
Deep learning is a subset of machine learning, a branch of artificial intelligence that configures computers to perform tasks through experience. While classic machine-learning algorithms solved many problems, they are poor at dealing with soft data such as images, video, sound files, and unstructured text.
Deep-learning algorithms solve the same problem using deep neural networks, a type of software architecture inspired by the human brain (though neural networks are different from biological neurons). Neural Networks are inspired by our understanding of the biology of our brains – all those interconnections between the neurons. But, unlike a biological brain where any neuron can connect to any other neuron within a certain physical distance, these artificial neural networks have discrete layers, connections, and directions of data propagation.
The data is inputted into the first layer of the neural network. In the first layer individual neurons pass the data to a second layer. The second layer of neurons does its task, and so on, until the final layer and the final output is produced. Each neuron assigns a weighting to its input — how correct or incorrect it is relative to the task being performed. The final output is then determined by the total of those weightings.
Deep Learning Use Case Examples
Robotics
Many of the recent developments in robotics have been driven by advances in AI and deep learning. Developments in AI mean we can expect the robots of the future to increasingly be used as human assistants. They will not only be used to understand and answer questions, as some are used today. They will also be able to act on voice commands and gestures, even anticipate a worker’s next move. Today, collaborative robots already work alongside humans, with humans and robots each performing separate tasks that are best suited to their strengths.
Agriculture
AI has the potential to revolutionize farming. Today, deep learning enables farmers to deploy equipment that can see and differentiate between crop plants and weeds. This capability allows weeding machines to selectively spray herbicides on weeds and leave other plants untouched. Farming machines that use deep learning–enabled computer vision can even optimize individual plants in a field by selectively spraying herbicides, fertilizers, fungicides and insecticides.
Medical Imaging and Healthcare
Deep learning has been particularly effective in medical imaging, due to the availability of high-quality data and the ability of convolutional neural networks to classify images. Several vendors have already received FDA approval for deep learning algorithms for diagnostic purposes, including image analysis for oncology and retina diseases. Deep learning is also making significant inroads into improving healthcare quality by predicting medical events from electronic health record data. Earlier this year, computer scientists at the Massachusetts Institute of Technology (MIT) used deep learning to create a new computer program for detecting breast cancer.
Here are some basic techniques that allow deep learning to solve a variety of problems.
Fully Connected Neural Networks
Fully Connected Feed forward Neural Networks are the standard network architecture used in most basic neural network applications.
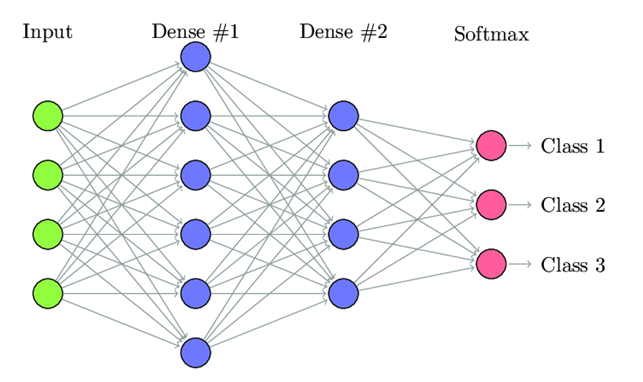
In a fully connected layer each neuron is connected to every neuron in the previous layer, and each connection has its own weight. This is a totally general purpose connection pattern and makes no assumptions about the features in the data. It’s also very expensive in terms of memory (weights) and computation (connections).
Each neuron in a neural network contains an activation function that changes the output of a neuron given its input. These activation functions are:
- Linear function: – it is a straight line that essentially multiplies the input by a constant value.
- Sigmoid function: – it is an S-shaped curve ranging from 0 to 1.
- Hyperbolic tangent (tanH) function: – it is an S-shaped curve ranging from -1 to +1
- Rectified linear unit (ReLU) function: – it is a piecewise function that outputs a 0 if the input is less than a certain value or linear multiple if the input is greater than a certain value.
Each type of activation function has pros and cons, so we use them in various layers in a deep neural network based on the problem. Non-linearity is what allows deep neural networks to model complex functions.
