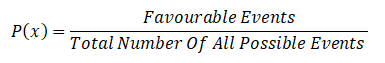With 2.5 quintillion bytes of data being created everyday companies are scrambling to build models and hire experts to extract information hidden in massive unstructured datasets and the data scientists have become the most sought-after professionals in the world. The job portals are full of job postings looking for data scientists whose resume has the perfect combination of skill and experience. In this world which is being driven by the data revolution, achieving your big data career dreams need a little bit of planning and strategizing. So, here is a step-by-step guide for you.
Grabbing a high paying and skilled data job is not going to be easy, industries will only invest money on individuals with the right skillset. Your job responsibility will involve wading through tons of unstructured data to find pattern and meaning, making forecasts regarding marketing trends, customer behavior and deliver the insight in a presentable format to the company on the basis of which they are going to be strategizing.
So, before you even begin make sure that you have the tenacity and enthusiasm required for the job. You would need to undergo Data science using python training, in order to gain the necessary skills and knowledge and since this is an evolving field you should be ready to constantly upskill yourself and stay updated about the latest developments in the field.
Are you ready? If it’s a resounding yes, then, without wasting any more time let’s get straight to the point and explore the steps that will lead you to become a data scientist.
Step 1: Complete education
Before you pursue data science, you must complete your bachelors degree, if you are coming from computer science, applied mathematics, or, economics that could give you a head start. However, you need to undergo Data Science training, post that to acquire the required skillset.
Step 2: Gain knowledge of Mathematics and statistics
You do not need to have a PHD in either, but, since both are at the core of the data science you must have a good grasp on applied mathematics and statistics. Your task would require you to have knowledge regarding linear algebra, probability & statistics. So, your first step would be to update yourself and be familiar with the concepts if you happen to hail from a non-science background so that you can sail through the rest of the journey.
Step 3: Get ready to do programming
Just like mathematics and statistics, having a grip on a programming language preferably Python, is essential. Now, why do you need to learn coding? Well, coding is important as you have to work with large datasets comprising mostly unstructured data and coding will help you to clean, organize, read data and also process it. Now the stress is on Python because it is one of the widely used languages in the data science community and is comparatively easier to pick up.
Step 4: Learn Machine Learning
Machine learning plays a crucial role in data science as it helps finding patterns in data and making predictions. Mastering machine learning techniques would enable you develop algorithms for the models and create an automated system that enables you to make predictions in real-time. Consider undergoing a Machine Learning training gurgaon.
Step 5: Learn Data Munging, Visualization, and Reporting
It has been mentioned before that you would mostly be handling unstructured data, which means in order to process that data you must transform that data into a format that is easy to work with. Data munging helps you achieve that. Data visualization is again a must-have skill for a data scientist as it allows you to visually present your data findings that is easy to understand through graphs, charts, while data reporting lets you prepare and present reports for businesses.
Step 6: Be certified
Now that the field has advanced so much, there is a requirement for professionals who have undergone Data Science course. Doing a certification course would upskill you and arm you with industry knowledge. Reputed institutes like Dexlab Analytics offer cutting edge courses such as Python for data science training. If you just follow this step it would take care of the rest of the worries, the best part of getting your training is that here you will be taught everything from scratch so, no need to fret if you do not know programming language. Your learning would be aided by hands-on training.
Step 7: Practice your skills
You need to test the skills you have acquired and to hone the skills you must explore Kaggle, which lets your access resources you need and this platform also allows you to take part in competitions that further helps you sharpen your abilities. You should also keep on practicing by doing projects in order to put the theories into action.
Step 8: Work on your soft skills
In order to be a professional data scientist you must acquire soft skills as well. So along with working on your communication skills, you must also need to develop problem solving skills while learning how business organizations function to understand what would be required of you when you assume the role of a data scientist.
Step 9: Get an internship
Now that you have the skill and certification you need experience to get hired, build a resume stressing on the skills you have acquired and search the job portals to land an internship. It would not only enhance your resume, but, it also gives you exposures to real projects, the more projects you handle the better and you would also learn from the experts there.
Step 10: Apply for a job
Once you have gathered enough experience start applying for full-time positions as now you have both skill and experience. But, do not stop learning once you land a job, because this field is growing many changes will happen so you have to mold yourself accordingly. Be a part of the community, network with people, keep on exploring GitHub and find out what other skills you require.

So, those were the steps you need to follow to build a rewarding career in data science. The job opportunities are plenty and to grab the right job you must do big data training in gurgaon. These courses are aimed to prepare individuals for the industry, so get ready for an exciting career!
.