From Saturday, 6th June 2020, a team of senior consultants at DexLab Analytics has been conducting a national level training for more than 40 participants who are research scholars, MPhil students and professors from colleges like IIT, CSIR, BHU and NIT, among others. This one of a kind, crowd-funded training is being conducted on “Environment Air pollution Data Analysis using OpenAir package of R”.
The training is a result of the lockdown wherein DexLab Analytics is working towards its upskilling initiatives for professionals and subject matter experts across India. The training is being conducted in DexLab Analytics’TraDigital format – real time, online, classroom styled, instructor-led training.
The attendees will be taking up these interactive classes from the safety and comfort of their homes. They will be getting assignments, learning material and recordings virtually.
The one-month-long training will be conducted in R Programming, Data Science and Machine Learning using R Programming from the perspective of Environmental Science. DexLab Analytics is conducting this training module in line with the tenets of ‘Atmanirbhar India’.
DexLab Analytics is a leading data science training institute in India with a vast array of state-of-the-art analytics courses, attracting a large number of students nationwide. It offers high-in-demand professional courses like Big Data, R Programming, Python, Machine Learning, Deep Learning, Data Science, Alteryx, SQL, Business Analytics, Credit Risk modeling, Tableau, Excel etc. to help young minds be data-efficient. It has its headquarters in Gurgaon, NCR.
DexLab Analytics is proud to announce that its CMO, Vivek Debuka, was the Key Speaker at a webinar hosted by the Eastern Institute for Integrated Learning in Management (EIILM), Kolkata on “Changing Trend in Business in the Post COVID-19 World”.
The webinar was held on 30th May, 2020 from 5pm – 6pm. Students of the Eastern Institute for Integrated Learning in Management, the chairman and director of the EIILM Dr R P Banerjee said, were excited and eager to attend the webinar, especially because the topic was an emerging one and relevant to their corporate career goals.
On May 27, EIILM posted a Facebook post that read – “EIILM’s initiative for enriching young minds with post COVID-19 business trends!!!! The Covid era has brought about a lot of uncertainties that have resulted in a new thought process in the ever-changing world of business. To orient our budding managers with the dynamic business trends, EIILM – KOLKATA Family has scheduled a Webinar on 30 May 2020, from 5-6 pm under the title “Changing Trend in Business in the Post Covid 19 World”.
DexLab Analytics is a leading data science training institute in India with a vast array of state-of-the-art analytics courses, attracting a large number of students nationwide. It offers high-in-demand professional courses like Big Data, R Programming, Python, Machine Learning, Deep Learning, Data Science, Alteryx, SQL, Business Analytics, Credit Risk modeling, Tableau, Excel etc. to help young minds be data-efficient. It has its headquarters in Gurgaon, NCR.
The Covid-19 pandemic has struck India like it has scores of countries across the world. As of May 27, over 1,51,000 Indians have been tested positive for the novel virus and over 4000 people have died due to the contagious disease. India has been under lockdown for over two months now in an attempt at abating the spread of the virus due to movement and contact.
With all offices closed and work from home decreed across numerous sectors of the economy, professionals have been forced to adapt to a new mode of work and training. With more time on hand since they are working from home, professionals are upgrading their skills by taking up online training modules and classes. A recent LinkedIn survey throws light on this phenomenon.
LinkedIn’s Work Force Confidence Index
India’s foremost social networking site that helps individuals network with professional peers and find jobs and appointments has conducted a survey called Work Force Confidence Index. As per the survey conducted between April 27 and May 3, “India’s professionals are logging learning hours for not just knowledge acquisition but also to increase productivity. About half of respondents from mid-market firms joined courses that help them manage time better, improve prioritisation or stay organised”.
