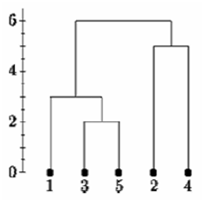
Ease and portability are of prime importance to businesses. Companies want to handle data in real-time; so there’s need for quick and smooth access to data. Accessibility is often the deciding factor that determines if a business will be ahead or behind in competition.
Data portability is a concept that is aimed at protecting users by making data available in a structured, machine-readable and interoperable format. It enables users to move their data from one controller to another. Organizations are required to follow common technical standards to assist transfer of data instead of storing data in ‘’walled gardens’’ that renders the data incompatible with other platforms.
Now, let’s look a little closer into why portability is so important.
Advantages:
Making data portable gives consumers the power to access data across multiple channels and platforms. It improves data transparency as individuals can look up and analyze relevant data from different companies. It will also help people to exercise their data rights and find out what information organizations are holding. Individuals will be able to make better queries.
From keeping a track of travel distance to monitoring energy consumption on the move, portable data is able to connect with various activities and is excellent for performing analytical examinations on. Portable data may be used by businesses to map consumers better and help them make better decisions, all the while collecting data very transparently. Thus, it improves data personalization.
For example, the portable data relating to a consumers grocery purchases in the past can be utilized by a grocery store to provide useful sales offers and recipes. Portable data can help doctors find quick information about a patient’s medical history- blood group, diet, regular activities and habits, etc., which will benefit the treatment. Hence, data portability can enhance our lifestyle in many ways.
Struggles:
Portable data presents a plethora of benefits for users in terms of data transparency and consumer satisfaction. However, it does have its own set of limitations too. The downside of greater transparency is security issues. It permits third parties to regularly access password protected sites and request login details from users. Scary as it may sound; people who use the same password for multiple sites are easy targets for hackers and identity thieves. They can easily access the entire digital activity of such users.
Although GDPR stipulates that data should be in a common format, that alone doesn’t secure standardization across all platforms. For example, one business may name a domain ‘’Location” while another business might call the same field ‘’Locale”. In such cases, if the data needs to be aligned with other data sources, it has to be done manually.
According to GDPR rules, if an organization receives a request pertaining to data portability, then it has to respond within one month. While they might be willing to readily give out data to general consumers, they might hold off the same information if they perceive the request as competition.

Future:
Data portability runs the risk of placing unequal power in the hands of big companies who have the money power to automate data requests, set up an entire department to cater to portability requests and pay GDPR fines if needed.
Despite these issues, there are many positives. It can help track a patient’s medical statistics and provide valuable insights about the treatment; and encourage people to donate data for good causes, like research.
As businesses as well as consumers weigh the pros and cons of data portability, one thing is clear- it will be an important topic of discussion in the years to come.
Businesses consider data to be their most important asset. As the accumulation, access and analysis of data is gaining importance, the prospects for data professionals are also increasing. You must seize these lucrative career opportunities by enrolling for Big Data Hadoop certification courses in Gurgaon. We at Dexlab Analytics bring together years of industry experience, hands-on training and a comprehensive course structure to help you become industry-ready.

Don’t miss the summer special course discounts on big data Hadoop training in Delhi. We are offering flat 10% discount to all interested students. Hurry!
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.