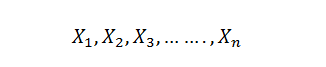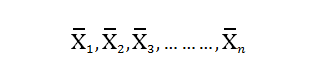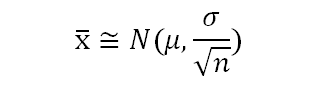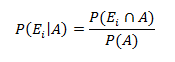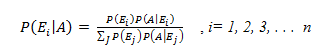In the previous blog on Bayes’ Theorem, we left off at an interesting junction where we just touched upon the ideas on prior odds ratio, likelihood ratio and the resulting Posterior Odds Ratio. However, we didn’t go into much detail of what it means in real life scenarios and how should we use them.
In this blog, we will introduce the powerful concept of “Bayesian Thinking” and explain why it is so important. Bayesian Thinking is a practical application of the Bayes’ Theorem which can be used as a powerful decision-making tool too!
We’ll consider an example to understand how Bayesian Thinking is used to make sound decisions.
For the sake of simplicity, let’s imagine a management consultation firm hires only two types of employees. Let’s say, IT professionals and business consultants. You come across an employee of this firm, let’s call him Raj. You notice something about Raj instantly. Raj is shy. Now if you were asked to guess which type of employee Raj is what would be your guess?

If your guess is that Raj is an IT guy based on shyness as an attribute, then you have already fallen for one of the inherent cognitive biases. We’ll talk more about it later. But what if it can be proved Raj is actually twice as likely to be a Business Consultant?!
This is where Bayesian Thinking allows us to keep account of priors and likelihood information to predict a posterior probability.
The inherent cognitive bias you fell for is actually called – Base Rate Neglect. Base Rate Neglect occurs when we do not take into account the underlying proportion of a group in the population. Put it simply, what is the proportion of IT professionals to Business consultants in a business management firm? It would be fair to assume for every 1 IT professional, the firm hires 10 business consultants.
Another assumption could be made about shyness as an attribute. It would be fair to assume shyness is more common in IT professionals as compared to business consultants. Let’s assume, 75% of IT professionals are in fact shy corresponding to about 15% of business consultants.
Think of the proportion of employees in the firm as the prior odds. Now, think of the shyness as an attribute as the Likelihood. The figure below demonstrates when we take a product of the two, we get posterior odds.
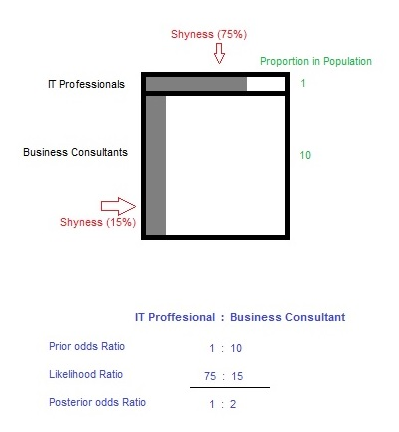
Plugging in the values shows us that Raj is actually twice as likely to be a Business consultant. This proves to us that by applying Bayesian Thinking we can eliminate bias and make a sound judgment.
Now, it would be unrealistic for you to try drawing a diagram or quantifying assumptions in most of the cases. So, how do we learn to apply Bayesian Thinking without quantifying our assumptions? Turns out we could, if we understood what are the underlying principles of Bayesian Thinking are.
Principles of Bayesian Thinking
Rule 1 – Remember your priors!
As we saw earlier how easy it is to fall for the base rate neglect trap. The underlying proportion in the population is often times neglected and we as human beings have a tendency to just focus on just the attribute. Think of priors as the underlying or the background knowledge which is essentially an additional bit of information in addition to the likelihood. A product of the priors together with likelihood determines the posterior odds/probability.
Rule 2 – Question your existing belief
This is somewhat tricky and counter-intuitive to grasp but question your priors. Present yourself with a hypothesis what if your priors were irrelevant or even wrong? How will that affect your posterior probability? Would the new posterior probability be any different than the existing one if your priors are irrelevant or even wrong?
Rule 3 – Update incrementally
We live in a dynamic world where evidence and attributes are constantly shifting. While it is okay to believe in well-tested priors and likelihoods in the present moment. However, always question does my priors & likelihood still hold true today? In other words, update your beliefs incrementally as new information or evidence surfaces. A good example of this would be the shifting sentiments of the financial markets. What holds true today, may not tomorrow? Hence, the priors and likelihoods must also be incrementally updated.
Conclusion
In conclusion, Bayesian Thinking is a powerful tool to hone your judgment skills. Developing Bayesian Thinking essentially tells us what to believe in and how much confident you are about that belief. It also allows us to shift our existing beliefs in light of new information or as the evidence unfolds. Hopefully, you now have a better understanding of Bayesian Thinking and why is it so important.
On that note, we would like to say DexLab Analytics is a premium data analytics training institute located in the heart of Delhi NCR. We provide intensive training on a plethora of data-centric subjects, including data science, Python and credit risk analytics. Stay tuned for more such interesting blogs and updates!
About the Author: Nish Lau Bakshi is a professional data scientist with an actuarial background and a passion to use the power of statistics to tackle various pressing, daily life problems.
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.