deficit of expert professionals.
For example, AI imaging tools can study chest x-rays for signs of diseases like tuberculosis, with an impressive rate of accuracy comparable to human beings. However, algorithm developers must bear in mind the fact that “(t)he course of a disease and population affected by the disease may look very different in India than in the US, for example,” the report says. So an algorithm based on a single ethnic populace might not work for another.
Deep learning is a subset of machine learning, a branch of artificial intelligence that configures computers to perform tasks through experience. While classic machine-learning algorithms solved many problems, they are poor at dealing with soft data such as images, video, sound files, and unstructured text.
Deep-learning algorithms solve the same problem using deep neural networks, a type of software architecture inspired by the human brain (though neural networks are different from biological neurons). Neural Networks are inspired by our understanding of the biology of our brains – all those interconnections between the neurons. But, unlike a biological brain where any neuron can connect to any other neuron within a certain physical distance, these artificial neural networks have discrete layers, connections, and directions of data propagation.
The data is inputted into the first layer of the neural network. In the first layer individual neurons pass the data to a second layer. The second layer of neurons does its task, and so on, until the final layer and the final output is produced. Each neuron assigns a weighting to its input — how correct or incorrect it is relative to the task being performed. The final output is then determined by the total of those weightings.
Deep Learning Use Case Examples
Robotics
Many of the recent developments in robotics have been driven by advances in AI and deep learning. Developments in AI mean we can expect the robots of the future to increasingly be used as human assistants. They will not only be used to understand and answer questions, as some are used today. They will also be able to act on voice commands and gestures, even anticipate a worker’s next move. Today, collaborative robots already work alongside humans, with humans and robots each performing separate tasks that are best suited to their strengths.
Agriculture
AI has the potential to revolutionize farming. Today, deep learning enables farmers to deploy equipment that can see and differentiate between crop plants and weeds. This capability allows weeding machines to selectively spray herbicides on weeds and leave other plants untouched. Farming machines that use deep learning–enabled computer vision can even optimize individual plants in a field by selectively spraying herbicides, fertilizers, fungicides and insecticides.
Medical Imaging and Healthcare
Deep learning has been particularly effective in medical imaging, due to the availability of high-quality data and the ability of convolutional neural networks to classify images. Several vendors have already received FDA approval for deep learning algorithms for diagnostic purposes, including image analysis for oncology and retina diseases. Deep learning is also making significant inroads into improving healthcare quality by predicting medical events from electronic health record data. Earlier this year, computer scientists at the Massachusetts Institute of Technology (MIT) used deep learning to create a new computer program for detecting breast cancer.
Here are some basic techniques that allow deep learning to solve a variety of problems.
Fully Connected Neural Networks
Fully Connected Feed forward Neural Networks are the standard network architecture used in most basic neural network applications.
In a fully connected layer each neuron is connected to every neuron in the previous layer, and each connection has its own weight. This is a totally general purpose connection pattern and makes no assumptions about the features in the data. It’s also very expensive in terms of memory (weights) and computation (connections).
Each neuron in a neural network contains an activation function that changes the output of a neuron given its input. These activation functions are:
Linear function: – it is a straight line that essentially multiplies the input by a constant value.
Sigmoid function: – it is an S-shaped curve ranging from 0 to 1.
Hyperbolic tangent (tanH) function: – it is an S-shaped curve ranging from -1 to +1
Rectified linear unit (ReLU) function: – it is a piecewise function that outputs a 0 if the input is less than a certain value or linear multiple if the input is greater than a certain value.
Each type of activation function has pros and cons, so we use them in various layers in a deep neural network based on the problem. Non-linearity is what allows deep neural networks to model complex functions.
Convolutional Neural Networks
Convolutional Neural Networks (CNN) is a type of deep neural network architecture designed for specific tasks like image classification. CNNs were inspired by the organization of neurons in the visual cortex of the animal brain. As a result, they provide some very interesting features that are useful for processing certain types of data like images, audio and video.
Mainly three main types of layers are used to build ConvNet architectures: Convolutional Layer, Pooling Layer, and Fully-Connected Layer (exactly as seen in regular Neural Networks). We will stack these layers to form a full ConvNet architecture. A simple ConvNet for CIFAR-10 classification could have the above architecture [INPUT – CONV – RELU – POOL – FC].
INPUT [32x32x3] will hold the raw pixel values of the image, in this case an image of width 32, height 32, and with three color channels R,G,B.
