This is the 4th part of the series on visualization using Python programming language, where we will continue our discussion on the Seaborn library. Now that you have become familiar with the basics of the Seaborn library, you will be learning specific skills such as learning to create a box plot using Seaborn. So, let’s begin.
Seaborn library offers a list of pre-defined methods to create semi-flexible plots in Python and one of them is. boxplot() method. But what is a box plot?
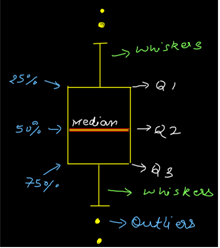
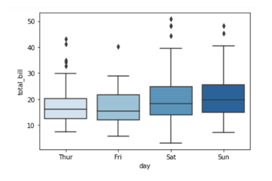
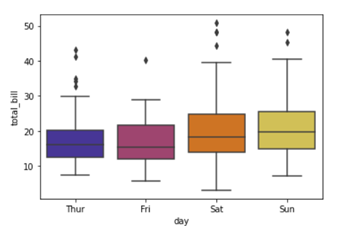
Answer:- A box plot often known as box and whisker plot is a graph created to visualize the distribution of numerical data and skewness through displaying the data quartiles (or percentiles) and median.
Creating a box plot
Let’s begin by importing the Seaborn and Matplotlib library.
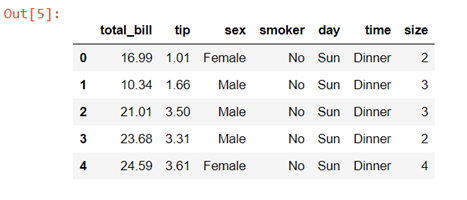
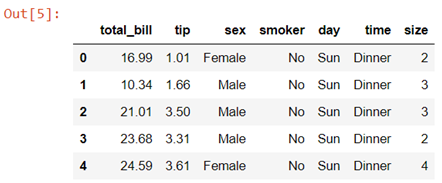
We will again be using the tips dataset which is a pre-defined dataset in Seaborn
Data description:- This is a dataset of a restaurant which keeps a record of the amount of bill paid by a customer, tip amount over the total bill paid, gender of the customer, whether he or she was a smoker or not, the day on which they ate at the restaurant, what was the time when they ate at the restaurant and the size of the table they booked.
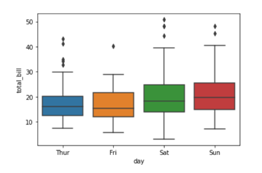
To create a box plot we will be using .boxplot() method.
On the x axis we have day column having categorical data type and on the y axis we have total_bill column having numerical data type. Thus for each day with the help of a box plot we will be able to visualize how the total_bill changes around its median value.
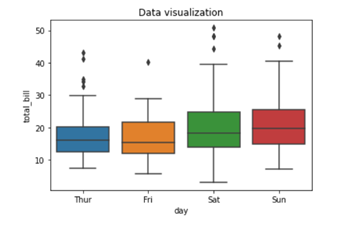
To add title to the graph we can use. title() method from the Matplotlib library
To add color to your graph you can use palette argument
We are adding a list of palette colors in this blog down below:-
You can replace the color mentioned in the above code to see which color variations you would prefer in your graph. For example
Here we are using color palette ‘CMRmap’ to change my graph color from different shades of blues to a completely different color range i.e. from blues to orange, violet, pale yellow etc.
This tutorial hopefully, has clarified the concept and you can now create boxplots with Seaborn. Since this is a series you need to keep track of all the parts to be a visualization expert as we take you through the process step by step. Follow the Dexlab Analytics blog to access more informative posts on different topics including python for data analysis.
Go through the video tutorial attached below to get more in-depth knowledge.
In this 3rd part of the visualization series using Python programming language, we are going to introduce you to the Seaborn Library. Seaborn is a visualization library which is built on top of Matplotlib library in Python. This library helps us build method based plots which when combined with Matplotlib library methods lets us build flexible graphs.
In this tutorial we will be using tips data, which is a pre-defined dataset in the Seaborn library.
So let’s begin by importing the Seaborn library and giving it a sudo name sns. We will also be importing Matplotlib library to add more attributes to our graphs.
