At the previous month’s “R user group meeting in Melbourne”, they had a theme going; which was “Experiences with using SAS and R in insurance and banking”. In that convention, Hong Ooi from ANZ (Australia and New Zealand Banking Group) spoke on the “experiences in credit risk analysis with R”. He gave a presentation, which has a great story told through slides about implementing R programming for fiscal analyses at a few major banks.
In the slides he made, one can see the following:
How R is used to fit models for mortgage loss at ANZ
A customized model is made to assess the probability of default for individual’s loans with a heavy tailed T distribution for volatility.
One slide goes on to display how the standard lm function for regression is adapted for a non-Gaussian error distribution — one of the many benefits of having the source code available in R.
A comparison in between R and SAS for fitting such non-standard models
Mr. Ooi also notes that SAS does contain various options for modelling variance like for instance, SAS PROC MIXED, PRIC NLIN. However, none of these are as flexible or powerful as R. The main difference as per Ooi, is that R modelling functions return as object as opposed to returning with a mere textual output. This however, can be later modified and manipulated with to adapt to a new modelling situation and generate summaries, predictions and more. An R programmer can do this manipulation.
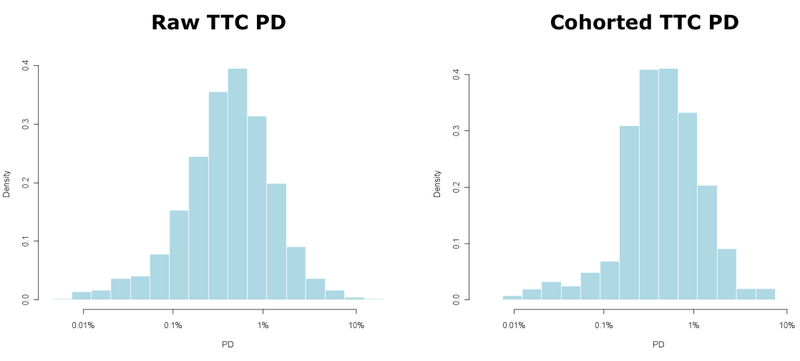
We can use cohort models to aggregate the point estimates for default into an overall risk portfolio as follows:
Photo Coutesy of revolution-computing.typepad.com
He revealed how ANZ implemented a stress-testing simulation, which made available to business users via an Excel interface:
The primary analysis is done in r programming within 2 minutes usually, in comparison to SAS versions that actually took 4 hours to run, and frequently kept crashing due to lack of disk space. As the data is stored within SAS; SAS code is often used to create the source data…
While an R script can be used to automate the process of writing, the SAS code can do so with much simplicity around the flexible limitations of SAS.
Comparison between use of R and SAS’s IML language to implement algorithms:
Mr. Ooi’s R programming code has a neat trick of creating a matrix of R list objects, which is fairly difficult to do with IML’s matrix only data structures.
He also discussed some of the challenges one ma face when trying to deploy open-source R in the commercial organizations, like “who should I yell at if things do now work right”.
And lastly he also discussed a collection of typically useful R resources as well.
For people who work in a bank and need help adopting R in the workflow, may make use of this presentation to get some knowledge about the same. And also feel free to get in touch with our in-house experts in R programming at DexLab Analytics, the premiere R programming training institute in India.
To learn more about Data Analyst with Advanced excel course – Enrol Now. To learn more about Data Analyst with R Course – Enrol Now. To learn more about Big Data Course – Enrol Now.
To learn more about Machine Learning Using Python and Spark – Enrol Now. To learn more about Data Analyst with SAS Course – Enrol Now. To learn more about Data Analyst with Apache Spark Course – Enrol Now. To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.
