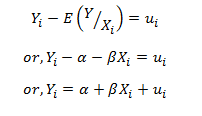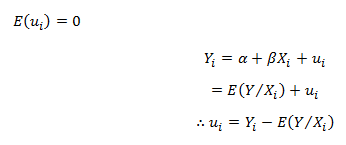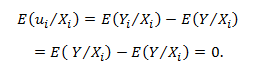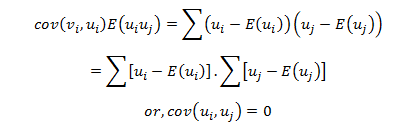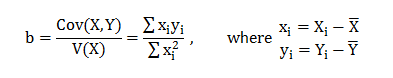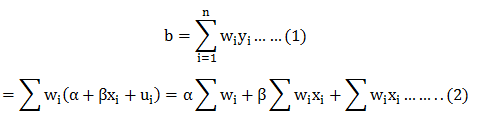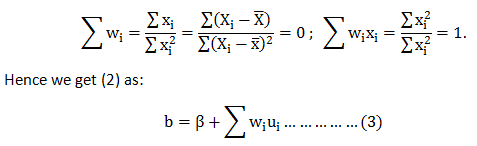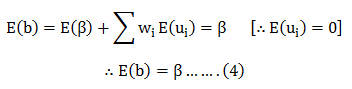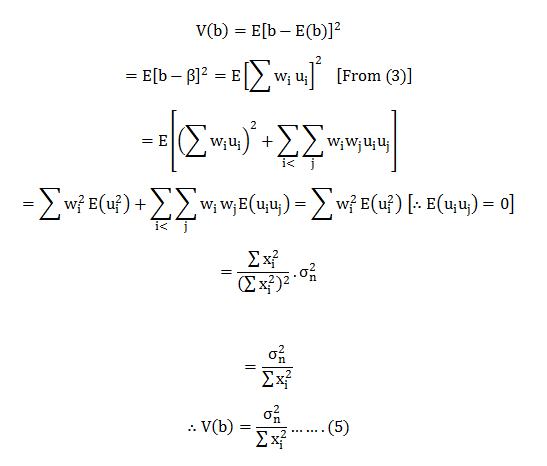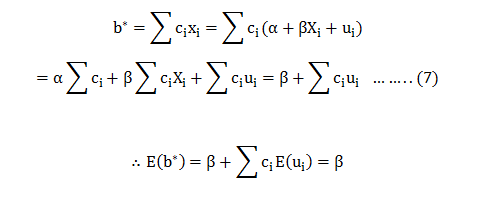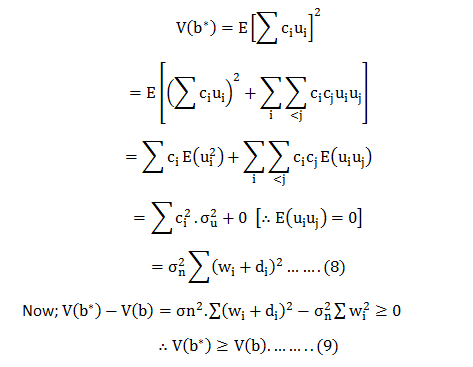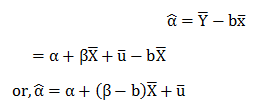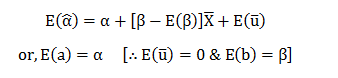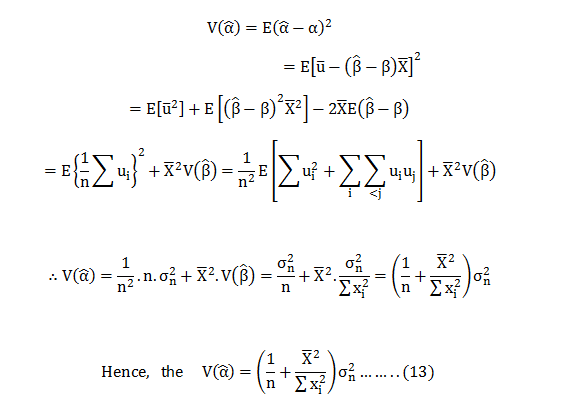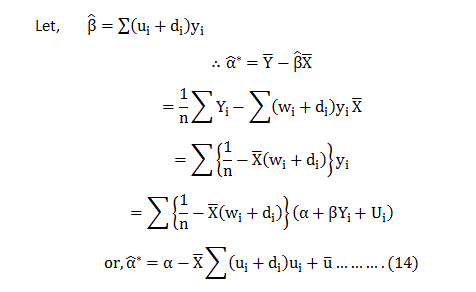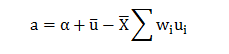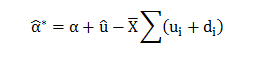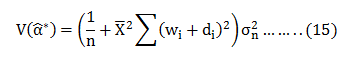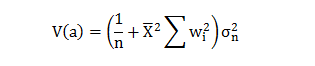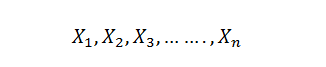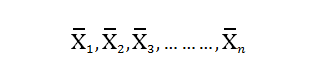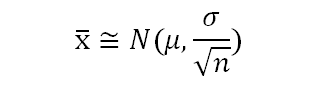
In this blog, we will explore the Exponential distribution. We will begin by questioning the “why” behind the exponential distribution instead of just looking at its PDF formula to calculate probabilities. If we can understand the “why” behind every distribution, we will have a head start in figuring out its practical uses in our everyday business situations.