To load the tips data set we will be using .load_dataset() method.
Data description:- This is a dataset of a restaurant which keeps a record of the amount of bill paid by a customer, tip amount over the total bill paid, gender of the customer, whether he or she was a smoker or not, the day on which they ate at the restaurant, what was the time when they ate at the restaurant and the size of the table they booked.
In case while loading the dataset you see a warning box appear on the screen you don’t need to worry , you haven’t done anything wrong. These FutureWarning boxes appear to make you aware that in the future there might be some changes in the library or methods you are using.
You can simply use the .simplefilter() method from the warning library to make them disappear.
Here the category argument helps you decide which type of warning you want to ignore.
Creating a bar plot in Seaborn
Now let’s quickly go ahead and create a bar plot with the help of .barplot() method.
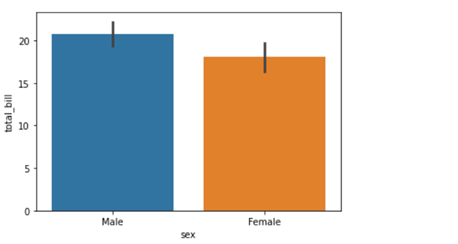
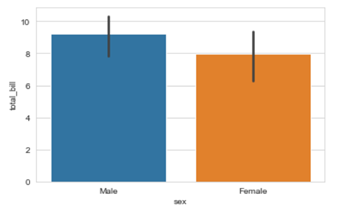
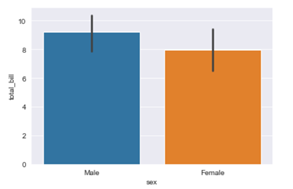
In the above line of code we are using column named sex on the x axis and total_bill on the y axis. But this bar plot is very different from the bar plot which we usually make. The basic concept of a bar plot is to check the frequency but here we are also mentioning the y axis data which in general is not the case with a normal bar plot, that is, we get the frequency on the y axis when we are plotting a bar graph. So what does the above code do?
The above code compares the average of the category. In our case the above graph shows that the average bill of male is higher than the average bill of female. In case you want to plot a graph showing the average variation of bill around the mean (Standard deviation) you can use estimator argument within the .barplot() to do so.
Also if you want to change the background of your graph you can easily do so by using .set_style() method.
The vertical bars between the graph are called the error bars and they tell you how far from your mean or standard deviation by max data varies.
How to add Matplotlib attributes to your Seaborn graphs
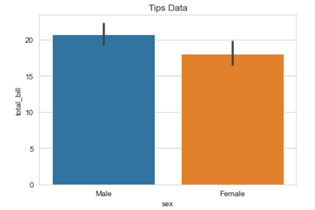
Matplotlib methods can be imported and added to the Seaborn graphs to make them more presentable and flexible. Here we will be adding a title in our graph by using .title() method from the Matplotlib library.
You can use other Matplotlib methods like .legend(),xlabel(),.ylabel() etc,. to add more value to your graphs.
The video tutorial attached below will further help you clarify your ideas regarding the Seaborn library. Follow the series to gain expertise in visualization with Python programming language. Keep on following the Dexlab Analytics blog for reading more informative posts on Python for data science training.
In the last blog that covered Part 1 of the visualization series using Python programming language, we have learned the basics of the Matplotlib Library. Now that our grasp on the basics is strong we would move further. Let’s break it all down with a more formal introduction of Matplotlib’s Object Oriented API. This means we will instantiate figure objects and then call methods or attributes from that object.
Introduction to the Object Oriented Method
The main idea in using the more formal Object Oriented method is to create figure objects and then just call methods or attributes off of that object. This approach is nicer when dealing with a canvas that has multiple plots on it.
How to make multiple plots using .add_axes()
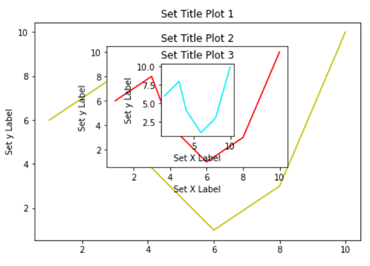
To begin, we create a figure instance. Then we can add axes to that figure where .figure()is a method which helps us create an empty canvas and then we use .add_axes() method to give the position where the plot is to be made. The positional arguments [left, bottom, width, height] help us decide from where the graph should begin within the canvas and what should be the width and the height of the graph. Since the area of the graph is 100% (1.0), the range of the positional argument should be between 0 and 1 and in case you want to plot the graph half within and half outside the canvas, you can go beyond the specified range depending upon your needs.
