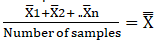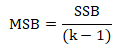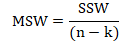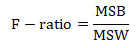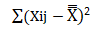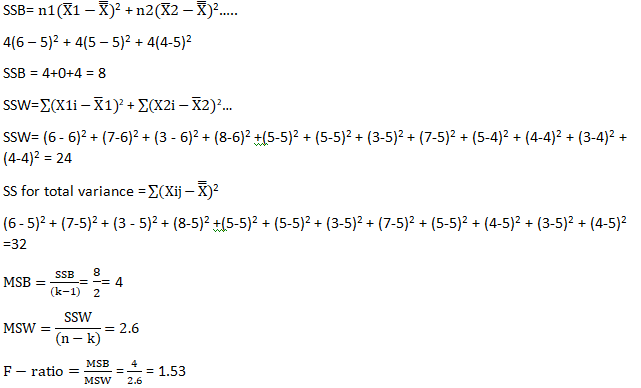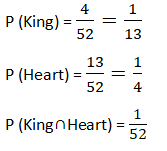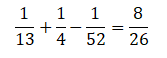In this blog, we are going to be discussing a statistical technique, ANOVA, which is used for comparison.
The basic principal of ANOVA is to test for differences among the mean of different samples. It examines the amount of variation within each of these samples and the amount of variation between the samples. ANOVA is important in the context of all those situations where we want to compare more than two samples as in comparing the yield of crop from several variety of seeds etc.
The essence of ANOVA is that the total amount of variation in a set of data is broken in two types:-
The amount that can be attributed to chance.
The amount which can be attributed to specified cause.
One-way ANOVA
Under the one-way ANOVA we compare the samples based on a single factor. For example productivity of different variety of seeds.
Stepwise process involved in calculation of one-way ANOVA is as follows:-
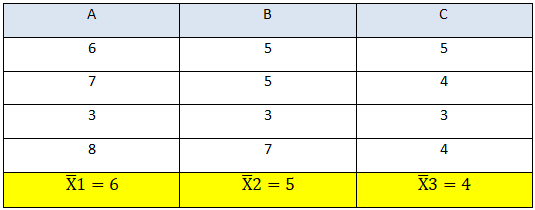
Calculate the mean of each sample X ̅
Calculate the super mean
Calculate the sum of squares between (SSB) samples
Divide the result by the degree of freedom between the samples to obtain mean square between (MSW) samples.
Now calculate variation within the samples i.e. sum of square within (SSW)
Calculate mean square within (MSW)
Calculate the F-ratio
Last but not the least calculate the total variation in the given samples i.e. sum of square for total variance.
Lets now solve a one-way ANOVA problem.
A,B and C are three different variety of seeds and now we need to check if there is any variation in their productivity or not. We will be using one-way ANOVA as there is a single factor comparison involved i.e. variety of seeds.
The f-ratio is 1.53 which lies within the critical value of 4.26 (calculated from the f-distribution table).
Conclusion:- Since the f-ratio lies within the acceptance region we can say that there is no difference in the productivity of the seeds and the little bit of variation that we see is caused by chance.
Two-way ANOVA will be discussed in my next blog so do comeback for the update.
Hopefully, you have found this blog informative, for more clarification watch the video attached down the blog. You can find more such posts on Data Science course topics, just keep on following the DexLab Analytics blog.
Today’s workspace has turned volatile in trying to adjust to the new normal. Along with struggling to stay indoors while living a virtual life, adopting new manners of social distancing, people are also having to deal with issues like job loss, pay cut, or, worse, lack of vacancies. Different sectors are getting hit, except for those driven by cutting edge technology like Data Science, Artificial intelligence. The need to transition into a digital world is greater than ever. As per the World Economic Forum, there would be a greater push towards “digitization” as well as “automation”. This signifies the need for professionals with a background in Data Science, Artificial Intelligence in the future that is going to be entirely data-reliant.
So, what are you going to do? Sit back and wait till the storm passes over or are you going to utilize this downtime to upskill yourself with a Data Science course? With the PM stressing on how the “skill, re-skill and upskill” being the need of the hour, you can hardly afford to lose more time. Since Data Science is one of the comparatively steadier fields, that is growing despite all odds, it is time to acquire data literacy to stay relevant in a workspace that is increasingly becoming data-driven. From healthcare to manufacturing, different sectors are busy decoding the data in hand to go digital in a pandemic ridden world, and employers are looking for people who are willing to push the envelope harder to remain relevant.