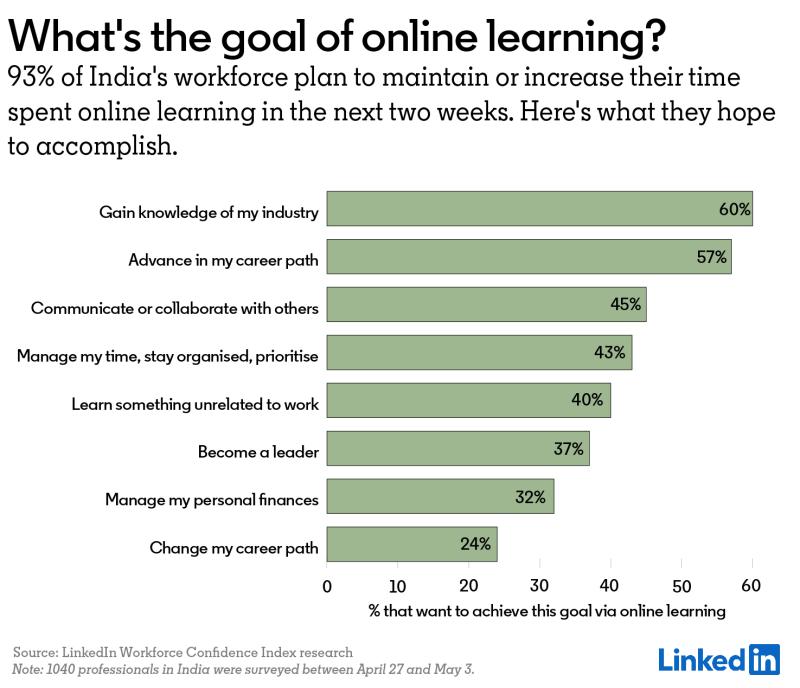
93% respondents to upskill online in next two weeks
According to LinkedIn News India, 1040 professionals were surveyed by LinkedIn and 93% of them said “their time spent on e-learning will either increase or remain the same over the next two weeks”. Moreover, 60% of the respondents of which 74% were from the engineering domain said e-learning was a conduit to furthering industry knowledge. “Advancing in one’s career was a driver for 57% of all respondents and 3 in 10 active job seekers undertook e-learning to make a career pivot,” said LinkedIn News India.
What respondents learnt
Of the respondents, 45% said they hoped to learn to collaborate with peers through online learning in lockdown. Also, 43% said they wished to learn to manage time and prioritise and stay organised. Moreover, 40% said they hoped to learn something unrelated to work through online platforms. Becoming a leader and managing personal finances were pegged at 37% and 32% respectively by the study as goals and 24% said e-learning could actually lead to a change in career paths for them.
Advantages of e-learning
Travelling to work and back is taxing and time consuming. When you are working from home, you save on energy and time that can be used for something productive like e-learning training modules. They are easy on the pocket, accessible from absolutely anywhere you are and convenient to absorb and retain information and new things learnt. Moreover, there is a large online community to help you out with study material and guidance.
Data Science has undergone a tremendous change since the 1990s when the term was first coined. With data as its pivotal element, we need to ask valid questions like why we need data and what we can do with the data in hand.
The Data Scientist is supposed to ask these questions to determine how data can be useful in today’s world of change and flux. The steps taken to determine the outcome of processes applied to data is known as Data Science project lifecycle. These steps are enumerated here.
Business Understanding
Business Understanding is a key player in the success of any data science project. Despite the prevalence of technology in today’s scenario it can safely be said that the “success of any project depends on the quality of questions asked of the dataset.”One has to properly understand the business model he is working under to be able to effectively work on the obtained data.
Data Collection
Data is the raison detre of data science. It is the pivot on which data science functions. Data can be collected from numerous sources – logs from webservers, data from online repositories, data from databases, social media data, data in excel sheet format. Data is everywhere. If the right questions are asked of data in the first step of a project life cycle, then data collection will follow naturally.
Data Preparation
The available Data set might not be in the desired format and suitable enough to perform analysis upon readily. So the data set will have to be cleaned or scrubbed so to say before it can be analyzed. It will have to be structured in a format that can be analyzed scientifically. This process is also known as Data cleaning or data wrangling. As the case might be, data can be obtained from various sources but it will need to be combined so it can be analyzed.
For this, data structuring is required. Also, there might me some elements missing in the data set in which case model building becomes a problem. There are various methods to conduct missing value and duplicate value treatment.