Let’s quickly get to the coding part now.
In the above line of codes we are simply importing the Matplotlib library and creating a data which we want to plot.
plt.figure()method is helping us create an empty canvas and then we are giving the positional values to the .add_axes() method. As you can see we are using a variable named fig to save our canvas and then using the same variable as an object to add an axes to the canvas. Now all we need to do is use that axes to build are graph by adding x and y data.
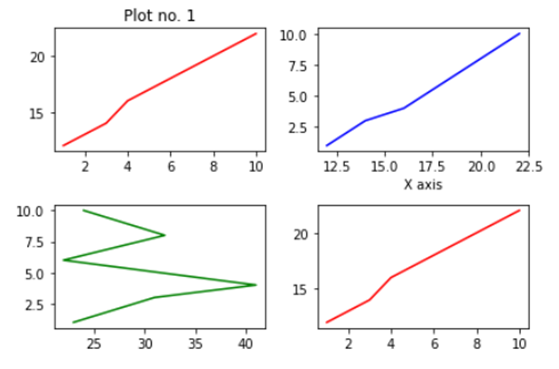
Now you must be wondering why we aren’t able to see a plot in the corner of the canvas? It is because this procedure works only if we were to build multiple plots. So now let’s see how we can use the .add_axes() method to build multiple plots on top of each other.
In the above line of codes we are creating three axes and each axes is smaller than the other so that we are able to plot multiple graphs on top of each other.
Here we are making three different graphs and each graph has its own title and x axis and y axis labels. But to add title and axis labels we are now using .set_title(), .set_xlabel(), and .set_ylabel() instead of .title(), .xlabel() and .ylabel(). In axes2.plot() we are also using RGB color instead of using the predefined color in .plot() method. You can use your favorite color too by simply typing RGB color picker in your Google search and copy pasting the color code in the .plot() method. After running the above code we get the following graph:-
How to make multiple plots using .subplots()
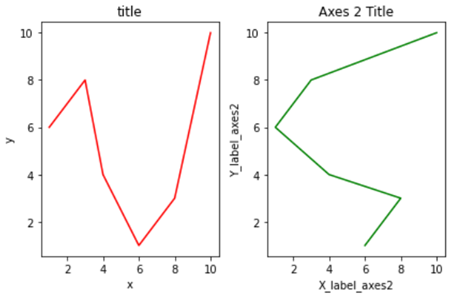
.subplots() method is similar to the previous .subplot() method, the only difference is that now we use it on a canvas.
In the .subplots() we do not mention the plot number instead we use plot indexing method to build graph.
As you can see we are accessing the index number to build our plot and then using .tight_layout() method to keep the graphs from overlapping. After running the above code we get the following graphs:-
Do not forget to check out the video tutorial attached below to learn how this method works. Keep following the series to upgrade your skills and to explore more informative posts on topics like Python Programming trainingyou need to follow the Dexlab Analytics blog.
Matplotlib is the “grandfather” library of data visualization with Python. It was created by John Hunter. He created it to try replicating MatLab’s (another programming language) plotting capabilities in Python. So, if you are already familiar with matlab, matplotlib will feel natural to you.
This library gives you the flexibility to plot the graphs the way you want. You can start with a blank canvas and plot the graph on that canvas wherever you want. You can make multiple plots on top of each other, change the line type, change the line color using predefined colors or hex codes, line width etc.
Installation
Before you begin you’ll need to install matplotlib first by using the following code:-
There are two ways in which you can built matplotlib graphs:-
Method based graphs
Object-oriented graphs
Method Based Graphs in Matplotlib:-
There are pre-defined methods in matplotlib library which you can use to create graphs directly using python language for example:-
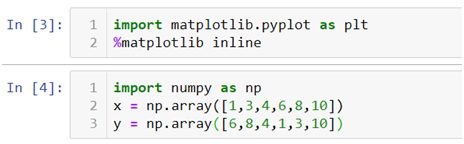
Where, import matplotlib.pyplot as plt this code is used to import the library, %matplotlib inline is used to keep the plot within the parameters of the jupyter notebook, import numpy as np and x = np.array([1,3,4,6,8,10]) is used to import the numpy (numerical python) library and create an array x and plt.plot(x) is used to plot the distribution of the x variable.
