
This is the second part of the Regex series, where we will be continuing on by introducing you to another library in python, the re library. The previous blog introduced you to the Regex library in Python, and you learned about meta-characters and literals which could be used for creating patterns. This particular segment is about introducing the re library to help you with textual data analysis.
Re library in python holds the key to deal with all the problems relating to textual data analysis. This library provides a range of methods that can help you build patterns and extract or substitute the desired string. For example, suppose you want to change all the negative words to positive in a novel, for that all you need to have is a soft copy of the same and then you can import the re library and use its predefined methods first to make a pattern to extract the words and then substitute it to make the required changes.
Here one such method which we are going to use today from the re library is .compile() combined with .match() method to build and extract the pattern with the help of literals and meta-characters explained in the previous blog.
.compile() and .match() Methods
.complie() is used to build the pattern. You can use the meta-characters and literals within the parenthesis to build the pattern of the word which you want to extract or change. This is practically the first step without which not much can be done in re library. But why do we need a pattern and what is it that makes it necessary? To answer this question I am going to use few steps:-
- First thing to do is to observe the word or the string and see what is it that makes that specific word or words which you want to extract different from the rest of the text i.e. is the word a combination of digit or alphabet or special character, is there a special character before and after the word etc.
- Now recall all the meta-characters we have studied so far.
- Combine them with the .complie() method which basically helps us bring the meta-characters together.
- Now all there is left for us to do is apply the pattern on the text.
Therefore knowledge of meta-characters is necessary to form patterns to manipulate your textual data.
Now let’s see how to import re library and practically solve few of the Regex questions.
![]()
Use the above code to import the Regex library.
Question 1: How to make a pattern to extract the entire string “Hello dexlab…!!”?

In the above code we are using a combination of. (period)and * where
- . (period) means match alpha-numeric or special character
- * means match anything zero or more times
When combined together this means that you can match alpha-numeric or special characters zero or more times. Therefore the end result is:-
![]()
.match()method has a special property that it can match anything only at the beginning of the line. Suppose I want to extract “Hello” from a string, .match()method will only work when word is at the 0 index.
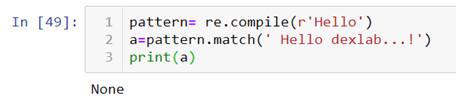
Question: How to extract and match only special characters?

The above code is matching only the space which is at the 0th index but not all the simultaneous special characters. To make a pattern that can match all the special characters we can use *

You can try ? and + to check the difference it makes on the output.
Question: How to extract numbers and special characters?

Now you must be wondering why the above code did not recognize the special characters after the numbers like @ and space. Here you must remember that the output you get is based on the pattern you make. In the above code we mentioned nothing that matches anything after the numbers. So we further need to expand our line of codes.

Question: How to extract only the output?

You can use the slice operator [] to extract only the text by using 0 index.
You must have picked up the fundamentals of the re library from the blog, watch the video attached below to follow the tutorial step by step. Follow the Regex series to gain expertise in textual data handling. Dexlab Analytics blog has more interesting and informative posts on Python Programming training.
.