CONV layer will compute the output of neurons that are connected to local regions in the input, each computing a dot product between their weights and a small region they are connected to in the input volume. This may result in volume such as [32x32x12] if we decided to use 12 filters.
RELU layer will apply an elementwise activation function, such as the max(0,x)max(0,x)thresholding at zero. This leaves the size of the volume unchanged ([32x32x12]).
POOL layer will perform a downsampling operation along the spatial dimensions (width, height), resulting in volume such as [16x16x12].
FC (i.e. fully-connected) layer will compute the class scores, resulting in volume of size [1x1x10], where each of the 10 numbers correspond to a class score, such as among the 10 categories of CIFAR-10. As with ordinary Neural Networks and as the name implies, each neuron in this layer will be connected to all the numbers in the previous volume.
In this way, ConvNets transform the original image layer by layer from the original pixel values to the final class scores. Note that some layers contain parameters and others don’t. In particular, the CONV/FC layers perform transformations that are a function of not only the activations in the input volume, but also of the parameters (the weights and biases of the neurons). On the other hand, the RELU/POOL layers will implement a fixed function. The parameters in the CONV/FC layers will be trained with gradient descent so that the class scores that the ConvNet computes are consistent with the labels in the training set for each image.
Convolution is a technique that allows us to extract visual features from an image in small chunks. Each neuron in a convolution layer is responsible for a small cluster of neurons in the receding layer. CNNs work well for a variety of tasks including image recognition, image processing, image segmentation, video analysis, and natural language processing.
Recurrent Neural Network
The recurrent neural network (RNN), unlike feed forward neural networks, can operate effectively on sequences of data with variable input length.
The idea behind RNNs is to make use of sequential information. In a traditional neural network we assume that all inputs (and outputs) are independent of each other. But for many tasks that is a very bad idea. If you want to predict the next word in a sentence you better know which words came before it. RNNs are called recurrent because they perform the same task for every element of a sequence, with the output being depended on the previous computations. Another way to think about RNNs is that they have a “memory” which captures information about what has been calculated so far. This is essentially like giving a neural network a short-term memory. This feature makes RNNs very effective for working with sequences of data that occur over time, For example, the time-series data, like changes in stock prices, a sequence of characters, like a stream of characters being typed into a mobile phone.
The two variants on the basic RNN architecture that help solve a common problem with training RNNs are Gated RNNs, and Long Short-Term Memory RNNs (LSTMs). Both of these variants use a form of memory to help make predictions in sequences over time. The main difference between a Gated RNN and an LSTM is that the Gated RNN has two gates to control its memory: an Update gate and a Reset gate, while an LSTM has three gates: an Input gate, an Output gate, and a Forget gate.
RNNs work well for applications that involve a sequence of data that change over time. These applications include natural language processing, speech recognition, language translation, image captioning and conversation modeling.
Conclusion
So this article was about various Deep Learning techniques. Each technique is useful in its own way and is put to practical use in various applications daily. Although deep learning is currently the most advanced artificial intelligence technique, it is not the AI industry’s final destination. The evolution of deep learning and neural networks might give us totally new architectures. Which is why more and more institutes are offering courses on AI and Deep Learning across the world and in India as well. One of the best and most competent artificial intelligence certification in Delhi NCR is DexLab Analytics. It offers an array of courses worth exploring.
In the first series of this article we have seen what is computer vision and a brief review of its applications. You can read the first part of this article here. We have also seen the contribution of deep learning in computer vision. Especially we focused on Image Classification and deep learning architecture which is used in Image Classification. In this series we will focus on other applications including Image Localization, Object Detection and Image Segmentation. We will also walk through the required deep learning architecture used for above applications.
Image classification with Localization
Similar to classification, localization finds the location of a single object inside the image. Localization can be used for lots of useful real-life problems. For example, smart cropping (knowing where to crop images based on where the object is located), or even regular object extraction for further processing using different techniques. It can be combined with classification for not only locating the object but categorizing it into one of many possible categories.
Iterating over the problem of localization plus classification we end up with the need for detecting and classifying multiple objects at the same time. Object detection is the problem of finding and classifying a variable number of objects on an image. The important difference is the “variable” part. In contrast with problems like classification, the output of object detection is variable in length, since the number of objects detected may change from image to image.