We can also use .xlabel(), .ylabel() and .title() methods print x axis and y axis labels and title on the graph.
If you want to add text within your graph you can either use .annotate() method or .text() method.
Creating Multiplots
You can also create multiple plots by using .subplot() method by mentioning the number of rows and columns in which you want your graphs to be plotted. It works similar to the way you mention the number of rows and columns in a matrix.
You can add title, axis labels, texts etc., on each plot separately. In the end you can add .tight_layout() to solve the problem of overlapping of the graphs and to make the labels and scales visible.
Check out the video attached below to get an in-depth understanding of how Matplotlib works. This is a part of a visualization series using Python programming language. So, stay tuned for more updates. You can discover more such informative posts on the Dexlab Analytics blog.
A business organization has to deal with a massive amount of data streaming from myriad sources, and data warehousing refers to the process of collection and storage of that data that needs to be analyzed to glean valuable business insight. Data warehousing plays a crucial role in business intelligence. The concept originated in the 1980s, it basically involves data extraction from disparate sources which later gets processed and post formatting the data stays in the system ready to be utilized for taking important decisions.
Data warehouse basically performs the task of running an analysis on the stored data which could be both structured and unstructured even semi-structured, however, the data that is in the warehouse cannot be modified. Data warehousing basically helps companies gain insight regarding factors influencing business, and they could use the data insight to formulate new strategies, developing products and so on. This highly skilled task demands professionals who have a background in Data science using python training.
What are the different steps in data warehousing?
Data warehousing involves the following steps
Transactional data extraction: In this step, the data is extracted from multiple sources available and loaded into the system.
Data transformation: The transactional data extracted from different sources need to be transformed and it would need relating as well.
Building a dimensional model: A dimensional model comprising fact and dimension tables are built and the data gets loaded.
Getting a front-end reporting tool: The tool could be built or, purchased, a crucial decision that needs much deliberation.
Benefits of data warehousing
An edge over the competition
This is undeniably one benefit every business would be eager to reap from data warehousing. The data that is untapped could be the source of valuable information regarding risk factors, trends, customers and so many other factors that could impact the business. Data warehousing collates the data and arranges them in a contextual manner that is easy for a company to access and utilize to make informed decisions.
Enhanced data quality
Since data pooled from different sources could be structured or, unstructured and in different formats, working with such data inconsistency could be problematic and data warehousing takes care of the issue by transforming the data into a consistent format. The standardized data that easily conforms to the analytics platform can be of immense value.
Historical data analysis
A data warehouse basically stores a big amount of data and that includes historical data as well. Such data are basically old records of the company regarding sales, employee data, or, product-related information. Now the historical data belonging to different time periods need to be analyzed to predict upcoming trends.
Smarter business intelligence
Since businesses now rely on data-driven insight to devise strategies, they need access to data that is consistent, error-free, and high quality. However, data coming from numerous sources could be erroneous and irrelevant. But, data warehousing takes care of this issue by formatting the data to make it consistent and free from any error and could be analyzed to offer valuable insight that could help the management take decisions regarding sales, marketing, finance.
High ROI
Building a data warehouse requires significant investment but in the long term, the revenue that it generates can be significant. In fact, keen business intelligence now plays a crucial role in determining the success of an organization and with data warehousing the organizations can have access to data that is consistent and high quality thus enabling the company to derive actionable intel. When a company implements such insight in making smarter strategies, they do gain in the long run.
Data warehousing plays a significant role in collating and storing valuable data that fuels a company’s business decisions. However, given the specialized nature of the task, one must undergo Data Science training, to learn the nuances. The field of big data has plenty of opportunities for the right candidates.
Big data is certainly is getting a lot of hype and for good reasons. Different sectors ranging from business to healthcare are intent on harnessing the power of data to find solutions to their most imminent problems. Huge investments are being made to build models, but, there are some niggling issues that are not being resolved.