“Exploratory Data Analysis (EDA) plays an important role at this stage as summarization of clean data helps in identifying the structure, outliers, anomalies and patterns in the data.
These insights could help in building the model.”
Data Modelling
This stage is the most, we can say, magical of all. But ensure you have thoroughly gone through the previous processes before you begin building your model. “Feature selection is one of the first things that you would like to do in this stage. Not all features might be essential for making the predictions. What needs to be done here is to reduce the dimensionality of the dataset. It should be done such that features contributing to the prediction results should be selected.”
“Based on the business problem models could be selected. It is essential to identify what is the task, is it a classification problem, regression or prediction problem, time series forecasting or a clustering problem.” Once problem type is sorted out the model can be implemented.
“After the modelling process, model performance measurement is required. For this precision, recall, F1-score for classification problem could be used. For regression problem R2, MAPE (Moving Average Percentage Error) or RMSE (Root Mean Square Error) could be used.”The model should be a robust one and not an overfitted model that will not be accurate.
Interpreting Data
This is the last and most important step of any Data Science project. Execution of this step should be as good and robust as to produce what a layman can understand in terms of the outcome of the project.“The predictive power of the model lies in its ability to generalise.”
This video tutorial is on exploratory data analysis. The data is on COVID-19 cases and it has been taken from Kaggle. This tutorial is based on simple visualization of COVID-19 cases.
For code sheet and data click below.
Firstly, we must call whatever libraries we need in Python. Then we must import the data we will be working on onto our platform.
Now, we must explore PANDAS. For this it is important to know that there are three types of data structures – Series, Data Frame and Panel Data. In our tutorial we will be using data frames.
Fig. 1.
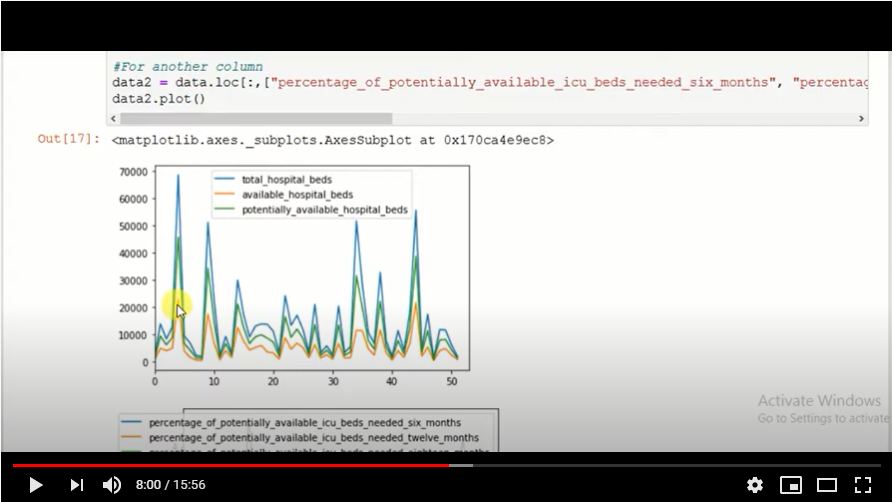
Now we will plot the data we have onto a graph. When we run the program, we get a graph that shows total hospital beds, potentially available hospital beds and available hospital beds.
Fig. 2.
While visualizing data we must remember to keep the data as simple as possible and not make it complex. If there are too many data columns the interpretation will be a very complex one, something we do not want.