The PASCAL Visual Object Classes datasets, or PASCAL VOC for short (e.g. VOC 2012), is a common dataset for object detection.
Deep learning for Image Localization and Object Detection
There is nothing hardcore about the architectures which we are going to discuss. What we are going to discuss are some clever ideas to make the system intolerant to the number of outputs and to reduce its computation cost. So, we do not know the exact number of objects in our image and we want to classify all of them and draw a bounding box around them. That means that the number of coordinates that the model should output is not constant. If the image has 2 objects, we need 8 coordinates. If it has 4 objects, we want 16. So how we build such a model?
One key idea to traditional computer vision is regions proposal. We generate a set of windows that are likely to contain an object using classic CV algorithms, like edge and shape detection and we apply only these windows (or regions of interests) to the CNN. To learn more about how regions are proposed, we introduce a new architecture called RCNN.
R-CNN
Given an image with multiple objects, we generate some regions of interests using a proposal method (in RCNN’s case this method is called selective search) and wrap the regions into a fixed size. We forward each region to Convolutional Neural Network (such as AlexNet), which will use an SVM to make a classification decision for each one and predicts a regression for each bounding box. This prediction comes as a correction of the region proposed, which may be in the right position but not at the exact size and orientation.
Although the model produces good results, it suffers from a major issue. It is quite slow and computationally expensive. Imagine that in an average case, we produce 2000 regions, which we need to store in disk, and we forward each one of them into the CNN for multiple passes until it is trained. To fix some of these problems, an improvement of the model comes in play called ‘Fast-RCNN’
Fast RCNN
The idea is straightforward. Instead of passing all regions into the convolutional layer one by one, we pass the entire image once and produce a feature map. Then we take the region proposals as before (using some external method) and sort of project them onto the feature map. Now we have the regions in the feature map instead of the original image and we can forward them in some fully connected layers to output the classification decision and the bounding box correction.
Note that the projection of regions proposal is implemented using a special layer (ROI layer), which is essentially a type of max-pooling with a pool size dependent on the input, so that the output always has the same size.
Faster RCNN
And we can take this a step further. Using the produced feature maps from the convolutional layer, we infer regions proposal using a Region Proposal network rather than relying on an external system. Once we have those proposals, the remaining procedure is the same as Fast-RCNN (forward to ROI layer, classify using SVM and predict the bounding box). The tricky part is how to train the whole model as we have multiple tasks that need to be addressed:
The region proposal network should decide for each region if it contains an object or not.
It needs to produce the bounding box coordinates.
The entire model should classify the objects to categories.
And again predict the bounding box offsets.
As the name suggests, Faster RCNN turns out to be much faster than the previous models and is the one preferred in most real-world applications.
Localization and object detection is a super active and interesting area of research due to the high emergency of real world applications that require excellent performance in computer vision tasks (self-driving cars, robotics). Companies and universities come up with new ideas on how to improve the accuracy on regular basis.
There is another class of models for localization and object detection, called single shot detectors, which have become very popular in the last few years because they are even faster and require less computational cost in general. Sure, they are less accurate, but they are ideal for embedded systems and similar power-hungry applications.
Object segmentation
Going one step further from object detection we would want to not only find objects inside an image, but find a pixel by pixel mask of each of the detected objects. We refer to this problem as instance or object segmentation.
Semantic Segmentation is the process of assigning a label to every pixel in the image. This is in stark contrast to classification, where a single label is assigned to the entire picture. Semantic segmentation treats multiple objects of the same class as a single entity. On the other hand, instance segmentation treats multiple objects of the same class as distinct individual objects (or instances). Typically, instance segmentation is harder than semantic segmentation.
In order to perform semantic segmentation, a higher level understanding of the image is required. The algorithm should figure out the objects present and also the pixels which correspond to the object. Semantic segmentation is one of the essential tasks for complete scene understanding. This can be used in analysis of medical images and satellite images. Again, the VOC 2012 and MS COCO datasets can be used for object segmentation.
Deep Learning for Image Segmentation
Modern image segmentation techniques are powered by deep learning technology. Here are several deep learning architectures used for segmentation.
Convolutional Neural Networks (CNNs)
Image segmentation with CNN involves feeding segments of an image as input to a convolutional neural network, which labels the pixels. The CNN cannot process the whole image at once. It scans the image, looking at a small “filter” of several pixels each time until it has mapped the entire image. To learn more see our in-depth guide about Convolutional Neural Networks.