So what are the big challenges the data science industry is facing?
Managing big data
Thanks to the explosion of information now the amount of data being created every year is adding to the already overstocked pile, and, most of the data we are talking about here is unstructured data. So, handling such a massive amount of raw data that is not even in a particular database is a big challenge that could only be overcome by implementing advanced tools.
Lack of skilled personnel
One of the biggest challenges the data science industry has to deal with is the shortage of skilled professionals that are well equipped with Data Science training. The companies need somebody with specific training to manage and process the datasets and present them with the insight which they can channelize to develop business strategies. Sending employees to a Data analyst training institute can help companies address the issue and they could also consider making additional efforts for retaining employees by offering them a higher remuneration.
Communication gap
One of the challenges that stand in the way, is the lack of understanding on the part of the data scientists involved in a project. They are in charge of sorting, cleaning, and processing data, but before they take up the responsibility they need to understand what is the goal that they are working towards. When they are working for a business organization they need to know what the set business objective is, before they start looking for patterns and build models.
Data integration
When we are talking about big data, we mean data pouring from various sources. The myriad sources could range from emails, documents, social media, and whatnot. In order to process, all of this data need to be combined, which can be a mammoth task in itself. Despite there being data integration tools available, the problem still persists. Investment in developing smarter tools is the biggest requirement now.
Data security
Just the way integrating data coming from different sources is a big problem, likewise maintaining data security is another big challenge especially when interconnectivity among data sources exists. This poses a big risk and renders the data vulnerable to hacking. In the light of this problem, procuring permission for utilizing data from a source becomes a big issue. The solution lies in developing advanced machine learning algorithms to keep the hackers at bay.
Data validity
Gaining insight from data processing could only be possible when that data is free from any sort of error. However, sometimes data hailing from different sources could show disparity regardless of being about the same subject. Especially in healthcare, for example, patient data when coming from two different sources could often show dissimilarity. This poses a serious challenge and it could be considered an extension of the data integration issue. Advanced technology coupled with the right policy changes need to be in place to address this issue, otherwise, it would continue to be a roadblock.
The challenges are there, but, recognizing those is as essential as continuing research work to finding solutions. Institutes are investing money in developing data science tools that could smoothen the process by eliminating the hurdles. Accessing big data courses in delhi, is a good way to build a promising career in the field of data science, because despite there being challenges the field is full big opportunities.
The term big data refers to the massive amount of data being generated from various sources that need to be sorted, processed, and analyzed using advanced data science tools to derive valuable insight for different industries. Now, big data comprises structured, semi-structured, and mostly unstructured data. Processing this huge data takes skill and expertise and which only someone with Data Science training would be able to do.
The concept of big data is relatively new and it started emerging post the arrival of internet closely followed by the proliferation of advanced mobile devices, social media platforms, IoT devices, and all other myriad platforms that are the breeding grounds of user-generated data. Managing and storing this data which could be in text, audio, image formats is essential for not just businesses but, for other sectors as well. The information data holds can help in the decision-making process and enable people to understand the vital aspects of an issue better.
The characteristics of big data
Now, any data cannot be classified as big data, there are certain characteristics that define big data and getting in-depth knowledge regarding these characteristics can help you grasp the concept of big data better. The main characteristics of big data could be broken down into 5Vs.
What are the 5Vs of data?
The 5Vs of data basically refers to the core elements of big data, the presence of which acts as a differentiating factor. Although many argue in favor of the essential 3 VS, other pundits prefer dissecting data as per 5Vs. These 5Vs denote Volume, Velocity, Variety, Veracity, Value the five core factors but, not necessarily in that order. However, Volume would always be the element that lays the foundation of big data. Pursuing a Data Science course would further clarify your idea of big data.
Volume
This concept is easier to grasp as it refers to the enormous amount of data being generated and collected every day. This amount is referred to as volume, the size of data definitely plays a crucial role as storing this data is posing a serious challenge for the companies. Now the size of the data would vary from one industry to the other, the amount of data an e-commerce site generates would vary from the amount generated on a popular social media platform like Facebook. Now, only advanced technology could handle and process and not to mention deal with the cost and space management issue for storing such large volumes of data.