What is data literacy?
Before progressing, you must understand what data literacy even means. Data literacy basically refers to having an in-depth knowledge of data that helps the employees work with data to derive actionable information from it and channelizing that to make informed decisions. However, data literacy has a wider meaning and it is not limited to the data team comprising data scientists, no, it takes all the employees in its ambit, so, that the data flow throughout the organization is seamless. Without there being employees who know their way around data, an organization can never realize its dream of initiating a data-driven culture. Having a background in Data science using Python training is the key to achieving data literacy.
The demand for data scientists and data analysts is soaring up
Despite the ominous presence of the pandemic, the demand for Data Science professionals is there and in August, the demand for Data Analysts and Data Scientists soared. As per a recent study, in India, a Data Science professional can expect no less than ₹9.5 lakh per annum. With prestigious institutes like Infosys, IBM India, Cognizant Technology Solutions, Accenture hiring, it is now absolutely mandatory to undergo Data Science training to grab the job opportunities.
Getting Data Science certification can help you close the gap
The skill gap is there, but, that does not mean it could not be taken care of. On the contrary, it is absolutely possible and imperative that you take the necessary step of upskilling yourself to be ready for the Data Science field. Having a working knowledge of data is not enough, you must be familiar with the latest Data Science tools, must possess the knowledge to work with different models, must be familiar with data extraction, data manipulation. All of these skills and more, you would need to master before you go seeking a well-paying job.
Self-study might seem like a tempting idea, but, it is not a practical solution, if you want to be industry-ready then you must know what the industry is expecting from a Data Science professional, and only a faculty comprising industry experts can give you that knowledge while guiding you through a well designed Python for data science training course.
An institute such as DexLab Analytics understands the need of the hour and has a great team of industry professionals and experts to help aspiring Data Scientists and Data Analysts fulfill their dream. Along with offering state-of-the-art Data Science certification courses, they also provide courses like Machine Learning Using Python.
No matter which way you look, upskilling is the need of the hour as the world is busy embracing the power of Data Science. Stop procrastinating and get ready for the future.
In this blog we are discussing automation, a function for automating data preparation using a mix of Python libraries. So let’s start.
Problem statement
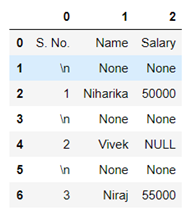
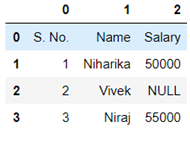
A data containing the following observation is given to you in which the first row contains column headers and all the other rows contains the data. Some of the rows are faulty, a row is faulty if it contains at least one cell with a NULL value. You are supposed to delete all the faulty rows containing NULL value written in it.
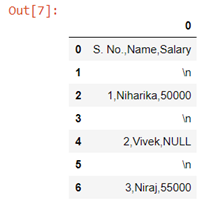
In the table given below, the second row is faulty, it contains a NULL value in salary column. The first row is never faulty as it contains the column headers. In the data provided to you every cell in a column may contain a single word and each word may contain digits between 0 & 9 or lowercase and upper case English letters. For example:
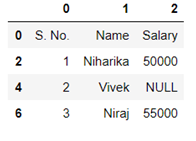
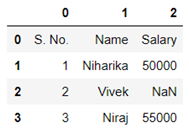
In the above example after removing the faulty row the table looks like this:
The order of rows cannot be changed but the number of rows and columns may differ in different test case.
The data after preparation must be saved in a CSV format. Every two successive cells in each row are separated by a single comma ‘,’symbol and every two successive rows are separated by a new-line ‘\n’ symbol. For example, the first table from the task statement to be saved in a CSV format is a single string ‘S. No., Name, Salary\n1,Niharika,50000\n2,Vivek,NULL\n3,Niraj,55000’ . The only assumption in this task is that each row may contain same number of cells.
Write a python function that converts the above string into the given format.
Write a function:
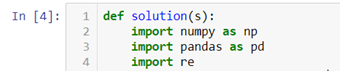
def Solution(s)
Given a string S of length N, returns the table without the Faulty rows in a CSV format.
Given S=‘S. No., Name, Salary\n1,Niharika,50000\n2,Vivek,NULL\n3,Niraj,55000’
The table with data from string S looks as follows:
After removing the rows containing the NULL values the table should look like this:
You can try a number of strings to cross-validate the function you have created.
