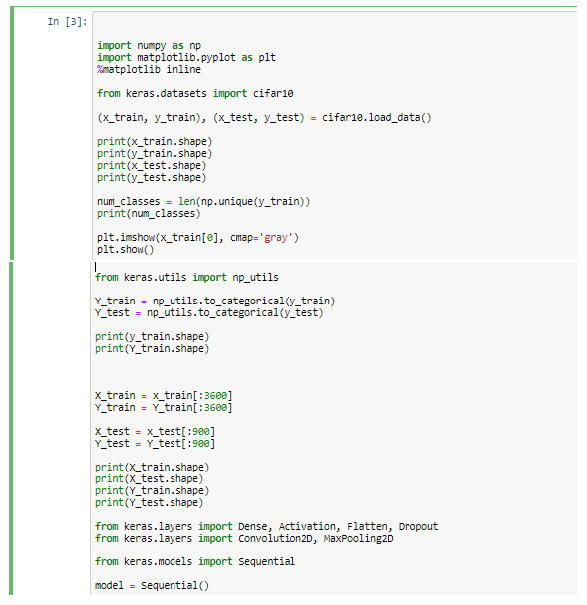
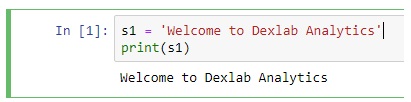
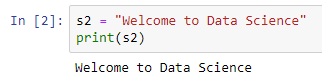
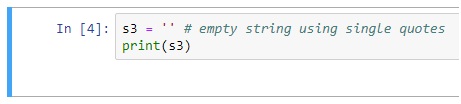
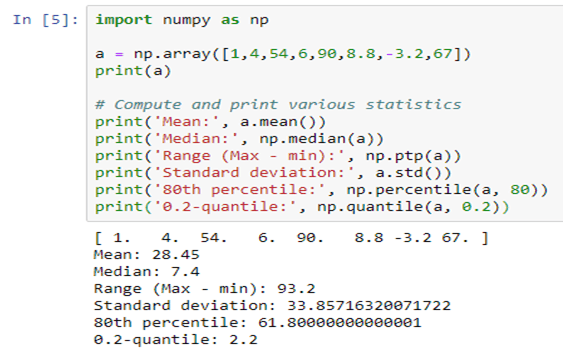
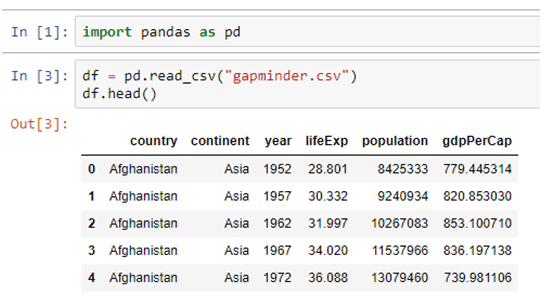
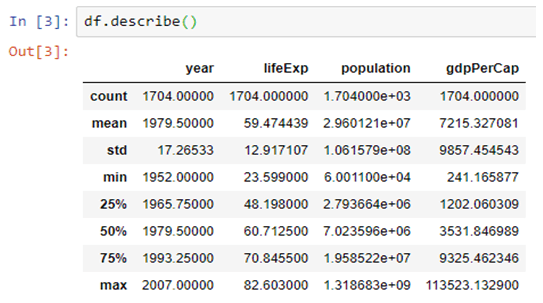
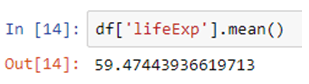
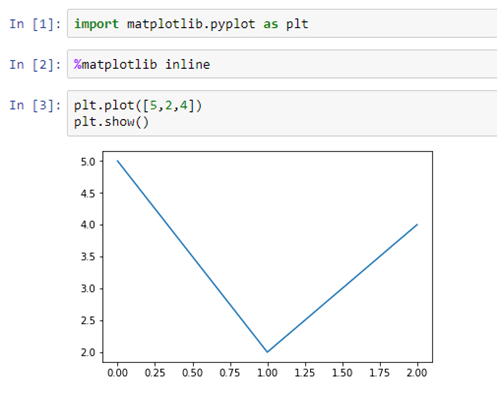
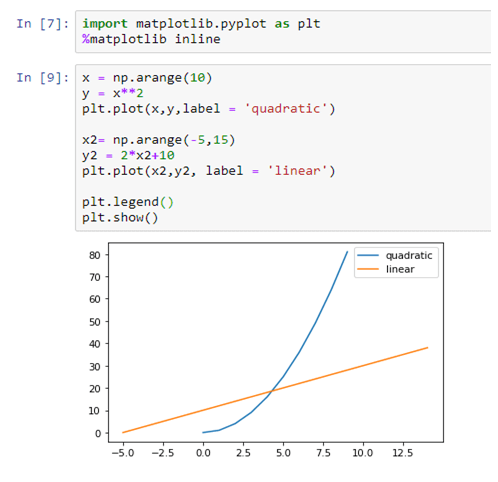
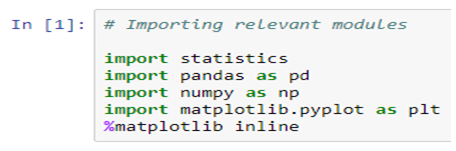
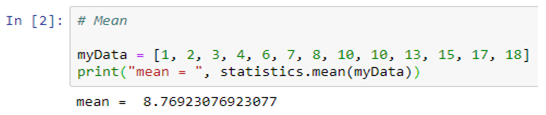
Artificial Intelligence, or, its more popular acronym AI is no longer a term to be read about in a sci-fi book, it is a reality that is reshaping the world by introducing us to virtual assistants, helping us be more secure by enabling us with futuristic measures. The evolution of AI has been pretty consistent and as we are busy navigating through a pandemic-ridden path towards the future, adapting to the “new normal”, and becoming increasingly reliant on technology, AI assumes a greater significance.
