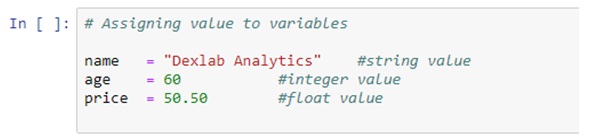
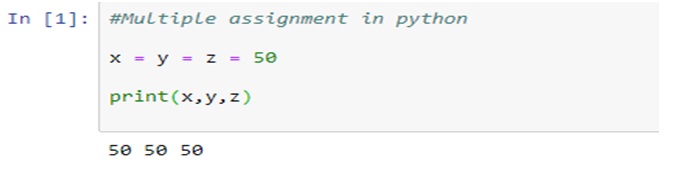
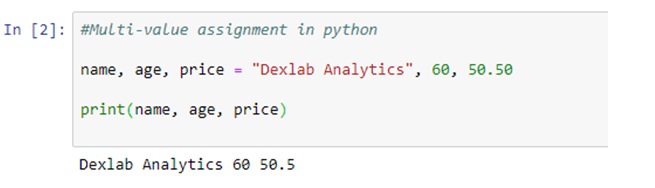
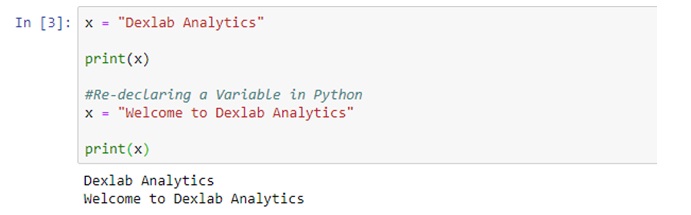
A business organization has to deal with a massive amount of data streaming from myriad sources, and data warehousing refers to the process of collection and storage of that data that needs to be analyzed to glean valuable business insight. Data warehousing plays a crucial role in business intelligence. The concept originated in the 1980s, it basically involves data extraction from disparate sources which later gets processed and post formatting the data stays in the system ready to be utilized for taking important decisions.
Data warehouse basically performs the task of running an analysis on the stored data which could be both structured and unstructured even semi-structured, however, the data that is in the warehouse cannot be modified. Data warehousing basically helps companies gain insight regarding factors influencing business, and they could use the data insight to formulate new strategies, developing products and so on. This highly skilled task demands professionals who have a background in Data science using python training.
What are the different steps in data warehousing?
Data warehousing involves the following steps
Transactional data extraction: In this step, the data is extracted from multiple sources available and loaded into the system.
Data transformation: The transactional data extracted from different sources need to be transformed and it would need relating as well.
Building a dimensional model: A dimensional model comprising fact and dimension tables are built and the data gets loaded.
Getting a front-end reporting tool: The tool could be built or, purchased, a crucial decision that needs much deliberation.
Benefits of data warehousing
An edge over the competition
This is undeniably one benefit every business would be eager to reap from data warehousing. The data that is untapped could be the source of valuable information regarding risk factors, trends, customers and so many other factors that could impact the business. Data warehousing collates the data and arranges them in a contextual manner that is easy for a company to access and utilize to make informed decisions.
Enhanced data quality
Since data pooled from different sources could be structured or, unstructured and in different formats, working with such data inconsistency could be problematic and data warehousing takes care of the issue by transforming the data into a consistent format. The standardized data that easily conforms to the analytics platform can be of immense value.
Historical data analysis
A data warehouse basically stores a big amount of data and that includes historical data as well. Such data are basically old records of the company regarding sales, employee data, or, product-related information. Now the historical data belonging to different time periods need to be analyzed to predict upcoming trends.
Smarter business intelligence
Since businesses now rely on data-driven insight to devise strategies, they need access to data that is consistent, error-free, and high quality. However, data coming from numerous sources could be erroneous and irrelevant. But, data warehousing takes care of this issue by formatting the data to make it consistent and free from any error and could be analyzed to offer valuable insight that could help the management take decisions regarding sales, marketing, finance.
High ROI
Building a data warehouse requires significant investment but in the long term, the revenue that it generates can be significant. In fact, keen business intelligence now plays a crucial role in determining the success of an organization and with data warehousing the organizations can have access to data that is consistent and high quality thus enabling the company to derive actionable intel. When a company implements such insight in making smarter strategies, they do gain in the long run.

Data warehousing plays a significant role in collating and storing valuable data that fuels a company’s business decisions. However, given the specialized nature of the task, one must undergo Data Science training, to learn the nuances. The field of big data has plenty of opportunities for the right candidates.
.