Let’s begin.
First we will store the string in a variable s
Now we will start by declaring the function name and importing all the necessary libraries.
Creating a pattern to separate the string from ‘\n’ .
Creating a loop to create multiple lists within a list.
In the above code the list is converted to an array and then used to create a dataframe and stored as csv file in the default working directory.
Now we need to split the string to create multiple columns.
The above code creates a dataframe with multiple columns.
Now after dropping the rows with NaN values data looks like
To reset the index we can now use .reset_index() method.
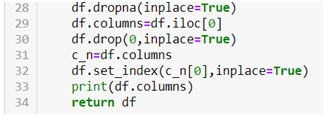
Now the problem with the above dataframe created is that the NULL values are in string format, so first we need to convert them into NaN values and then only we will be able to drop them. For that we will be using the following code.
Now we will be able to drop the NaN values easily by using .dropna() method.
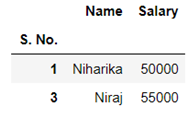
In the above code we first dropped the NaN values then we used the first row of the data set to create column names and then dropped the original row. We also made the first column as index.
Hence we have managed to create a function that can give us the above data. Once created this function can be used to convert a string into dataframe with similar pattern.
Hopefully, you found the discussion informative enough. For further clarification watch the video attached below the blog. To access more informative blogs on Data science using python training related topics, keep on following the Dexlab Analytics blog.
Here’s a video introduction to Automation. You can check it down below to develop a considerable understanding of the same:
The world has finally woken up and smelled the power of data science and now we are living in a world that is being driven by data. There is no denying the fact that new technologies are coming to the fore that are born out of data-driven insight and numerous sectors are also turning towards data science techniques and tools to increase their operational efficiency.
This in turn is also pushing a demand for skilled people in various sectors who are armed with Data Science course or, Retail Analytics Courses to be able to sift through mountains of data to clean it, sort it and analyze it for uncovering valuable information. Decisions that were earlier taken often on the basis of erroneous data or, assumption can now be more accurate thanks to application of data science.
Now let’s take a look at which sectors are benefitting the most from data science
Healthcare
The healthcare industry has adopted the data science techniques and the benefits could already be perceived. Keeping track of healthcare records is easier not just that but digging through the pile of patient data and its analysis actually helps in giving hint regarding health issues that might crop up in near future. Preventive care is now possible and also monitoring patient health is easier than ever before.
The development in the field can also predict which medication would be suitable for a particular patient. Data analytics and data science application is also enabling the professionals in this sector to offer better diagnostic results.
Retail
This is one industry that is reaping huge benefits from the application of data science. Now sorting through the customer data, survey data it is easier to gauge the customers’ mindset. Predictive analysis is helping the experts in this field to predict the personal preference of the consumers and they are able to come up with personalized recommendations that is bound to help them retain customers. Not just that they can also find the problem areas in their current marketing strategy to make changes accordingly.
Transport
Transport is another sector that is using data science techniques to its advantage and in turn it is increasing its service quality. Both the public and private transportation services providers are keeping track of customer journey and getting the details necessary to develop personalized information, they are also helping people be prepared for unexpected issues and most importantly they are helping people reach their destinations without any glitch.
Finance
If so many industries are reaping benefits, Finance is definitely to follow suit. Dealing with valuable data regarding banking transactions, credit history is essential. Based on the data insight it is possible to offer customers personalized financial advice. Also the credit risk issue could be minimized thanks to the insight derived from a particular customer’s credit history. It would allow the financial institute make an informed decision. However, credit risk analytics training would be required for personnel working in this field.
Telecom
The field of telecom is surely a busy sector that has to deal with tons of valuable data. With the application of data science now they are able to find a smart solution to process the data they gather from various call records, messages, social media platforms in order to design and deliver services that are in accordance with customers’ individualistic needs.
Harnessing the power of data science is definitely going to impact all the industries in future. The data science domain is expanding and soon there would be more miracles to observe. Data Science training can help upskill the employees reduce the skill gap that is bugging most sectors.
This is the second part of the probability series, in the first segment we discussed the basic concepts of probability. In this second part we will delve deeper into the topic and discuss the theorems of probability. Let’s find out what these theorems are.
Addition Theorem
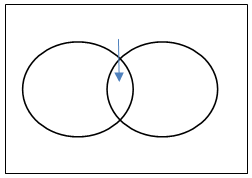
If A and B are two events and they are not necessarily mutually exclusive then the probability of occurrence of at least one of the two events A and B i.e. P(AUB) is given by
Removing the intersections will give the probability of A or B or both.
