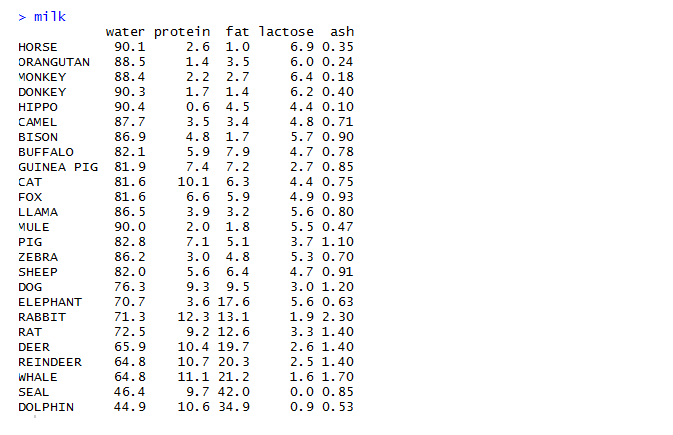
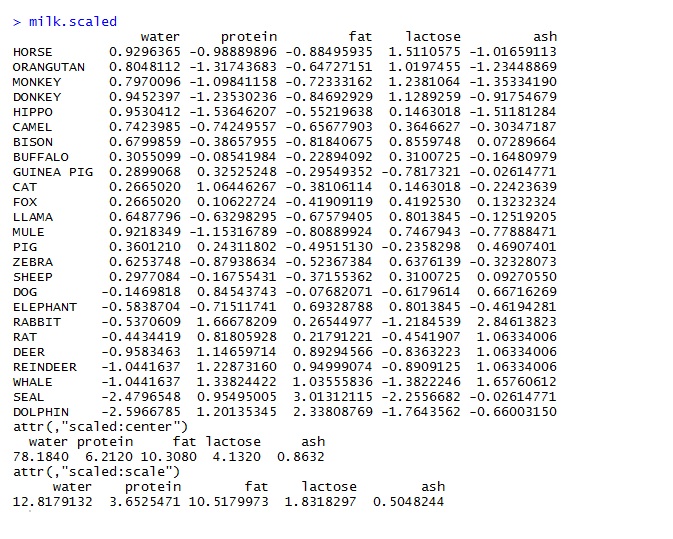
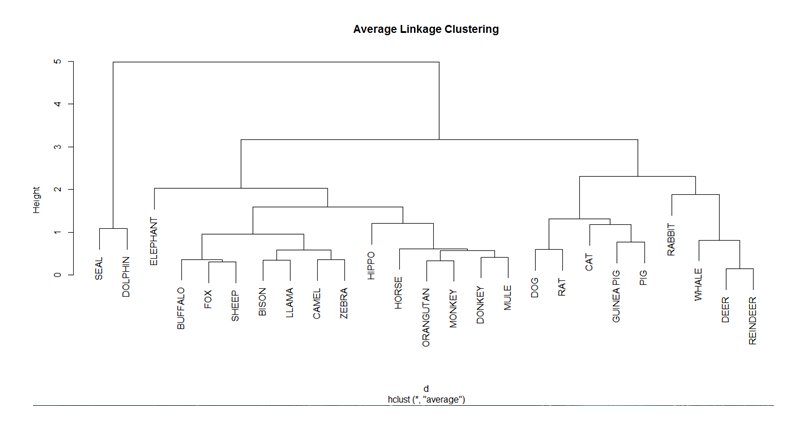
The hot topic in today’s business world is Big Data. The ability to access and analyze the massive amount of data generated every second is crucial for the growth of a business. In this blog, we highlight the rapid growth in data and its significance in business decisions through some incredible statistics.

The amount of information man created from the dawn of civilization until 2003 is currently created every two days!
And the instant messages, tweets and pictures you exchange every second contributes to this data. Ex CEO of Google, Eric Schmidt wonders if the world is ready for the big data-driven technological revolution that is imminent.

5 quintillion bytes of data are generated by internet users on a daily basis.
If the data generated in a day was burned onto DVDs, the number would be so massive that it could be piled on top of each other to reach the moon twice!

Out of all the data we create, only about 0.5% is analyzed and put to use.

There’s a huge amount of data that remains untapped. For all the Silicon Valley big shots, like Google, LinkedIn and Facebook, the aim is to link big data with personal data and create products that are highly personalized.

40,000 search queries are processed by Google every second and these add up to 3.5 billion searches each day and 1.2 trillion searches every year globally.

Google was founded in 1998 and back then it was catering to only ten thousand search queries every day. However, you shall be astonished after knowing that since 2006 more than ten thousand search queries have been performed through Google per second!
Big data has the potential to create 6 million jobs in the U.S.
LinkedIn’s head of data recruiting, Sherry Shah, described the big data job market as being ‘’very hot right now’’.

A 10% increase in the data accessibility for Fortune 1000 companies is likely to increase their income by $65 million!
And this is exactly why companies care so much about big data.

The job market for big data and analytics looks promising. Especially if you are fresher skilled in big data Hadoop then there’s a lot of scope for you. Compared to the current demand for professionals with Hadoop training, the number of available candidates is low. So, what are you waiting for? Enroll for Hadoop training in Gurgaon and grab amazing discounts on big data certifications.
This article has been sourced from:
ediscovery.co/ediscoverydaily/electronic-discovery/date-fun-facts-big-data-ediscovery-trends
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.