Velocity
Another crucial feature of big data is velocity which basically refers to the speed at which data is generated and processed, analyzed, and moved across platforms to deliver insight in real-time if possible. Especially, in a field like healthcare the speed matters, crucial trading decisions that could result in loss or profit, must also be taken in an instant. Only the application of advanced data science technology can collect data points in an instant and process those at a lightning speed to deliver results. Another point to be noted here is the fact that just like volume the velocity of data is also increasing.
Variety
The 3rd V refers to the variety, a significant aspect of big data that sheds light on the diversity of data and its sources. As we already know that the data now hails from multiple sources, including social media platforms, IoT devices, and whatnot. The problem does not stop there, the data is also diverse in terms of format such as videos, texts, images, audios and it is a combination of structured and unstructured data. In fact, almost 80%-90% of data is unstructured in nature. This poses a big problem for the data scientists as sorting this data into distinct categories for processing is a complicated task. However, with advanced data science technologies in place determining the relationship among data is a lot hassle-free process now.
Veracity
It is perhaps the most significant aspect of all other elements, no matter how large datasets you have and in what variety, if the data is messy and inaccurate then it is hardly going to be of any use. Data quality matters and dirty data could be a big problem especially because of the fact that data comes from multiple sources. So, you have apparently no control, the problems range from incomplete data to inconsistency of information. In such situations filtering the data to extract quality data for analysis purposes is essential. Pursuing Data science using python training can help gain more skill required for such specific tasks.
Value
The 5th V of big data refers to the value of the data we are talking about. You are investing money in collecting, storing, and processing the big data but if it does not generate any value at the end of the day then it is completely useless. Managing this massive amount of data requires a big investment in advanced infrastructure and additional resources, so, there needs to be ROI. The data teams involved in the process of collecting, sorting, and analyzing the data need to be sure of the quality of data they are handling before making any move.
The significance of big data in generating valuable insight is undeniable and soon it would be empowering every industry. Further research in this field would lead to the development of data science tools for handling big data issues in a more efficient manner. The career prospects in this field are also bright, training from a Data analyst training institute can help push one towards a rewarding career.
With the big data field experiencing an exponential growth, the need for skilled professionals to sort, analyze data is also growing. Not just businesses but other sectors too are realizing the significance of big data to leverage their growth.
In order to move forward with confidence, big data can help. With digitization the amount of data being generated is also increasing and to process such vast amount of data skilled professionals are required.
The field is surely opening up for the young generation who needs the right blend of skill and passion to land high-paying jobs in the field. Help is available in the form of training institutes which offer cutting edge courses like big data training in gurgaon.
So how much data we are talking about here?
The amount of data that is generated now thanks to IOT, stands at more than 2.5 quintillion bytes of data and this amount is being generated everyday as per the sixth edition of DOMO’s report. By this current year it was estimated that every person will create 1.7MB of data every second.
With IOT being primarily the reason behind this data proliferation, we are looking at a huge data avalanche heading our way comprising mostly unstructured data.
All of the data generated along with past stock are of importance now as crucial sectors like banking, healthcare, communication, manufacturing, finance are being reliant on data to extract valuable information for taking pivotal decisions.
A Data analyst training institute can be of immense value as they take up the responsibility of shaping data skills of the professionals needed by these sectors.
The expanding field of data requires data experts
Processing through mountains of unstructured data, cleaning it, preparing it for further processing and then analyzing it to find pattern takes skill which could be attained by pursuing Data science using python training.
As per survey findings, there is a huge gap in the demand and supply chain. The field might be expanding and organizations being eager to embrace the power of data, but, the dearth of professionals is posing a big problem which is why the companies in dire need of trained workforce are taking the salary graph higher to lure talent.
However, there are courses available such as business analyst training delhi, that are aimed at training up the new generation of geeks to handle the big data, thereby helping them carve out successful career avenues.
What are the trending jobs in this sector?
Data scientist
A data scientist basically works with a business organization to process raw data, cleaning, analyzing the data to detect patterns that could be of immense value for the organization concerned. A data scientist can play a big role in helping a company decide the next business strategy. They also create algorithms and build machine learning models. Data Science training can help you be prepared for such a high-profile position.