Example:- From a deck of cards 1 card is drawn, what is the probability the card is king or heart or both?
Total cards 52
P(KingUHeart)= P(King)+P(Heart) ─ P(King∩Heart)
If A and B are two mutually exclusive events then the probability that either A or B will occur is the sum of individual probabilities of the events A and B.
P(A)+P(B), here the combined probability of the two will either give P(A) or P(B)
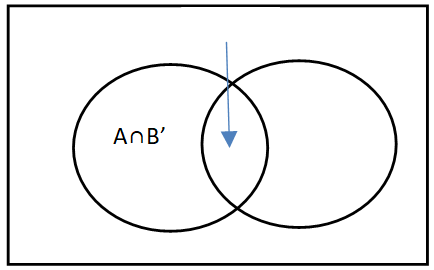
If A and B are two non mutually exclusive events then the probability of occurrence of event A is given by
Where B’ is 1-P(B), that means probability of A is calculated as P(A)=1-P(B)
Multiplication Law
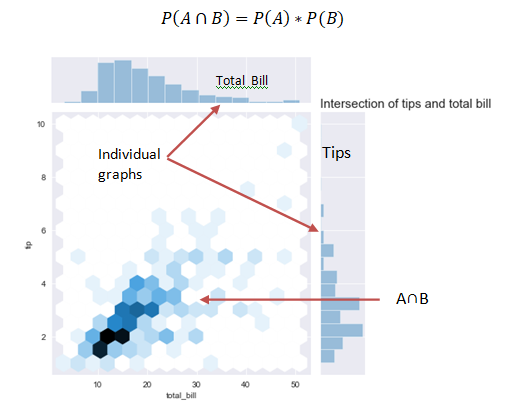
The law of multiplication is used to find the joint probability or the intersection i.e. the probability of two events occurring together at the same point of time.
In the above graph we see that when the bill is paid at the same time tip is also paid and the interaction of the two can be seen in the graph.
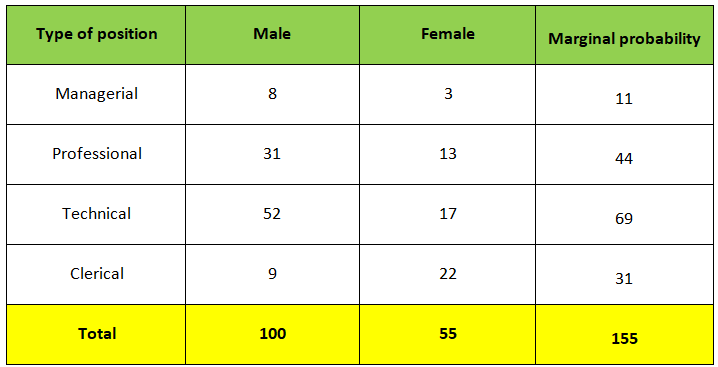
Joint probability table
A joint probability table displays the intersection (joint) probabilities along with the marginal probabilities of a given problem where the marginal probability is computed by dividing some subtotal by the whole.
Example:- Given the following joint probability table find out the probability that the employee is female or a professional worker.
Watch this video down below that further explains the theorems.
At the end of this blog, you must have grasped the basics of the theorems discussed here. Keep on tracking the Dexlab Analytics blog where you will find more discussions on topics related to Data Science training.
The job of a data scientist is one that is challenging, exciting and crucial to an organization’s success. So, it’s no surprise that there is a rush to enroll in a Data Science course, to be eligible for the job. But, while you are at it, you also need to have the awareness regarding the job responsibilities usually bestowed upon the data scientists in a business organization and you would be surprised to learn that the responsibilities of a data scientist differs from that of a data analyst or, a data engineer.
So, what is the role and responsibility of a data scientist? Let’s take a look.
The common idea regarding a data scientist role is that they analyze huge volumes of data in order to find patterns and extract information that would help the organizations to move ahead by developing strategies accordingly. This surface level idea cannot sum up the way a data scientist navigates through the data field. The responsibilities could be broken down into segments and that would help you get the bigger picture.
Data management
The data scientist, post assuming the role, needs to be aware of the goal of the organization in order to proceed. He needs to stay aware of the top trends in the industry to guide his organization, and collect data and also decide which methods are to be used for the purpose. The most crucial part of the job is the developing the knowledge of the problems the business is trying solve and the data available that have relevance and could be used to achieve the goal. He has to collaborate with other departments such as analytics to get the job of extracting information from data.