Fully Convolutional Networks (FCNs)
Traditional CNNs have fully-connected layers, which can’t manage different input sizes. FCNs use convolutional layers to process varying input sizes and can work faster. The final output layer has a large receptive field and corresponds to the height and width of the image, while the number of channels corresponds to the number of classes. The convolutional layers classify every pixel to determine the context of the image, including the location of objects.
DeepLab
One main motivation for DeepLab is to perform image segmentation while helping control signal decimation—reducing the number of samples and the amount of data that the network must process. Another motivation is to enable multi-scale contextual feature learning—aggregating features from images at different scales. DeepLab uses an ImageNet pre-trained residual neural network (ResNet) for feature extraction. DeepLab uses atrous (dilated) convolutions instead of regular convolutions. The varying dilation rates of each convolution enable the ResNet block to capture multi-scale contextual information. DeepLab comprises three components:
Atrous convolutions—with a factor that expands or contracts the convolutional filter’s field of view.
ResNet—a deep convolutional network (DCNN) from Microsoft. It provides a framework that enables training thousands of layers while maintaining performance. The powerful representational ability of ResNet boosts computer vision applications like object detection and face recognition.
Atrous spatial pyramid pooling (ASPP)—provides multi-scale information. It uses a set of atrous convolutions with varying dilation rates to capture long-range context. ASPP also uses global average pooling (GAP) to incorporate image-level features and add global context information.
SegNet neural network
An architecture based on deep encoders and decoders is also known as semantic pixel-wise segmentation. It involves encoding the input image into low dimensions and then recovering it with orientation invariance capabilities in the decoder. This generates a segmented image at the decoder end.
Conclusion
In this post we have discussed some applications of computer vision including Image Localization, Object Detection and Image Segmentation. We then discussed required deep learning architectures which are used for the above applications.
Deep Learning has its limitations, scientists argue.
“We have machines that learn in a very narrow way,” Yoshua Bengio, deep learning pioneer, said in his keynote address at NeurIPS in December, 2019. “They need much more data to learn a task than human examples of intelligence, and they still make stupid mistakes.”
Unarguably, deep learning is an imperfect framework of intelligence. It does not think abstractedly, does not comprehend causation and struggles with out-of-distribution generalization. For a deeper understanding of its limitations, this brilliant paper on the science and its shortcomings is available on the internet.
However, despite numerous shortcomings, the commercial uses of deep learning are only just being mined and its capabilities to automate and transform industries still abound. AI and deep learning capabilities, as developed as they are today, are sufficiently mature to spearhead transformation, innovation, and value creation across industries like agriculture, healthcare and construction. “For the most part, these transformative opportunities have not yet been operationalized at scale.”
Radiology
For instance, in the radiology industry, something as extreme and point blank as this was declared in 2016 by AI luminary Geoff Hinton – “It’s quite obvious that we should stop training radiologists now.” Hinton’s comments drew worked up reactions in the medical community but his statement was based on strong data which showed neural networks can identify medical conditions from X-rays with better accuracy than human radiologists can.
Yet, years after Hinton foresaw the removal of the need of human radiologists from the medical science field, no clinic in the world has deployed AI-driven radiology tools at scale. Only a few health organizations have begun using it in limited settings. But more and more organizations are slowly adopting deep learning in radiology.
Off Road Autonomous Vehicles
In another instance, the off-road autonomous vehicle industry is seeing a slow move towards tapping the massive unrealized commercial potential of AI. Construction, agriculture and mining are some of the largest industries in the world. If these industries start deploying deep learning powered automated machines to do work that human hands are trained to do, a massive pool of cost, productivity and safety benefits could be tapped.
Energy
In the field of energy, leading players like BP are using deep learning to innovate and transform work conditions on site. “It uses technology to drive new levels of performance, improve the use of resources and safety and reliability of oil and gas production and refining. From sensors that relay the conditions at each site to using AI technology to improve operations, BP puts data at the fingertips of engineers, scientists and decision-makers to help drive high performance.”
Retail
Burberry, a luxury fashion brand, uses big data and AI to fight counterfeit products. It is also trying to enhance sales and customer relationships by initiating a loyalty program that creates data to help personalize the shopping experience for each customer.
Social Media
Both Twitter and Facebook are tapping into structured and unstructured sets of big data for understanding user behavior and using deep learning to check for communal or racist comments and user preferences.