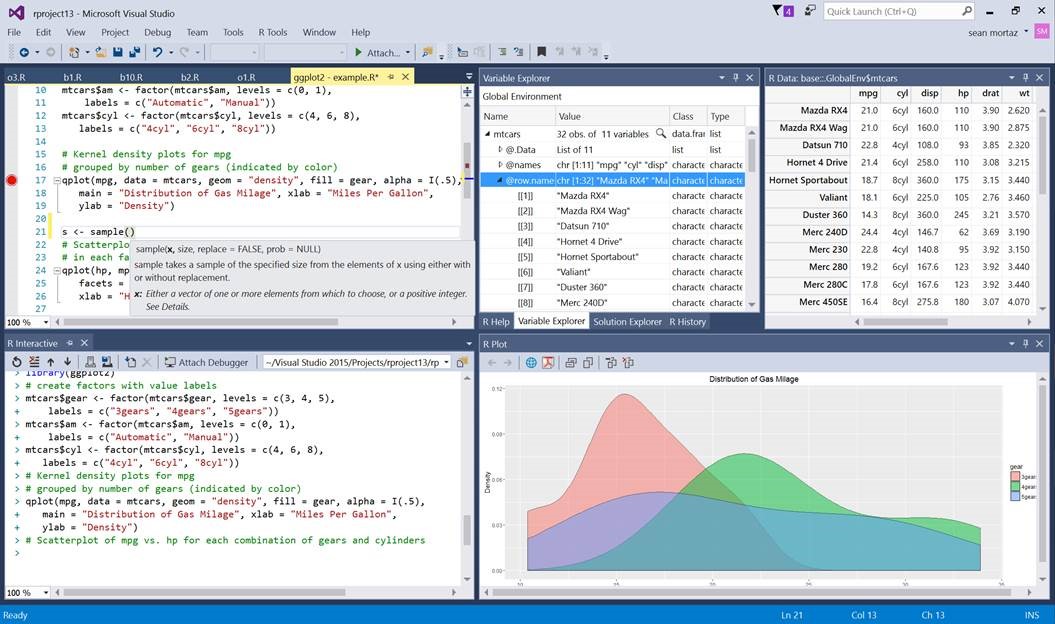
It is a great new development that the new Visual Studio now speaks the R Language!
Here is how:
Decidedly now R is the most popular statistical data analysis language which is in use these days. The R tools for Visual Studio brings together the power of R and Visual Studio in the same pod, for a convenient, and easy to use plug-in that is not only free and open source, but is very user friendly. When it is combined with the powers of Visual Studio Community Edition, then you will receive a multilingual IDE, which is perpetually free for all small teams.
In order to showcase and inspire testing and evaluation from the developer community, the R tools package for Visual Studios has been launched as a public preview version.
Here are the new exciting features being introduced in this preview release version:
Editor – this is a complete package for fine editing experience finished with R scripts and functions, which also include detachable/ tabbed windows, syntax highlighting and a lot more.
IntelliSense – this is also known as auto-completion and is available in both the editor as well as the Interactive R window
R Interactive Window – with this you can work directly with R console from within the Visual Studio
History window – one can search, view, and select previous commands and then send it to the Interactive Window.
A variable explorer – now get the advantage to drill deep into your R data structures and examine their values
Plotting – now check all your R plots within a Visual Studio tool window
Debugging – stepping, breakpoints, watch windows, call stacks and much more
R markdown – get to use R Markdown/knitr support with export to Word and HTML
Git – get control over source code through Git and GitHub
Extensions – more than 6000 extensions covering a wide spectrum from Data to Productivity to Language
Help – view R documentation with the use of ? and ?? in Visual Studio itself
A polyglot IDE– VS supports, R, Python, C and C++, C#, Node.js, SQL, etc projects can be managed simultaneously.
Some other features that were requested by the R developer community are the Package Manager GUI, Visual Studio Code (cross-plat), and more, which will be a part of one of our future updates.
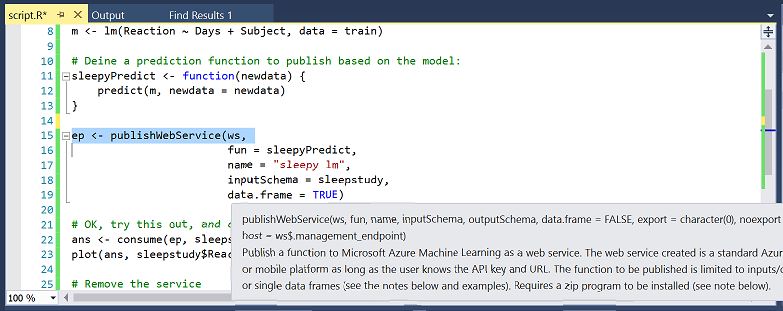
Now use Azure ML SDK:
Now you can use the R SDK with the RTVS to access all your datasets and also workspaces on the Azure ML. You can use the environment to build and test the models locally and easily operationalize them at scale on Azure.
This SDK is not tied to RTVS, but it can be used from any environment to publish models to Azure ML.
Conclusion:
This new element to the analytics offerings viz. a powerful R authoring environment post their previous announcements of Microsoft R Open and Microsoft R server announcements that took place last year is an exciting development.
For more exciting news on RTVS stay tuned to our regular blogs, because the time has never been better to be a data analyst.
To learn more about Machine Learning Using Python and Spark – click here. To learn more about Data Analyst with Advanced excel course – click here. To learn more about Data Analyst with SAS Course – click here. To learn more about Data Analyst with R Course – click here. To learn more about Big Data Course – click here.