Data analysis
Another vital responsibility of the data scientist is to assume the analytical role and build models and implement those models to solve issues that are best fit for the purpose. The data scientist has to resort to data mining, text mining techniques. Doing text mining with python course can really put you in an advantageous position when you actually get to handle complex dataset.
Developing strategies
The data scientists need to devote themselves to tasks like data cleaning, applying models, and wade through unstructured datasets to derive actionable insight in order to gauge the customer behavior, market trends. These insights help a business organization to decide its future course of action and also measure a product performance. A Data analyst training institute is the right place to pick up the skills required for performing such nuanced tasks.
Collaborating
Another vital task that a data scientist performs is collaborating with others such as stakeholders and data engineers, data analysts communicating with them in order to share their findings or, discussing certain issues. However, in order to communicate effectively the data scientists need to master the art of data visualization which they could learn while pursuing big data courses in delhi along with deep learning for computer vision course. The key issue here is to make the presentation simple yet effective enough so that people from any background can understand it.
The above mentioned responsibilities of a data scientist just scratch the surface because, a data scientist’s job role cannot be limited by or, defined by a couple of tasks. The data scientist needs to be in synch with the implementation process to understand and analyze further how the data driven insight is shaping strategies and to which effect. Most importantly, they need to evaluate the current data infrastructure of the company and advise regarding future improvement. A data scientist needs to have a keen knowledge of Machine Learning Using Python, to be able to perform the complex tasks their job demands.
With 2.5 quintillion bytes of data being created everyday companies are scrambling to build models and hire experts to extract information hidden in massive unstructured datasets and the data scientists have become the most sought-after professionals in the world. The job portals are full of job postings looking for data scientists whose resume has the perfect combination of skill and experience. In this world which is being driven by the data revolution, achieving your big data career dreams need a little bit of planning and strategizing. So, here is a step-by-step guide for you.
Grabbing a high paying and skilled data job is not going to be easy, industries will only invest money on individuals with the right skillset. Your job responsibility will involve wading through tons of unstructured data to find pattern and meaning, making forecasts regarding marketing trends, customer behavior and deliver the insight in a presentable format to the company on the basis of which they are going to be strategizing.
So, before you even begin make sure that you have the tenacity and enthusiasm required for the job. You would need to undergo Data science using python training, in order to gain the necessary skills and knowledge and since this is an evolving field you should be ready to constantly upskill yourself and stay updated about the latest developments in the field.
Are you ready? If it’s a resounding yes, then, without wasting any more time let’s get straight to the point and explore the steps that will lead you to become a data scientist.
Step 1: Complete education
Before you pursue data science, you must complete your bachelors degree, if you are coming from computer science, applied mathematics, or, economics that could give you a head start. However, you need to undergo Data Science training, post that to acquire the required skillset.
Step 2: Gain knowledge of Mathematics and statistics
You do not need to have a PHD in either, but, since both are at the core of the data science you must have a good grasp on applied mathematics and statistics. Your task would require you to have knowledge regarding linear algebra, probability & statistics. So, your first step would be to update yourself and be familiar with the concepts if you happen to hail from a non-science background so that you can sail through the rest of the journey.
Step 3: Get ready to do programming
Just like mathematics and statistics, having a grip on a programming language preferably Python, is essential. Now, why do you need to learn coding? Well, coding is important as you have to work with large datasets comprising mostly unstructured data and coding will help you to clean, organize, read data and also process it. Now the stress is on Python because it is one of the widely used languages in the data science community and is comparatively easier to pick up.
Step 4: Learn Machine Learning
Machine learning plays a crucial role in data science as it helps finding patterns in data and making predictions. Mastering machine learning techniques would enable you develop algorithms for the models and create an automated system that enables you to make predictions in real-time. Consider undergoing a Machine Learning training gurgaon.
Step 5: Learn Data Munging, Visualization, and Reporting
It has been mentioned before that you would mostly be handling unstructured data, which means in order to process that data you must transform that data into a format that is easy to work with. Data munging helps you achieve that. Data visualization is again a must-have skill for a data scientist as it allows you to visually present your data findings that is easy to understand through graphs, charts, while data reporting lets you prepare and present reports for businesses.