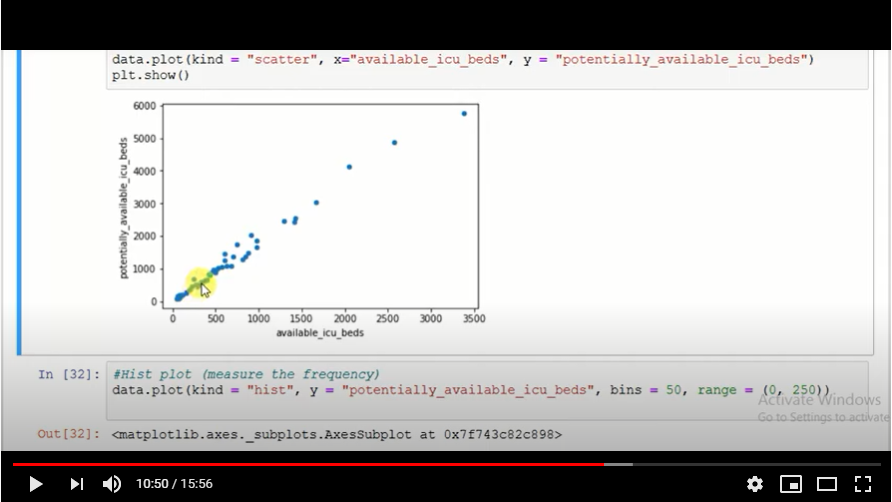
Fig. 3.
A scatter plot (Fig. 3.) is also generated to show the reading of the data available. We study the behaviour of the data on the plot.
Business leaders across platforms are hungrily eyeing data-driven decision making for its ability to transform businesses. But what needs to be taken into account is the opinion of data scientists in the core company teams for they are the experts in the field and whatever they have to say regarding data driven decisions should be the final word in these matters.
“The ideal scenario is all parties in complete alignment. This can be envisioned as a perfect rectangle, with business leaders’ expectations at the top, fully supported by a foundation of data science capabilities — for example, when data science and AI can achieve management’s goal of reducing customer retention costs by automating identification and outreach to at-risk customers,”says a report.
The much sought after rectangle, however, is rarely achieved. “A more workable shape is the rhombus, depicting the push-and-pull of expectations and deliverables.”
Using the power of your company’s data.
Business leaders must have patience with developments on the part of data scientists for what they expect is usually not in sync with the deliverables on the ground.
“Over the last few years, an automaker, for example, dove into data science on leadership’s blind faith that analytics could revolutionize the driver experience. After much trial and error, the results fell far short of adding anything meaningful to what drivers found valuable behind the wheel of a car.”
Appreciate Small Improvements
Also, what must be appreciated are small improvements made impactful. For instance, “slight increases in profitability per customer or conversion rates” are things that should be taken into account despite the fact that they might be modest gains in comparison to what business leaders had invested in analytics. “Applied over a large population of customers, however, those small improvements can yield big results. Moreover, these improvements can lead to gains elsewhere, such as eliminating ineffective business initiatives.”
Healthy Competition
However, it is advisable for business leaders to constantly push their data scientists to strive for more deliverables and improve their tally with a framework of healthy competition in place. In fact, big companies form data science centers of excellence, “while also creating a healthy competitive atmosphere that encourages data scientists to push each other to find the best tools, strategies, and techniques for solving problems and implementing solutions.”
Here are three ways to inspire data scientists
Both sides must work together –Take the example of a data science team with expertise in building models to improve customers’ shopping experiences. “Business leaders might assume that a natural next step is to use AI to enhance all customer service needs.”However, AI and machine learning cannot answer the ‘why’ or ‘how’ of the data insights. Human beings have to delve into those aspects by studying the AI output. And on the other hand, data scientists also must understand why business leaders expect so much from them and how to achieve a middle path with regard to expectations and deliverables.
Gain from past successes and achievements – “There is value in small data projects to build capabilities and understanding and to help foster a data-driven culture.”The best policy for firms to follow is to initially keep modest expectations. After executing and implementing the analytics projects, they should conduct a brutally honest anatomy of the successes and failures, and then build business expectations at the same time as analytics investment.
Let data scientists spell out the delivery of analytics results – “Communication around what is reasonable and deliverable given current capabilities must come from the data scientists — not the frontline marketing person in an agency or the business unit leader.” Before signing any contract or deal with a client, it is advisable to allow the client to have a discussion with the data scientists so that there is no conflict of ideas between what the data science team spells out and what the marketing team has in mind. For this, data scientists will have to work on their soft skills and improve their ability to “speak business” regarding specific projects.