We are happy to announce our month-long corporate training session for the representatives of WHO, who will be joining us to discuss data analytics all the way from Bhutan. The team of delegates who have come to seek training from our expert in-house trainers are for the Central of Disease Control, Ministry of Health Royal Government of Bhutan.
The training is on the concepts of R Programming, Data Science using R and Statistical Modelling using R, and will go on from the 8th of February 2017 to the 8th of March 2017. We are hosting this training session at our headquarters in Gurgaon, Delhi NCR. It is a matter of great pride and honour for the team of seasoned industry expert trainers at DexLab Analytics to be hosting the representatives from WHO.
Recently, a discussion was held, which invited data scientists and analysts all over the world, to take part in the Science of Super Bowl discussion panel, this discussion was held by Newswise.
We found one notable discussion topic, which answered three very important questions related to data science that the sports industry could use:
It is a well-known fact that Python, R and SAS are the most important three languages to be learnt for data analysis.
If you are a fresh blood in the data science community and are not experienced in any of the above-mentioned languages, then it makes a lot of sense to be acquainted with R, SAS or Python.
DexLab Analytics over the course of next few weeks will cover the basics of various data analysis techniques like creating your own histogram in R programming. We will explore three options for this: R commands, ggplot2 and ggvis. These posts are for users of R programming who are in the beginner or intermediate level and who require accessible and easy to understand resources.
A histogram is a category of visual representation of a dataset distribution. As such the shape of a histogram is its most common feature for identification. With a histogram one will be able to see which factor has the relatively higher amount of data and which factors or segments have the least.
Or put in simpler terms, one can see where the middle or median is in a data distribution, and how close or farther away the data would lie around the middle and where would the possible outliers be found. And precisely because of all this histograms will be the best way to understand your data.
But what can a specific shape of a histogram tell us? In short a typical histogram consists of an x-axis and a y-axis and a few bars of varying heights. The y-axis will exhibit how frequently the values on the x-axis are occurring in the data. The y-axis showcases the frequency of the values on the x-axis where the data occurs, the bar group ranges of either values or continuous categories on the x-axis. And the latter explains why the histograms do not have any gaps between the bars.
How can one make a histogram with basic R?
Step 1: Get your eyes on the data:
As histograms require some amount of data to be plotted initially, you can carry that out by importing a dataset or simply using one which is built into the system of R. In this tutorial we will make use of 2 datasets the built-in R dataset AirPassengers and another dataset called as chol, which is stored into a .txt file and is available for download.
Step 2: Acquaint yourself with The Hist () function:
One can make a histogram in R by opting the easy way where they use The Hist () function, which automatically computes a histogram of the given data values. One would put the name of their dataset in between parentheses to use this function.
Here is how to use the function:
hist(AirPassengers)
But if in case, you want to select a certain column of a data frame like for instance in chol, for making a histogram. The hist function should be used with the dataset name in combination with a $ symbol, which should be followed by the column name:
Here is a specimen showing the same:
hist(chol$AGE) #computes a histogram of the data values in the column AGE of the dataframe named “chol”
Step 3: Up the level of the hist () function:
You may find that the histograms created with the previous features seem a little dull. That is because the default visualizations do not contribute much to the understanding of the histograms. One may need to take one more step to reach a better and easier understanding of their histograms. Fortunately, this is not too difficult to accomplish, R has several allowances for easy and fast ways to optimize the visualizations of the diagrams while still making use of the hist () function.
To adapt your histogram you will only need to add more arguments to the hist () function, in this way:
hist(AirPassengers, main="Histogram for Air Passengers", xlab="Passengers", border="blue", col="green", xlim=c(100,700), las=1, breaks=5)
This code will help to compute a histogram of data values from the dataset AirPassengers, with the name “Histogram for Air Passengers” as the title. The x-axis would be labelled as ‘Passengers’ and will have a blue border with a green colour to the bins, while limiting the x-axis with a range of 100 to 700 and rotating the printed values on the y-axis by 1 while changing the bin width by 5.
We know what you are thinking – this is a humungous string of code. But do not worry, let us break it down into smaller pieces to see what each component holds.
Name/colours:
You can alter the title of the histogram by adding main as an argument to the hist () function.
This is how:
hist(AirPassengers, main=”Histogram for Air Passengers”) #Histogram of the AirPassengers dataset with title “Histogram for Air Passengers”
For adjusting the label of the x-axis you can add xlab as the feature. Similarly one can also use ylab to label the y-axis.