Step 6: Be certified
Now that the field has advanced so much, there is a requirement for professionals who have undergone Data Science course. Doing a certification course would upskill you and arm you with industry knowledge. Reputed institutes like Dexlab Analytics offer cutting edge courses such as Python for data science training. If you just follow this step it would take care of the rest of the worries, the best part of getting your training is that here you will be taught everything from scratch so, no need to fret if you do not know programming language. Your learning would be aided by hands-on training.
Step 7: Practice your skills
You need to test the skills you have acquired and to hone the skills you must explore Kaggle, which lets your access resources you need and this platform also allows you to take part in competitions that further helps you sharpen your abilities. You should also keep on practicing by doing projects in order to put the theories into action.
Step 8: Work on your soft skills
In order to be a professional data scientist you must acquire soft skills as well. So along with working on your communication skills, you must also need to develop problem solving skills while learning how business organizations function to understand what would be required of you when you assume the role of a data scientist.
Step 9: Get an internship
Now that you have the skill and certification you need experience to get hired, build a resume stressing on the skills you have acquired and search the job portals to land an internship. It would not only enhance your resume, but, it also gives you exposures to real projects, the more projects you handle the better and you would also learn from the experts there.
Step 10: Apply for a job
Once you have gathered enough experience start applying for full-time positions as now you have both skill and experience. But, do not stop learning once you land a job, because this field is growing many changes will happen so you have to mold yourself accordingly. Be a part of the community, network with people, keep on exploring GitHub and find out what other skills you require.
So, those were the steps you need to follow to build a rewarding career in data science. The job opportunities are plenty and to grab the right job you must do big data training in gurgaon. These courses are aimed to prepare individuals for the industry, so get ready for an exciting career!
Among all the decisions we make in our lives, choosing the right career path seems to be the most crucial one. Except for a couple of clueless souls, most students know by the time they clear their boards what they aspire to be. A big chunk of them veer towards engineering, MBA, even pursue masters degree in academics and post completion of their studies they settle for relevant jobs. So far that used to be the happily ever after career story, but, in the last couple of years there seems to be a big paradigm shift and it is causing a stir across industries. Professionals having an engineering background, or, masters degree are opting for a mid-career switch and a majority of them are opting for the data science domain by pursuing a Data Science course. So, what’s pushing them towards DS? Let’s investigate.
What’s causing the career switch?
No matter which field someone has chosen for career, achieving stability is a common goal. However, in many fields be it engineering, or, something else the job opportunities are not unlimited yet the number of job seekers is growing every year. So, thereby one can expect to face a stiff competition grabbing a well-paid job.
There have been many layoffs in recent times especially due to the unprecedented situation the world is going through. Even before that there were reports of job cuts and certain sectors not doing well would directly impact the career of thousands. Even if we do not concentrate on the extremes, the growth prospect in most places could be limited and achieving the desired salary or, promotion oftentimes becomes impossible. This leads to not only frustration but uncertainty as well.
The demand for big data
If you haven’t been living as a hermit, then you are aware of the data explosion that impacted nearly every industry. The moment everyone understood the power of big data they started investing in research and in building a system that can handle, store and process data which is a storehouse of information. Now, who is going to process data to extract the information? And here comes the new breed of data experts, namely the data scientists, who have mastered the technology having undergone Data Science training and are able to develop models and parse through data to deliver the insights companies are looking for to make informed decisions. The data trend is pushing the boundaries and as cutting edge technologies like AI, machine learning are percolating every aspect of the industries, the demand for avant-garde courses like natural language processing course in gurgaon, is skyrocketing.
Lack of trained industry ready data science professionals
Although big data has started trending as businesses started gathering data from multiple sources, there are not many professionals available to handle the data. The trend is only gaining momentum and if you just check the top job portals such as Glassdoor, Indeed and go through the ads seeking data scientists you would immediately know how far the field has traveled. With more and more industries turning to big data, the demand for qualified data scientists is shooting up.
Why data science is being chosen as the best option?
In the 21st century data science is a field which has plethora of opportunities for the right people and this is one field which is not only growing now but is also poised to grow in future as well. The data scientist is one of the most highest paid professional in today’s job market. According to the U.S. Bureau of Labor Statistics report by the year 2026 there is a possibility of creation of 11.5 million jobs in this field.
Now take a look at the Indian context, from agriculture to aviation the demand for data scientists would continue to grow as there is a severe shortage of professionals. As per a report the salary of a data scientist could hover around ₹1,052K per annum and remember the field is growing which means there is not going to be a dearth of job opportunities or, lucrative pay packages.
