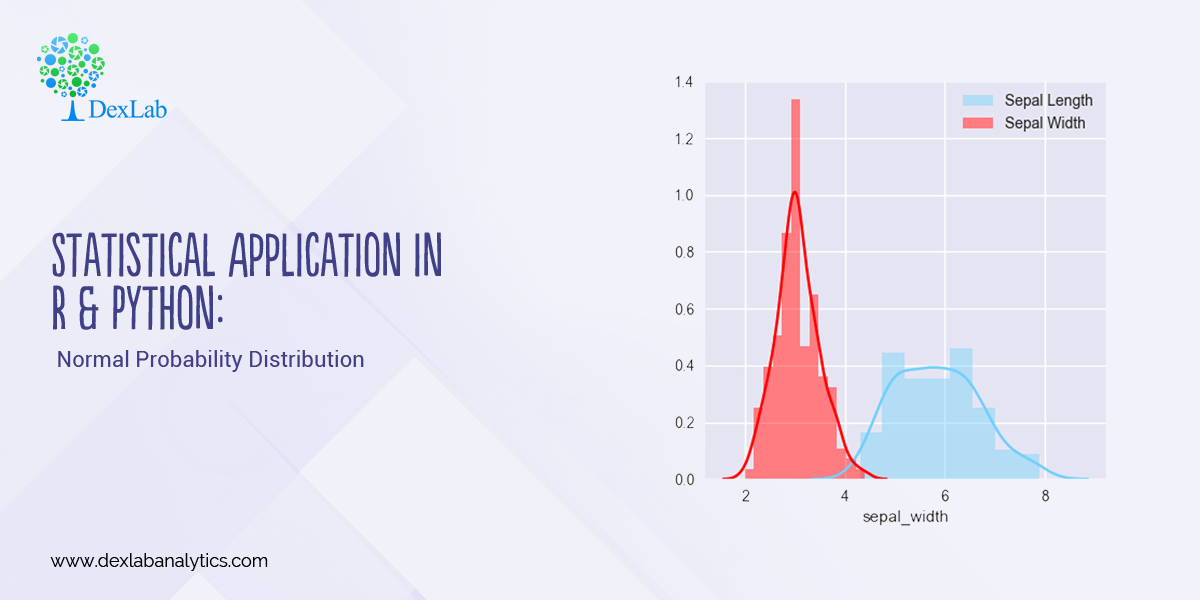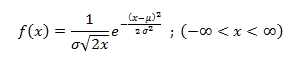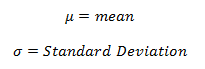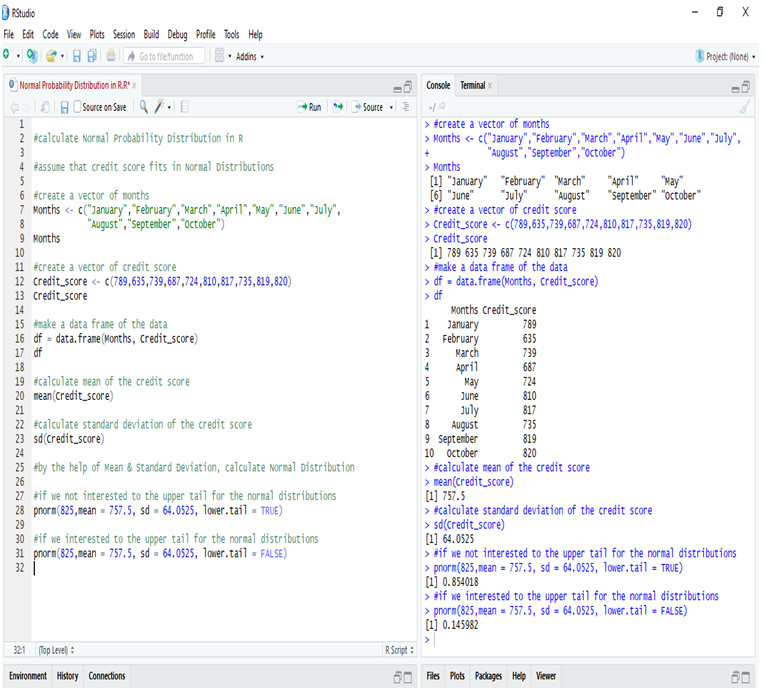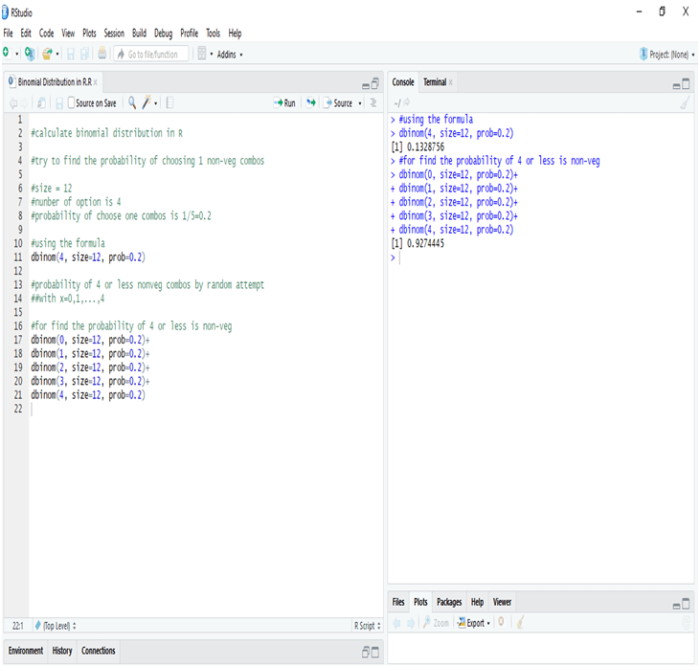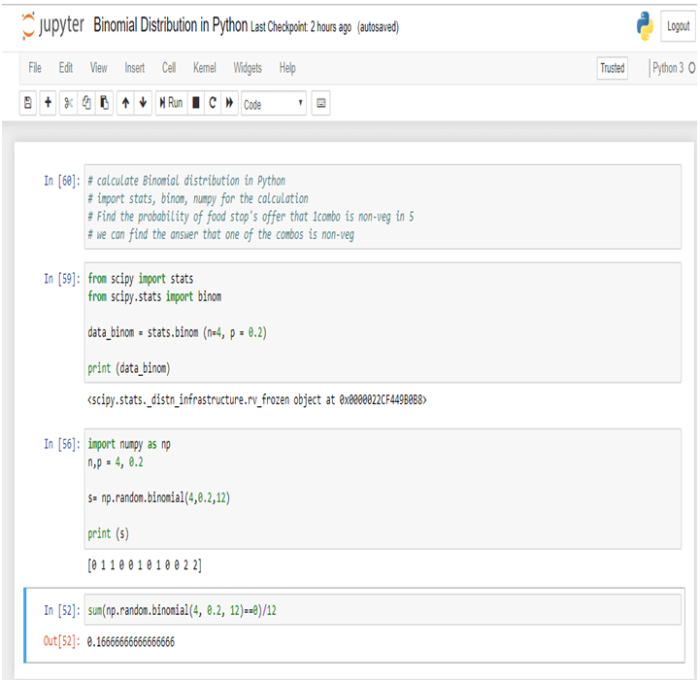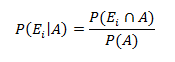
In this blog, we will bring forth the age old question and check which one is better, R programming and Python programming, when it comes to data science?
To be very honest, this question does not have a strict answer to it. However, in this blog we will lay down the key components of both the languages to give you a clearer picture. In the end, please decide for yourself and leave your comments in the section below.
The aim of this blog is to objectively put forward the pros and cons of both languages strictly from the perspective of data science.
We will discuss only about three main components, which are as follows:
- Syntax
- Performance
- Applicability
There are other metrics, such as, trends in Industries and adaptation in the recent years which are beyond the scope of this blog. However, you can safely declare Python as the clear winner if those perspectives were concerned.
So let’s get started:
Syntax
Both R and Python are object-oriented languages. This is to say that everything is created as an object in which the information is mapped with the idea of using that object later in the analysis. However, when it comes to the syntax, i.e., the grammar of programming, R and Python are indeed very different.
R Programming
R programing is more suited to more seasoned coders who have prior experience of coding. The syntax is actually very similar to that of the previous languages, such as C, or C++ or Java and so on. The fundamental rules are that of C programming language. Also, use of semicolons is deemed optional in R. However, semicolons are necessary for multiple lines in a code inside a code block.

Python
Python on the other hand, is the language more adaptable to the new generation of programmers. You can come from a non-programming background and still learn Python with relative ease.