Convolutional Neural Networks
Convolutional Neural Networks (CNN) is a type of deep neural network architecture designed for specific tasks like image classification. CNNs were inspired by the organization of neurons in the visual cortex of the animal brain. As a result, they provide some very interesting features that are useful for processing certain types of data like images, audio and video.

Mainly three main types of layers are used to build ConvNet architectures: Convolutional Layer, Pooling Layer, and Fully-Connected Layer (exactly as seen in regular Neural Networks). We will stack these layers to form a full ConvNet architecture. A simple ConvNet for CIFAR-10 classification could have the above architecture [INPUT – CONV – RELU – POOL – FC].
- INPUT [32x32x3] will hold the raw pixel values of the image, in this case an image of width 32, height 32, and with three color channels R,G,B.
- CONV layer will compute the output of neurons that are connected to local regions in the input, each computing a dot product between their weights and a small region they are connected to in the input volume. This may result in volume such as [32x32x12] if we decided to use 12 filters.
- RELU layer will apply an elementwise activation function, such as the max(0,x)max(0,x)thresholding at zero. This leaves the size of the volume unchanged ([32x32x12]).
- POOL layer will perform a downsampling operation along the spatial dimensions (width, height), resulting in volume such as [16x16x12].
- FC (i.e. fully-connected) layer will compute the class scores, resulting in volume of size [1x1x10], where each of the 10 numbers correspond to a class score, such as among the 10 categories of CIFAR-10. As with ordinary Neural Networks and as the name implies, each neuron in this layer will be connected to all the numbers in the previous volume.
In this way, ConvNets transform the original image layer by layer from the original pixel values to the final class scores. Note that some layers contain parameters and others don’t. In particular, the CONV/FC layers perform transformations that are a function of not only the activations in the input volume, but also of the parameters (the weights and biases of the neurons). On the other hand, the RELU/POOL layers will implement a fixed function. The parameters in the CONV/FC layers will be trained with gradient descent so that the class scores that the ConvNet computes are consistent with the labels in the training set for each image.
Convolution is a technique that allows us to extract visual features from an image in small chunks. Each neuron in a convolution layer is responsible for a small cluster of neurons in the receding layer. CNNs work well for a variety of tasks including image recognition, image processing, image segmentation, video analysis, and natural language processing.
Recurrent Neural Network
The recurrent neural network (RNN), unlike feed forward neural networks, can operate effectively on sequences of data with variable input length.
The idea behind RNNs is to make use of sequential information. In a traditional neural network we assume that all inputs (and outputs) are independent of each other. But for many tasks that is a very bad idea. If you want to predict the next word in a sentence you better know which words came before it. RNNs are called recurrent because they perform the same task for every element of a sequence, with the output being depended on the previous computations. Another way to think about RNNs is that they have a “memory” which captures information about what has been calculated so far. This is essentially like giving a neural network a short-term memory. This feature makes RNNs very effective for working with sequences of data that occur over time, For example, the time-series data, like changes in stock prices, a sequence of characters, like a stream of characters being typed into a mobile phone.
The two variants on the basic RNN architecture that help solve a common problem with training RNNs are Gated RNNs, and Long Short-Term Memory RNNs (LSTMs). Both of these variants use a form of memory to help make predictions in sequences over time. The main difference between a Gated RNN and an LSTM is that the Gated RNN has two gates to control its memory: an Update gate and a Reset gate, while an LSTM has three gates: an Input gate, an Output gate, and a Forget gate.
RNNs work well for applications that involve a sequence of data that change over time. These applications include natural language processing, speech recognition, language translation, image captioning and conversation modeling.
Conclusion
So this article was about various Deep Learning techniques. Each technique is useful in its own way and is put to practical use in various applications daily. Although deep learning is currently the most advanced artificial intelligence technique, it is not the AI industry’s final destination. The evolution of deep learning and neural networks might give us totally new architectures. Which is why more and more institutes are offering courses on AI and Deep Learning across the world and in India as well. One of the best and most competent artificial intelligence certification in Delhi NCR is DexLab Analytics. It offers an array of courses worth exploring.
.
Artificial Intelligence, artificial intelligence analytics, artificial intelligence certification, artificial intelligence training institute, deep learning certification, deep learning course, Deep Learning Training, Deep Learning Training Courses, Deep learning Training Institutes, neural network course, Neural Networks