The shift
Considering all of these factors there has been a conscious shift in the mindset of the professionals, who are indeed making a beeline for institutes that offer data science certification. By doing so they hope to-
Access promising career opportunities
Achieve job satisfaction and financial stability
Earn more while enjoying job security
Work across industries and also be recruited by industry biggies
Gain valuable experience to be in demand for the rest of their career
Be a part of a domain that promises innovation and evolution instead of stagnation
Keeping in mind the growing demand for professionals and the dearth of trained personnel, premier institutes like DexLab Analytics have designed courses that are aimed to build industry-ready professionals. The best thing about such courses is that you can hail from any academic background, here you will be taught from scratch so that you can grasp the fundamentals before moving on to sophisticated modules.
Along with providing data science certification training, they also offer cutting edge courses such as, artificial intelligence certification in delhi ncr, Machine Learning training gurgaon. Such courses enable the professionals enhance their skillset to make their mark in a world which is being dominated by big data and AI. The faculty consists of skilled professionals who are armed with industry knowledge and hence are in a better position to shape students as per industry demands and standards.
The mid-career switch is happening and will continue to happen. There must be professionals who have the expertise to drive an organization towards the future by unlocking their data secrets. However, something must be kept in mind if you are considering a switch, you need to be ready to meet challenges, along with knowledge of Python for data science training, you need to have a vision, a hunger and a love for data to be a successful data scientist.
A business organization has to deal with a massive amount of data streaming from myriad sources, and data warehousing refers to the process of collection and storage of that data that needs to be analyzed to glean valuable business insight. Data warehousing plays a crucial role in business intelligence. The concept originated in the 1980s, it basically involves data extraction from disparate sources which later gets processed and post formatting the data stays in the system ready to be utilized for taking important decisions.
Data warehouse basically performs the task of running an analysis on the stored data which could be both structured and unstructured even semi-structured, however, the data that is in the warehouse cannot be modified. Data warehousing basically helps companies gain insight regarding factors influencing business, and they could use the data insight to formulate new strategies, developing products and so on. This highly skilled task demands professionals who have a background in Data science using python training.
What are the different steps in data warehousing?
Data warehousing involves the following steps
Transactional data extraction: In this step, the data is extracted from multiple sources available and loaded into the system.
Data transformation: The transactional data extracted from different sources need to be transformed and it would need relating as well.
Building a dimensional model: A dimensional model comprising fact and dimension tables are built and the data gets loaded.
Getting a front-end reporting tool: The tool could be built or, purchased, a crucial decision that needs much deliberation.
Benefits of data warehousing
An edge over the competition
This is undeniably one benefit every business would be eager to reap from data warehousing. The data that is untapped could be the source of valuable information regarding risk factors, trends, customers and so many other factors that could impact the business. Data warehousing collates the data and arranges them in a contextual manner that is easy for a company to access and utilize to make informed decisions.
Enhanced data quality
Since data pooled from different sources could be structured or, unstructured and in different formats, working with such data inconsistency could be problematic and data warehousing takes care of the issue by transforming the data into a consistent format. The standardized data that easily conforms to the analytics platform can be of immense value.
Historical data analysis
A data warehouse basically stores a big amount of data and that includes historical data as well. Such data are basically old records of the company regarding sales, employee data, or, product-related information. Now the historical data belonging to different time periods need to be analyzed to predict upcoming trends.
Smarter business intelligence
Since businesses now rely on data-driven insight to devise strategies, they need access to data that is consistent, error-free, and high quality. However, data coming from numerous sources could be erroneous and irrelevant. But, data warehousing takes care of this issue by formatting the data to make it consistent and free from any error and could be analyzed to offer valuable insight that could help the management take decisions regarding sales, marketing, finance.
High ROI
Building a data warehouse requires significant investment but in the long term, the revenue that it generates can be significant. In fact, keen business intelligence now plays a crucial role in determining the success of an organization and with data warehousing the organizations can have access to data that is consistent and high quality thus enabling the company to derive actionable intel. When a company implements such insight in making smarter strategies, they do gain in the long run.
Data warehousing plays a significant role in collating and storing valuable data that fuels a company’s business decisions. However, given the specialized nature of the task, one must undergo Data Science training, to learn the nuances. The field of big data has plenty of opportunities for the right candidates.