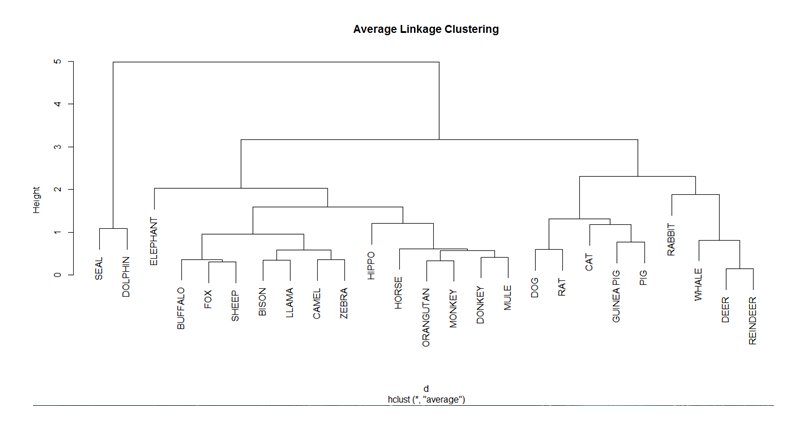
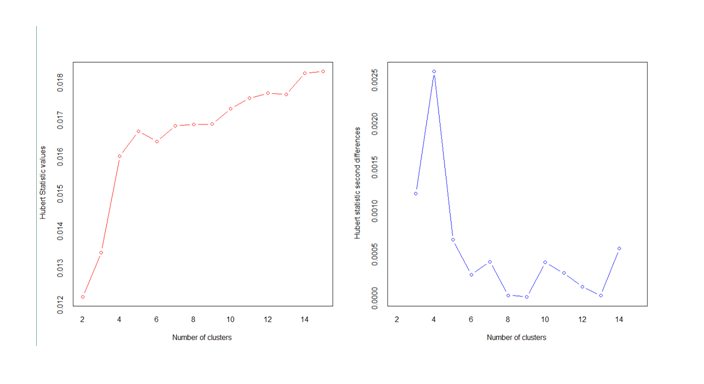
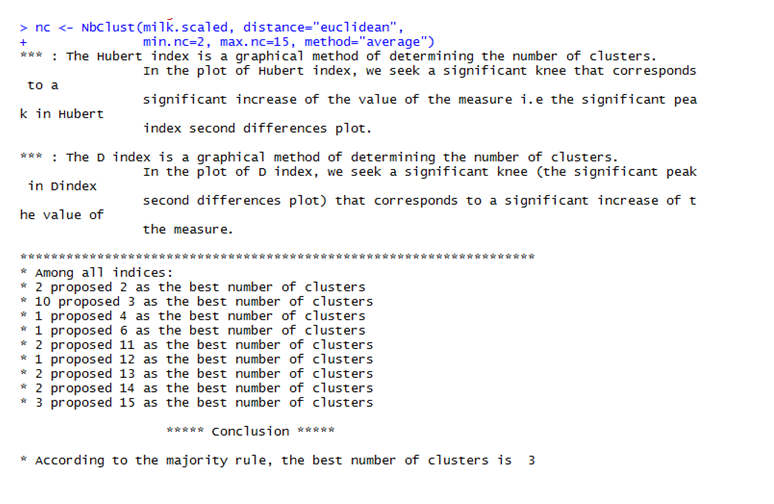
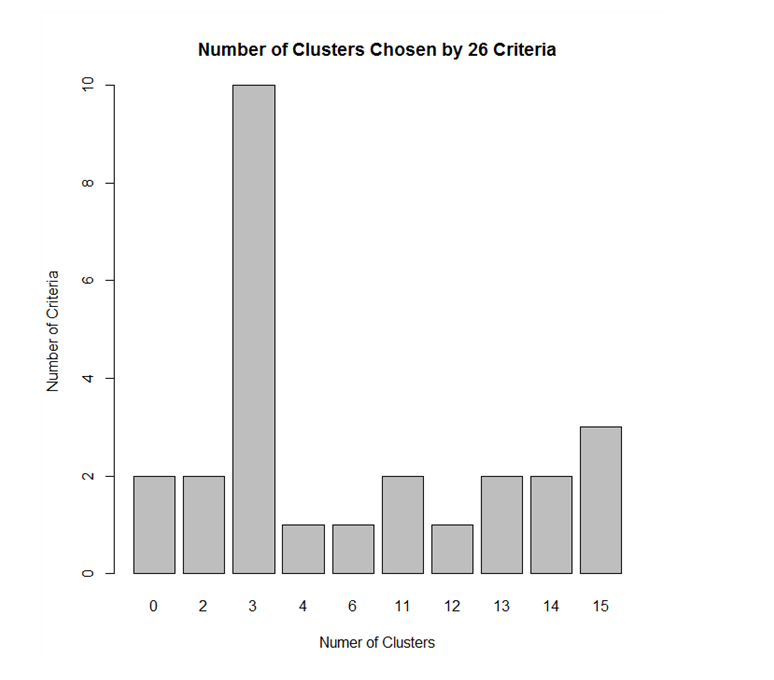
Prediction says – the demand for AI and Big Data Analytics jobs is expected to hit 5.11 lakh, but professionals possessing the desired skills will number only 3.7 lakh by the end of 2018 – according to the National Association of Software and Services Companies (Nasscom).
Further, the demand is expected to spike up to 7.86 lakh by the end of 2021.