Python is one of the most user friendly languages for the beginners. The syntax is designed to prioritize readability over preciseness of the code. In layman’s terms – coding in Python is very close to reading and writing with hand. In this regard, it is really popular amongst beginners in Data Science.
Performance
The performance is essentially measured by speed essentially when it comes to programming.
R Programming
As far as the general consensus goes R programming is much slower in terms of speed. The reason behind this is that R programming was initially designed to be used by statisticians for data analysis. Thus, R programming stresses more on precision than the speed.
Python
Python on the other hand, is relatively faster than R. Python offers the same level of precision whilst acting on a faster speed.
Note – The speed is taken into account independent of packages and libraries.
Applicability
Lastly, we will discuss the popular domains in which these languages are used.

R Programming
As mentioned above, R was developed specifically for statisticians. For this reason, R is mainly used in various research organizations and academia in general. However, R is now quickly being absorbed in the enterprises as well, mainly because of its popularity and the availability of a large number of packages for statistical computation.
Python
Python is a gene
As Python is a general-purpose programming language we can use to build different kinds of applications. We can use Python to build web applications using popular frameworks like Django or Flask.
Lately, Python is becoming popular amongst data scientists as the language of choice given the simplicity of syntax, high speed and performance it has to offer. There has been a trend which has seen a sharp rise in the adaptability of Python over R in the last few years in Data Science.
So, there you have it folks. Decide for yourself now! We will meet you soon in the next blog.
Dexlab Analytics is a pioneering institute of Data Science and Big Data Analytics with all-inclusive Big data courses in Delhi along with numerous other efficacious courses like Hadoop certification in Delhi, R programming courses in Gurgaon and Python for Data Analysis under experienced trainers and professionals.
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.