This is the 3rd part of the ongoing Regex or, regular expression in Python series where we are discussing how to handle textual data. In the second part we introduced you to the re library and in this third segment, we are going to be discussing how to substitute characters or, words with re library.
Re library has a wide range of methods to deal with textual data, one such method is .sub() which helps us substitute alphabets or words based on the patterns we build. This method can be used with .match() method and .search() method, both having differences in the way they extract a pattern.
Difference between .match() & .search()
.match() :- This method extracts the required text only at the begging.
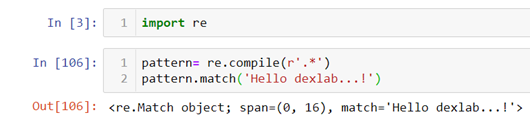
.search() :-This can extract the required string from the entire text but only at the first occurrence

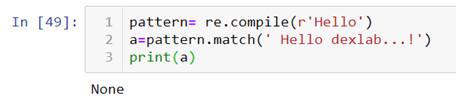
In the above code you can see that even though the word “Hello” is in the middle of the text we are able to fetch it because of the special attribute of the .search() method. Here we are again using “Hello dexlab…!” as an example and .compile() is being used to create and apply our pattern.
Now suppose if we want to substitute the word “Hello” with another string “Hi” we will have to use .sub() method from the re library. But there are ways to use this method directly or indirectly.
First let’s see the direct method.

In the above line of code we first mention what we want to substitute and with what and then we add the text.
Second way to do this is by first using .compile() method to build the pattern and then use that pattern to substitute the alphabet or word.

The above pattern in the .complie() method states that there is a word with the first alphabet in uppercase combined with lowercase alphabets to be substituted with the word “Hi”. This pattern can match any string with the same characteristics, for example:-
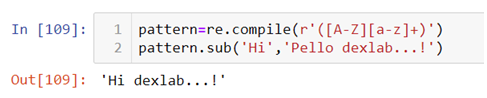
Look at the text used in the .sub() method, now instead of “Hello” we have “Pello” with the same characteristics substituted with the word “Hi”. But one must not forget this pattern can also be used in the .sub() method directly and the use of .compile() method is optional. .compile() method is used only to create an object based code.
So, this wraps up the discussion on how to substitute characters or, words with re library. Hopefully, you found this blog informative, if you wish to find more Python Certification course topics, keep following the Dexlab Analytics blog.
.