No wonder, the Indian IT industry is exploding with lucrative opportunities – 2018 began witnessing a steep rise in demand for skilled consultants specialized in the quarters of emerging technologies, like machine learning and artificial intelligence as well as big data and analytics. And, with a steady focus on Digital India, the IT recruitment industry is on its wheels to add 50% more workforce, resulting in another 1.80 to 2.0 lakh job creation by the end of this year.
Artificial Intelligence alone has the ability to generate 2.3 million jobs globally by 2020, says Alka Dhingra, GM, IT Staffing, TeamLease Services, a leading recruitment company.

Revival of Indian IT sector
Since the technology is taking charge and rapidly transforming the every facet of business, the World Economic Forum has predicted a net loss of 5 million jobs in a couple of years. However, this leaves little room for worry, because job seekers and skilled professionals possessing the desired skills will be in a comfortable position to capitalize this trend and strive for better.
In this context, “Priority focus for us would be re-skilling the workforce in AI and big data,” says Debjani Ghosh, President, Nasscom, further adding, “Of the 4 million jobs in the industry, the nature of 60-65% is likely to change over the next five years.”
Quite interestingly, 1 out of 5 companies are found using AI to boost decision-making capacity. It help companies provide curated customized solutions and instructions to techies in real-time. Back in the day, traditional text analytics platforms were extremely complex; a handful number of companies were lucky enough to successfully analyze text data. But now, with Deep learning in AI, analysis of structured and unstructured text data has become a piece of cake – as a result of which, “We expect a 60 per cent increase in demand for AI and machine learning specialists in 2018,” shares BN Thammaiah, Managing Director, Kelly Services India.
Just like their job responsibility, the pay package of an AI professional breathes of adequacy – a techie with 2-4 years of experience earns 15-20 lakh INR annually, whereas 4-8 years of experience leads to 20-50 lakh INR annually.
Interested in Hadoop training in Gurgaon? Visit the experts at DexLab Analytics.

New Streams to Consider
Retail, healthcare, telecom and manufacturing – these sectors are going to first witness the big data impact, followed by automobiles and FinTech. The next 5 years is going to be pivotal. Companies would be struggling hard to find and appoint AI engineers, especially for positions relating BI and Cloud for industrial automation. BlockChain is another new-age digital discipline that has started shifting focus and drawing attention across the e-com industry. It is found penetrating the sector, and for good reasons.
Now, if you are a data-enthusiast and seeking ways to reap benefits out of such a magnanimous tech-revolution? We got your back. DexLab Analytics offers state of the art Big Data training in Gurgaon at the best prices. Learn more.
The blog has been sourced from —
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.