Deep Learning and Artificial Intelligence is the future and it is here to stay. No wonder then, that more and more professionals are opting to train themselves through deep learning courses. DexLab Analytics is one of the best Deep Learning training institutes in Delhi. Do go through its website for more details.
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now. To learn more about Data Analyst with R Course – Enrol Now. To learn more about Big Data Course – Enrol Now.
To learn more about Machine Learning Using Python and Spark – Enrol Now. To learn more about Data Analyst with SAS Course – Enrol Now. To learn more about Data Analyst with Apache Spark Course – Enrol Now. To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.
Computer vision is the field of computer science that focuses on replicating parts of the complexity of the human vision system and enabling computers to identify and process objects in images and videos in the same way that humans do. With computer vision, our computer can extract, analyze and understand useful information from an individual image or a sequence of images. Computer vision is a field of artificial intelligence that works on enabling computers to see, identify and process images in the same way that human vision does, and then provide the appropriate output.
Initially computer vision only worked in limited capacity but due to advance innovations in deep learning and neural networks, the field has been able to take great leaps in recent years and has been able to surpass humans in some tasks related to detecting and labeling objects.
The Contribution of Deep Learning in Computer Vision
While there are still significant obstacles in the path of human-quality computer vision, Deep Learning systems have made significant progress in dealing with some of the relevant sub-tasks. The reason for this success is partly based on the additional responsibility assigned to deep learning systems.
It is reasonable to say that the biggest difference with deep learning systems is that they no longer need to be programmed to specifically look for features. Rather than searching for specific features by way of a carefully programmed algorithm, the neural networks inside deep learning systems are trained. For example, if cars in an image keep being misclassified as motorcycles then you don’t fine-tune parameters or re-write the algorithm. Instead, you continue training until the system gets it right.
With the increased computational power offered by modern-day deep learning systems, there is steady and noticeable progress towards the point where a computer will be able to recognize and react to everything that it sees.
Application of Computer Vision
The field of Computer Vision is too expansive to cover in depth. The techniques of computer vision can help a computer to extract, analyze, and understand useful information from a single or a sequence of images. There are many advanced techniques like style transfer, colorization, action recognition, 3D objects, human pose estimation, and much more but in this article we will only focus on the commonly used techniques of computer vision. These techniques are: –
Image Classification
Image Classification with Localization
Object Segmentation
Object Detection
So in this article we will go through all the above techniques of computer vision and we will also see how deep learning is used for the various techniques of computer vision in detail. To avoid confusion we will distribute this article in a series of multiple blogs. In first blog we will see the first technique of computer vision which is Image Classification and we will also explore that how deep learning is used in Image Classification.
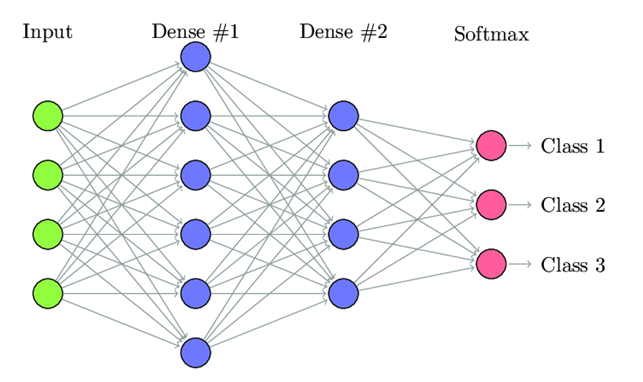
Image Classification
Image classification is the process of predicting a specific class, or label, for something that is defined by a set of data points. Image classification is a subset of the classification problem, where an entire image is assigned a label. Perhaps a picture will be classified as a daytime or nighttime shot. Or, in a similar way, images of cars and motorcycles will be automatically placed into their own groups.
There are countless categories, or classes, in which a specific image can be classified. Consider a manual process where images are compared and similar ones are grouped according to like-characteristics, but without necessarily knowing in advance what you are looking for. Obviously, this is an onerous task. To make it even more so, assume that the set of images numbers in the hundreds of thousands. It becomes readily apparent that an automatic system is needed in order to do this quickly and efficiently.
