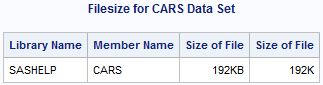
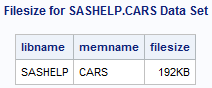
Getting introduced to statistics for SAS training? Then, you must know how to create summary statistics (such as sample size, mean, and standard deviation) to test hypotheses and to figure confidence intervals. In this blog, we will show you how to furnish summary statistics (instead of raw data) to PROC TTEST in SAS, how to develop a data set that includes summary statistics and how to run PROC TTEST to calculate a two-sample or one-sample t test for the mean.
So, let’s start!

Running a two-sample t test for difference of means from summarized statistics
Instead of going the clichéd way, we will start with establishing a comparison between the mean heights of 19 students, based on gender – the data is held in the Sashelp class data set.
Observe the below SAS statements that sorts the data by the grouping variable, calling PROC MEANS and printing a subset of the statistics:
proc sort data=sashelp.class out=class; by sex; /* sort by group variable */ run; proc means data=class noprint; /* compute summary statistics by group */ by sex; /* group variable */ var height; /* analysis variable */ output out=SummaryStats; /* write statistics to data set */ run; proc print data=SummaryStats label noobs; where _STAT_ in ("N", "MEAN", "STD"); var Sex _STAT_ Height; run; |
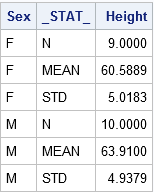
The table reflects the structure of the Summary Stats set for two sample tests. The two samples used here are differentiated on the levels of the Sex Variable (‘F’ for females and ‘M’ for males). The _STAT_ column shows the name of the statistic implemented here. The Height column depicts the value of the statistics for individual group.
Get SAS certification Delhi from DexLab Analytics today!
The problem: The heights of sixth-grade students are normally distributed. Random samples of n1=9 females and n2=10 males are selected. The mean height of the female sample is m1=60.5889 with a standard deviation of s1=5.0183. The mean height of the male sample is m2=63.9100 with a standard deviation of s2=4.9379. Is there evidence that the mean height of sixth-grade students depends on gender?
Here, you have to do nothing special to get the PROC TTEST – whenever the procedure gets the sight of the respective variable _STAT_ and any unique values, the procedure understands that the data set comprises summarized statistics. The following representation compares the mean heights of males and females:
proc ttest data=SummaryStats order=data alpha=0.05 test=diff sides=2; /* two-sided test of diff between group means */ class sex; var height; run; |
Check the confidence intervals for the standard deviations and also that the output includes 95% confidence intervals for group means.
In the second table, the ‘Pooled’ row radiates out the impression that both the variances of two groups are more or less equal, which is somewhat true even. The value of the t statistic is t = -1.45 with a two-sided p-value of 0.1645.
The syntax for the PROC TTEST statement allows you to change the type of hypothesis test and the significance level. To support this, you can now run a one-sided test for the alternative hypothesis μ1 < μ2 at the 0.10 significance level just by using:
proc ttest ... alpha=0.10 test=diff sides=L; /* Left-tailed test */ |
Running a one-sample t test of the mean from summarized statistics
In the above section, you have learnt to create the summary statistics from PROC MEANS. Nevertheless, you can also generate the summary statistic manually, if you lack original data.
The problem: A research study measured the pulse rates of 57 college men and found a mean pulse rate of 70.4211 beats per minute with a standard deviation of 9.9480 beats per minute. Researchers want to know if the mean pulse rate for all college men is different from the current standard of 72 beats per minute.
The following statements jots down the summary statistics for a data set, asks PROC TTEST to perform a one-sample test of the null hypothesis μ = 72 against a two-sided alternative hypothesis:
data SummaryStats; infile datalines dsd truncover; input _STAT_:$8. X; datalines; N, 57 MEAN, 70.4211 STD, 9.9480 ; proc ttest data=SummaryStats alpha=0.05 H0=72 sides=2; /* H0: mu=72 vs two-sided alternative */ var X; run; |
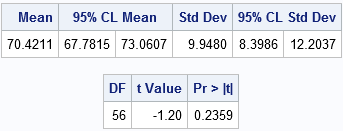
The outcome is a 95% confidence interval for the mean containing a value 72. The value of the t statistic is t = -1.20, which corresponds to a p-value of 0.2359. Therefore, the data fails in rejecting the null hypothesis at the 0.05 significance level.
For more informative blogs and news about SAS course, drop by our prime SAS predictive modeling training institute DexLab Analytics.
This post originally appeared on – blogs.sas.com/content/iml/2017/07/03/summary-statistics-t-tests-sas.html
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.