The AI applications which are already being implemented has resulted in a big shift, causing an apprehension that the adoption of AI technology on a larger scale would eventually lead to job cuts, whereas in reality, it would lead to the creation of new jobs across industries. Adoption of AI technology would push the demand for a workforce that is highly skilled, enrolling in an artificial intelligence course in delhi could be a timely decision.
Now that we are about to reach the end of 2020, let us take a look at the possible impacts of AI in the future.
AI will create more jobs
Yes, contrary to the popular apprehension AI would end up creating jobs in the future. However, the adoption of AI to automate tasks means yes, there would be a shift, and a job that does not need special skills will be handled by AI powered tools. Jobs that could be done without error, completed faster, with a higher level of efficiency, in short better than humans could be performed by robots. However, with that being said there would be more specialized job roles, remember AI technology is about the simulation of human intelligence, it is not the intelligence, so there would be humans in charge of carrying out the AI operated areas to monitor the work. Not just that but for developing smarter AI application and implementation there should be a skilled workforce ready, a report by World Economic Forum is indicative of that. From design to maintenance, AI specialists would be in high demand especially the developers. The fourth industrial revolution is here, industries are gearing up to build AI infrastructure, it is time to smell the coffee as by the end of 2022 there will be millions of AI jobs waiting for the right candidates.
Dangerous jobs will be handled by robots
In the future, hazardous works will be handled by robots. Now the robots are already being employed to handle heavy lifting tasks, along with handling the mundane ones that require only repetition and manual labor. Along with automating these tasks, the robot workforce can also handle the situation where human workers might sustain grave injuries. If you have been aware and interested then you already heard about the “SmokeBot”. In the future, it might be the robots who will enter the flaming buildings for assessment before their human counterparts can start their task. Manufacturing plants that deal with toxic elements need robot workers, as humans run a bigger risk when they are exposed to such chemicals. Furthermore, the nuclear plants might have a robot crew that could efficiently handle such tasks. Other areas like pipeline exploration, bomb defusing, conducting rescue operations in hostile terrain should be handled by AI robots.
Smarter healthcare facilities
AI implementation which has already begun would continue to transform the healthcare services. With AI being in place CT scan and MRI images could be more precise pointing out even minuscule changes that earlier went undetected. Drug development could also be another area that would see vast improvement and in a post-pandemic world, people would need to be better prepared to fight against such viruses. Real-time detection could prevent many health issues going severe and keeping a track of the health records preventive measures could be taken. One of the most crucial changes that could be revolutionary, is the personalized medication which could only be driven by AI technology. This would completely change the way healthcare functions. Now that we are seeing chat bots for handling sales queries, the future healthcare landscape might be ruled by virtual assistants specifically developed for offering assistance to the patients. There are going to be revolutionary changes in this field in the future, thereby pushing the demand for professionals skilled in deep learning for computer vision with python.
Smarter finance
We are already living in an age where we have robo advisors, this is just the beginning and the growing AI implementation would enable an even smarter analytics system that would minimize the credit risk and would allow banks and other financial institutes to minimize the risk of fraud. Smarter asset management, enhanced customer support are going to be the core features. Smarter ML algorithms would detect any and every oddity in behavior or in transactions and would help prevent any kind of fraud from happening. With analytics being in place it would be easier to predict the future trends and thereby being more efficient in servicing the customers. The introduction of personalized services is going to be another key feature to look out for.

Retail space gets a boost
The retailers are now aiming to implement AI applications to offer smart shopping solutions to the future buyers. Along with coming up with personalized shopping suggestions for the customers and showing them suggestions based on their shopping pattern, the retailers would also be using the AI to predict the future trends and work accordingly. Not just that but they can easily maintain the supply and demand balance with the help of AI solutions and stock up items that are going to be in demand instead of items that would not be trendy. The smarter assistants would ensure that the customer queries are being handled and they could also be helping them with shopping by providing suggestions and information. From smart marketing to smarter delivery, the future of retail would be dominated by AI as the investment in this space is gradually going up.
The future is definitely going to be impacted by the AI technology in more ways than one. So, be future ready and get yourself upskilled as it is the need of the hour, stay updated and develop the skill to move towards the AI future with confidence.
.