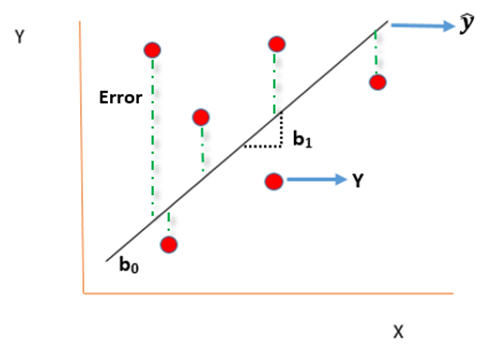
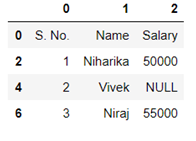
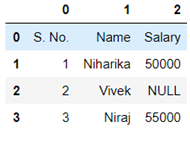
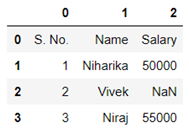
Sampling is a technique in which a predefined number of observation is taken from a large population for the purpose of statistical analysis and research.
There are two types of sampling techniques:-
Random Sampling
Random sampling is a sampling technique in which each observation has an equal probability of being chosen. This kind of sample should be an unbiased representation of the population.
Types of random sampling
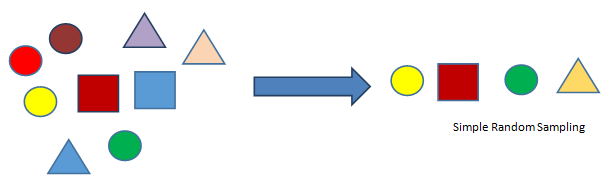
- Simple Random Sampling:- Simple random sampling is a technique in which any observation can be chosen and each observation has an equal probability of being selected.
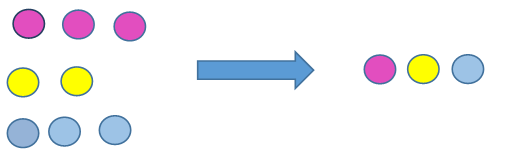
- Stratified Random Sampling:- In this sampling technique we create sub-group of the population with similar attributes and characteristics and then out of those sub-groups we then include each category in our sample with the probability of choosing each observation from the sub-group being equal.
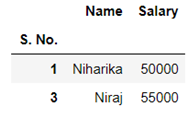
- Systematic Sampling:- This is a sampling technique where the first observation is selected randomly and then every kth element is chosen randomly to be included in our sample.
k= 2, here the first observation is selected randomly and after that every second element is included in the sample.

- Cluster Sampling:- This is a sampling technique in which the data is grouped into small sub-groups called clusters with random categories and then from those clusters random observation is selected which then is included in the sample.
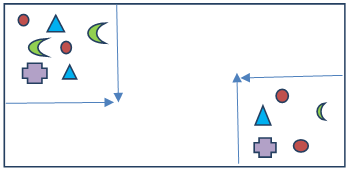
Two clusters are created from which then random observation will be chosen to form the sample.
Non-Random Sampling :- It is a sampling technique in which an element of biasedness is introduced which means that an observation is selected for the sample on the basis of not probability but choice.
Types of non-random sampling:-
- Convenience Sampling:- When a sample observation is drawn from the population based on how comfortable it is for you to take the observation it is called convenience sampling. For example when you have a survey sheet that is to be filled by students from all the departments of your college but you only ask your friends to fill the survey sheet.
- Judgment Sampling:– When the sample observation drawn from the population is based on your professional judgment or past experience, it is called judgment sampling.
- Quota Sampling:– When you draw a sample observation from the population that is based on some specific attribute, it is called quota sampling. For example, taking sample of people over and above 50 years.
- Snow Ball Sampling:– When survey subjects are selected based on referral from other survey respondents, it is called snow ball sampling.
Sampling and Non-sampling errors
Sampling errors:- It occurs when the sample is not representative of the entire population. For example a sample of 10 people with or without COVID-19 cannot tell whether or not the entire population of a country is COVID positive.
Non-sampling error:-This kind of error occurs during data collection. For example, during data collection if you falsely specified a name, it will be considered a non-sampling error.
So, with that this discussion on Sampling wraps up, hopefully, at the end of this you have learned what Sampling is, what are its variations and how do they all work. If you need further clarification, then check out our video tutorial on Sampling attached down the blog. DexLab Analytics provides the best data science course in gurgaon, keep following the blog section to stay updated.
.