In the USA, a data scientist can earn upto $1,13,309, while in India it could be ₹500,000 per annum.
Data Engineer
A data engineer is a person who is well versed in programming and SQL, and works with stored data. He basically has to work with data systems and is charged with the responsibility of creating data infrastructure and maintaining it. A data engineer also works to build data pipelines to channelize valuable data to data analysts and scientists fast.
The salary range of a data engineer in the USA could be near $128,722 per annum and in India it could hover around ₹839,565.
Data Analyst
The data analyst is basically the guy who runs the show as he is in charge of manipulating huge data sets. He is involved with the tasks of gathering data and he also creates databases, analytics models, extracts information and analyzes that to aid in decision making. Not just that but he also needs to present the insight into a format that everybody can grasp.
If you aim to grab this job then you could expect a pay around $62,453 in United States. In India that number might be around ₹419135 on average.
BI Analyst
A BI Analyst has to put his entire focus on analyzing data in order to identify the potential areas for a company to prosper along with the main obstacles standing in their way to success. They have to update the database on a continuous basis along with monitoring the performance of rivals in the field concerned.
Along with possessing sharp business acumen, he must be proficient in data handling. He basically offers data-driven insight while donning the role of a consultant.
A background in computer science or, business administration, statistics, finance could work in your favor if only you can couple that with big data courses in delhi.
A skilled BI Analyst could expect a pay around $94906 in the USA, and in India they might get upto ₹577745.
There are more lucrative job opportunities and exciting job roles awaiting the next generation of professionals that can help them build a highly successful career. Regardless of which background they hail from undergoing a Data Science course can push them in the right direction.
Data mining refers to processing mountainous amount of data that pile up, to detect patterns and offer useful insight to businesses to strategize better. The data in question could be both structured and unstructured datasets containing valuable information and which if and when processed using the right technique could lead towards solutions.
Enrolling in a Data analyst training institute, can help the professionals involved in this field hone their skills. Now that we have learned what data mining is, let’s have a look at the data mining techniques employed for refining data.
Data cleaning
Since the data we are talking about is mostly unstructured data it could be erroneous, corrupt data. So, before the data processing can even begin it is essential to rectify or, eliminate such data from the data sets and thus preparing the ground for the next phases of operations. Data cleaning enhances data quality and ensures faster processing of data to generate insight. Data Science training is essential to be familiar with the process of data mining.
Classification analysis
Classification analysis is a complicated data mining technique which basically is about data segmentation. To be more precise it is decided which category an observation might belong to. While working with various data different attributes of the data are analyzed and the class or, segments they belong to are identified, then using algorithms further information is extracted.
Regression analysis
Regression analysis basically refers to the method of deciding the correlation between variables. Using this method how one variable influences the other could be decided. It basically allows the data analyst to decide which variable is of importance and which could be left out. Regression analysis basically helps to predict.
Anomaly detection
Anomaly detection is the technique that detects data points, observations in a dataset, that deviate from an expected or, normal pattern or behavior. This anomaly could point to some fault or, could lead towards the discovery of an exception that might offer new potential. In fields like health monitoring, or security this could be invaluable.
Clustering
This data mining technique is somewhat similar to classification analysis, but, different in the way that here data objects are grouped together in a cluster. Now objects belonging to one particular cluster will share some common thread while they would be completely different from objects in other clusters. In this technique visual presentation of data is important, for profiling customers this technique comes in handy.
Association
This data mining technique is employed to find some hidden relationhip patterns among variables, mostly dependent variables belonging to a dataset. The recurring relationships of variables are taken into account in this process. This comes in handy in predicting customer behavior, such as when they shop what items are they likely to purchase together could be predicted.
Tracking patterns
This technique is especially useful while sorting out data for the businesses. In this process while working with big datasets, certain trends or, patterns are recognized and these patterns are then monitored to draw a conclusion. This pattern tracking technique could also aid in identifying some sort of anomaly in the dataset that might otherwise go undetected.
Big data is accumulating every day and the more efficiently the datasets get processed and sorted, the better would be the chances of businesses and other sectors be accurate in predicting trends and be prepared for it. The field of data science is full of opportunities now, learning Data science using python training could help the younger generation make it big in this field.