This code would work:
hist(AirPassengers, xlab=”Passengers”, ylab=”Frequency of Passengers”) #Histogram of the AirPassengers dataset with changed labels on the x-and y-axes hist(AirPassengers, xlab=”Passengers”, ylab=”Frequency of Passengers”) #Histogram of the AirPassengers dataset with changed labels on the x-and y-axes
If in case you would want to change the colours of the default histogram you can simply choose to add the arguments border or col. Adjusting would be easy, as the name itself kind of gives away the borders and the colours of the histogram.
hist(AirPassengers, border=”blue”, col=”green”) #Histogram of the AirPassengers dataset with blue-border bins with green filling
Note: you must not forget to put the names and the colours within “ ”.
For x and y axes:
To change the range of the x and y axes one can use the xlim and the ylim as arguments to the hist function ():
The code to be used is:
hist(AirPassengers, xlim=c(100,700), ylim=c(0,30)) #Histogram of the AirPassengers dataset with the x-axis limited to values 100 to 700 and the y-axis limited to values 0 to 30
Point to be noted in this case, is the c() function is used for delimiting the values on the axes when one is suing the xlim and ylim functions. It takes 2 values the first being the begin value and the second being the end value.
Make sure to rotate the labels on the y-axis by adding 1as=1 as the argument, the argument 1as can be 0, 1, 2 or 3.
The code to be used:
hist(AirPassengers, las=1) #Histogram of the AirPassengers dataset with the y-values projected horizontally
Depending on the option one chooses the placement of the label will vary: like for instance, if you choose 0 the label will always be parallel to the axis (the one that is the default). And if one chooses 1, The label will be horizontally put. If you want the label to be perpendicular to the axis then pick 2 and for placing it vertically select 3.
For bins:
One can alter the bin width by including breaks as an argument, in combination with the number of breakpoints which one wants to have.
This is the code to be used:
hist(AirPassengers, breaks=5) #Histogram of the AirPassengers dataset with 5 breakpoints
If one wants to have increased control over the breakpoints in between the bins, then they can enrich the breaks arguments by adding in it vector of breakpoints, one can also do this by making use of the c() function.
hist(AirPassengers, breaks=c(100, 300, 500, 700)) #Compute a histogram for the data values in AirPassengers, and set the bins such that they run from 100 to 300, 300 to 500 and 500 to 700.
But the c () function can help to make your code very messy at times, which is why we recommend using add = seq(x,y,z) instead. The values of x, y and z are determined by the user and represented in a specific order of appearance, the starting number of x-axis and the last number of the same as well as the intervals in which these numbers are to appear.
A noteworthy point to be mentioned here is that one can combine both the functions:
hist(AirPassengers, breaks=c(100, seq(200,700, 150))) #Make a histogram for the AirPassengers dataset, start at 100 on the x-axis, and from values 200 to 700, make the bins 150 wide
Here is the histogram of AirPassengers:
How to Make a Histogram with Basic R – (Image Courtesy r-bloggers)
Please note that this is the first blog tranche in a list of 3 posts on creating histograms using R programming.
For more information regarding R language training and other interesting news and articles follow our regular uploads at all our channels.
To learn more about Machine Learning Using Python and Spark – click here.
To learn more about Data Analyst with Advanced excel course – click here. To learn more about Data Analyst with SAS Course – click here. To learn more about Data Analyst with R Course – click here. To learn more about Big Data Course – click here.
With the Big Data boom within the IT industry worldwide, more and more online retailers are using it to create better shopping experience for their customers through a boost in customer satisfaction to generate better revenue for themselves.
Dexlab Analytics is Conducting Training for Snapdeal in Data Science and R Programming
The funny news about Target knowing about a young lady’s pregnancy even before the father could was a viral content that sent the internet crazy. But how did they know this?
The answer lies in the wizardry of data analysis, as when a lady starts searching to buy products like nutritional supplements, unscented beauty products and cotton balls then there is a good chance that she is pregnant.
DexLab Analytics is proud to announce a complimentary online demo session which will be held on Saturday 15th October, 2016 at 10:00 PM on the topic of R Programming, Core Analytics & Predictive Modelling. It will be a 30 to 45 minute session which will give the aspiring candidates a glimpse into the content quality, delivery style and intractability with the faculty at the institute.
Those who want to join this demo session must email stating their interest directly to DexLab Analytics for registering for the same. Although as is the common notion about free things that they are usually of poor quality, but for this complimentary session we can promise the case will not stand true. This session will offer ample insight about what to expect in the upcoming batches. This is a one-of-a-kind endeavour by DexLab Analytics as no other analytics training institute offers such complimentary sessions.Continue reading “We are offering a free demo session on: R Programming Core Analytics & Predictive Modelling”