Application of Big Data through network clusters has become the order of the day. Multiple industries are embracing this new trend. The elaborate use of Hadoop and MapReduce justifies the popularity of this evolving phenomenon. What’s more, the rise of Apache Spark, an incredible data processing engine written in Scala programming language also lends proof.
Introducing Scala
Somewhat similar to Java programming, Scala is a generic object-oriented programming language. Also known as Scalable Language, Scala is a multi-purpose language with capabilities to grow along the lines of many requirements. The capabilities range from an ordinary scripting language to a mission-critical language for complex applications. A wide number of technologies are being built on this robust platform.

Why Scala?
- It supports functional programming equipped with features, such as immutability, pattern matching, type interference, lazy evaluation and currying.
- It includes an advanced type system – with algebraic data types.
- It helps you explore features that are not available in Java, including raw strings, operator overloading and named parameters.
Besides, Scala runs on Java Virtual Machine (JVM) and endorses cluster computing on Spark.
Introducing Apache Spark
An open source big data processing framework, Apache Spark offers a sound interface for fast processing of huge datasets. It aids in programming data clusters using fault tolerance and data parallelism.
Since 2009, more than 200 companies and 1000 developers have been leveraging Apache Spark and the numbers are still on the rise.
Features of Spark
Comprehensive Framework
Apache Spark is a unified framework ideal for managing big data processing. It also aids a diverse range of datasets, such as batch data, text data, graphical data and real-time streaming data.
Easy to Use
Spark lets programmers write Scala, Java or Python applications – thanks to its built-in set of more than 80 A-grade operators.
Fast and Effective
Talking of speed, Spark runs programs up to 100 X faster than Hadoop clusters in memory and 10 X quicker while running on disk. Powered by a cutting-edge DAG (Directed Acrylic Graph) execution engine, Spark enhances cyclic data flow and in-memory data sharing across DAGs for smoother execution of different jobs but with similar data.
Robust Support
Along with managing MapReduce operations, Spark offers support for streaming data, graphic data processing, SQL queries and machine learning.
Flexibility
Besides Scala programming language, programmers can leverage Python, R, Java and Clojure for developing ace applications using Spark.
Platform-independent
Spark applications are run either in the cloud or on a distinctive cluster mode. Spark can be employed as an individual server or as a part of the distributed framework, like YARN or MESOS. It gives access to versatile data structures, such as HBase, HDFS, Hive, Cassandra and similar Hadoop data sources.
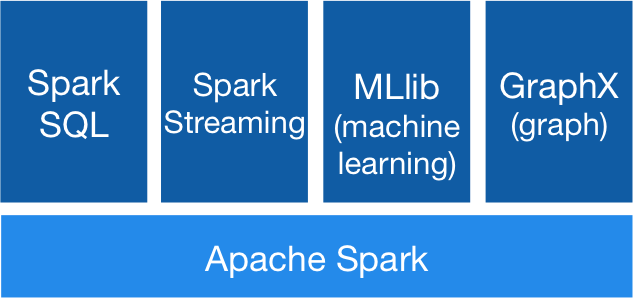
Encompassing Library Support
Are you a Spark programmer? Fuse together additional libraries within the same application and enhance big data and analytics capabilities.
Some of the supported libraries are as follows:
- Spark SQL
- Spark GraphX
- BlinkDB
- Spark MLib
- Tachyon
- Spark R
- Spark Cassandra Connector
As parting thoughts, Apache Spark is the perfect alternative to MapReduce – for installations. The former effortlessly tackles humongous volumes of data that need low latency processing.
DexLab Analytics is a refined Apache Spark training institute in Gurgaon. The comprehensive courses, on-point faculty and flexible batch timings make this institute the best pick for Apache Spark training Gurgaon. For more information, reach us at dexlabanalytics.com.
The blog has been sourced from — www.knowledgehut.com/blog/big-data/analysis-of-big-data-using-spark-and-scala
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.