Much could be said about the Exponential distribution. It is an important distribution used quite frequently in data science and analytics. Besides, it is also a continuous distribution with one parameter “λ” (Lambda). Lambda as a parameter in the case of the exponential distribution represents the “rate of something”. Essentially, the exponential distribution is used to model the decay rate of something or “waiting times”.

For instance, you might be interested in predicting answers to the below-mentioned situations:
- The amount of time until the customer finishes browsing and actually purchases something in your store (success).
- The amount of time until the hardware on AWS EC2 fails (failure).
- The amount of time you need to wait until the bus arrives (arrival).
In all of the above cases if we can estimate a robust value for the parameter lambda, then we can make the predictions using the probability density function for the distribution given below:
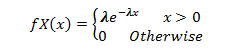
Application:-
Assume that a telemarketer spends on “average” roughly 5 minutes on a call. Imagine they are on a call right now. You are asked to find out the probability that this particular call will last for 3 minutes or less.
![]()
Below we have illustrated how to calculate this probability using Python and R.
Calculate Exponential Distribution in R:
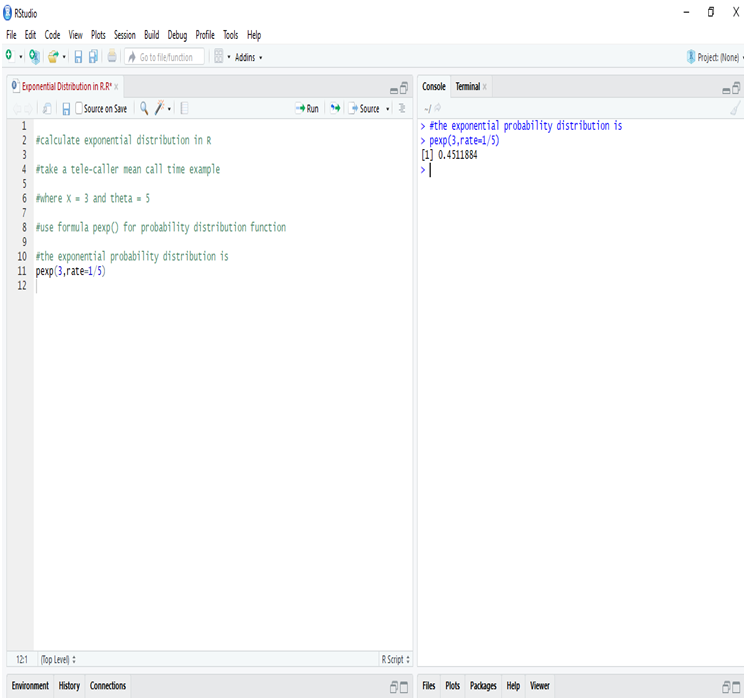
In R we calculate exponential distribution and get the probability of mean call time of the tele-caller will be less than 3 minutes instead of 5 minutes for one call is 45.11%.This is to say that there is a fairly good chance for the call to end before it hits the 3 minute mark.
Calculate Exponential Distribution in Python:
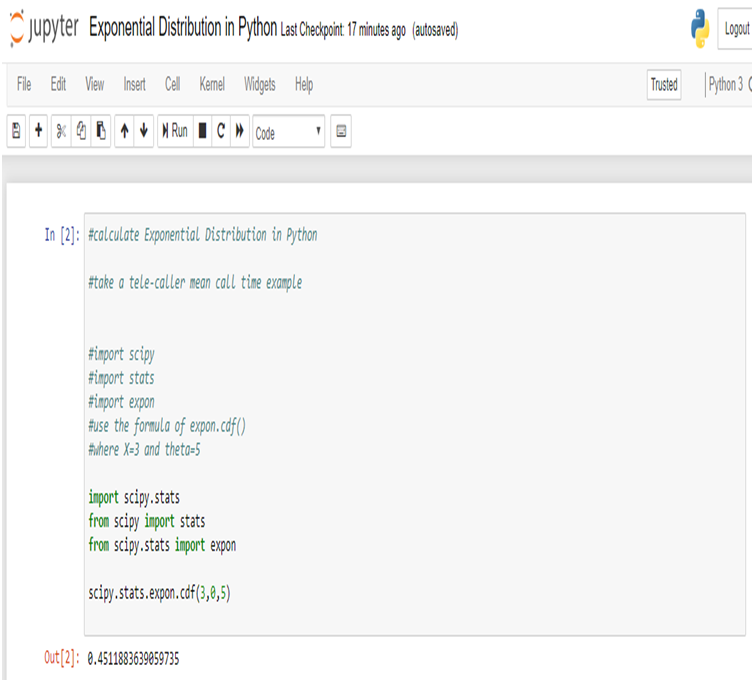
We get the same result using Python.
Conclusion:
We use exponential distribution to predict the amount of waiting time until the next event (i.e., success, failure, arrival, etc).
Here we try to predict that the probability of the mean call time of the telemarketer will be less than 3 minutes instead of 5 minutes for one call, with the help of Exponential Distribution. Similarly, the exponential distribution is of particular relevance when faced with business problems that involve the continuous rate of decay of something. For instance, when attempting to model the rate with which the batteries will run out.

Hopefully, this blog has enabled you to gather a better understanding of the exponential distribution. For more such interesting blogs and useful insights into the technologies of the age, check out the best Analytics Training institute Gurgaon, with extensive Data Science Courses in Gurgaon and Data analyst course in Delhi NCR.
Lastly, let us know your opinions about this blog through your comments below and we will meet you with another blog in our series on data science blogs soon.
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.