The theory of estimation is a branch in statistics that provides numerical values of the unknown parameters of the population on the basis of the measured empirical data that has a random component. This is a process of guessing the underlying properties of the population by observing the sample that has been taken from the population. The idea behind this is to calculate and find out the approximate values of the population parameter on the basis of a sample statistics.
Population:- All the items in any field of inquiry constitutes to a “Population”. For example all the employees of a factory is a population of that factory and the population mean is represented and the size of the population is represented by N.
Sample:- Selection of few items from the population constitutes to a sample and the mean of the sample is represented by and the sample size is represented by n
Statistics:- Any statistical measure calculated on the basis of sample observations is called Statistic. Like sample mean, sample standard deviation, etc.
Estimator:- In general estimator acts as a rule, a measure computed on the basis of the sample which tells us how to calculate the values of the estimate. It is a functional form of all sample observations prorating a representative value of the collected sample.
Suppose we have a random sample x_1,x_2,…,x_n on a variable x, whose distribution in the population involves an unknown parameter. It is required to find an estimate of on the basis of sample values.
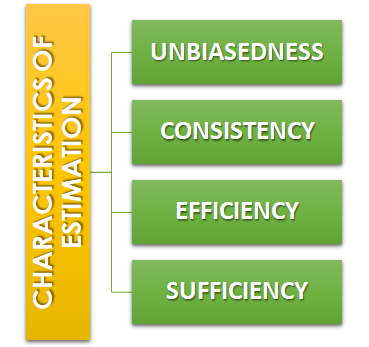
Unbiasedness:-A statistic t is said to be an unbiased estimator if E(β ̂)= βi.e. observed value is equal to the expected value. In case E(β ̂)≠ β then the estimator is biased estimator.
Consistency:- One of the most desirable property of good estimator is that its accuracy should increase when the sample becomes larger i.e. the error between the expected value and the observed value reduces as the size of the sample increases E(β ̂ )- β=0
Efficiency:-An estimator is said to be an efficient estimator if it has the smallest variance compared to all the consistent and unbiased estimators. If consistent estimator exists whose sampling variance is less than that of any other consistent estimator, it is said to be “most efficient”; and it provides a standard for the measurement of ‘efficiency’ of a statistic.

Sufficiency:- An estimator is said to be sufficient if it contains all information in the sample about .
At the end of this discussion, hopefully, you have learned what theory of estimation is. Watch the video tutorial attached below to learn more about this. DexLab Analytics is a data science training institute in gurgaon, that offers advanced courses. Follow the blog section to access more informative posts like this.
.