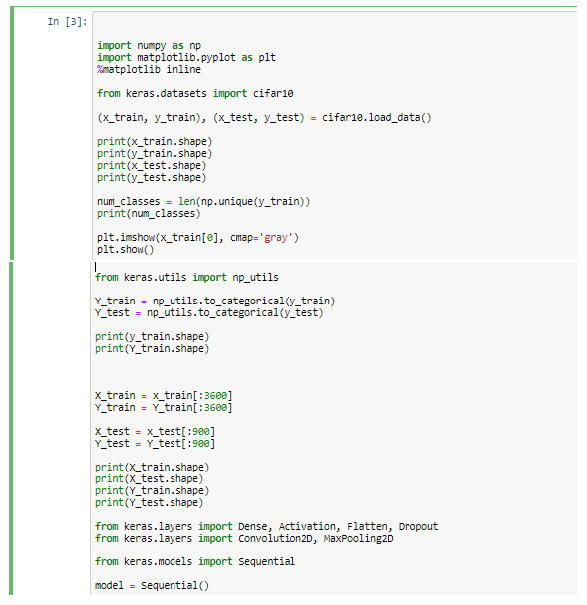
There are many image classification tasks that involve photographs of objects. Two popular examples include the CIFAR-10 and CIFAR-100 datasets that have photographs to be classified into 10 and 100 classes respectively.
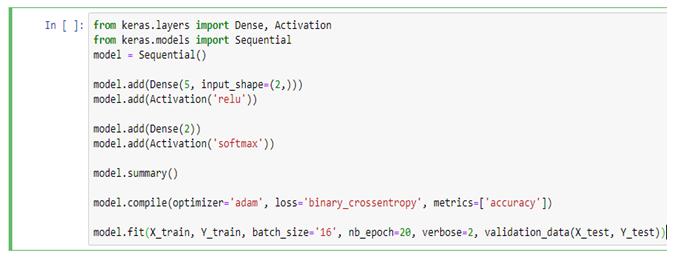
Deep learning for Image Classification
The deep learning architecture for image classification generally includes convolutional layers, making it a convolutional neural network (CNN). A typical use case for CNNs is where you feed the network images and the network classifies the data. CNNs tend to start with an input “scanner” which isn’t intended to parse all the training data at once. For example, to input an image of 100 x 100 pixels, you wouldn’t want a layer with 10,000 nodes.
Rather, you create a scanning input layer of say 10 x 10 which you feed the first 10 x 10 pixels of the image. Once you passed that input, you feed it the next 10 x 10 pixels by moving the scanner one pixel to the right. This technique is known as sliding windows.
Following Layers are used to build Convolutional Neural Networks:
INPUT [32x32x3] will hold the raw pixel values of the image, in this case an image of width 32, height 32, and with three color channels R,G,B.
CONV layer will compute the output of neurons that are connected to local regions in the input, each computing a dot product between their weights and a small region they are connected to in the input volume. This may result in volume such as [32x32x12] if we decided to use 12 filters.
RELU layer will apply an element wise activation function, such as the max(0,x)max(0,x)thresholding at zero. This leaves the size of the volume unchanged ([32x32x12]).
POOL layer will perform a downsampling operation along the spatial dimensions (width, height), resulting in volume such as [16x16x12].
FC (i.e. fully-connected) layer will compute the class scores, resulting in volume of size [1x1x10], where each of the 10 numbers correspond to a class score, such as among the 10 categories of CIFAR-10. As with ordinary Neural Networks and as the name implies, each neuron in this layer will be connected to all the numbers in the previous volume.
Output of the Model History
In this way, ConvNets transform the original image layer by layer from the original pixel values to the final class scores. Note that some layers contain parameters and other don’t. In particular, the CONV/FC layers perform transformations that are a function of not only the activations in the input volume, but also of the parameters (the weights and biases of the neurons). On the other hand, the RELU/POOL layers will implement a fixed function. The parameters in the CONV/FC layers will be trained with gradient descent so that the class scores that the ConvNet computes are consistent with the labels in the training set for each image.
Conclusion
The above content focuses on image classification only and the architecture of deep learning used for it. But there is more to computer vision than just classification task. The detection, segmentation and localization of classified objects are equally important. We will see these in next blog.
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now. To learn more about Data Analyst with R Course – Enrol Now. To learn more about Big Data Course – Enrol Now.
To learn more about Machine Learning Using Python and Spark – Enrol Now. To learn more about Data Analyst with SAS Course – Enrol Now. To learn more about Data Analyst with Apache Spark Course – Enrol Now. To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.