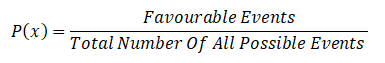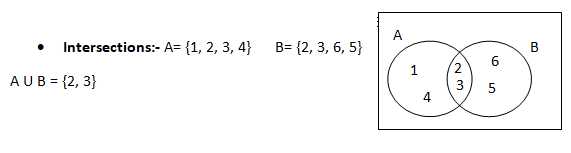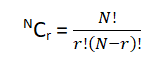Today we will begin discussion about a significant concept, probability, which measures the likelihood of the occurrence of an event. This is the first part of the series, where you would be introduced to the core concept. So, let’s begin.
What is probability?
It is a measure of quantifying the likelihood that an event will occur and it is written as P(x).
Key concepts of probability
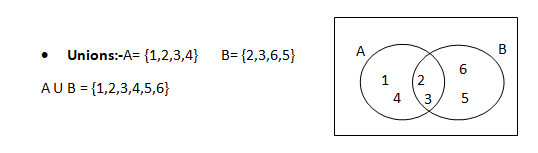
A union comprises of only unique values.
Intersection comprises of common values of the two sets
Mutually Exclusive Events:- If the occurrence of one event preludes the occurrence of the other event(s), then it is called mutually exclusive event.
P(A∩B) = 0
Independent Events:- If the occurrence or non-occurrence of an event does not have any effect on the occurrence or non-occurrence of other event(s), then it is called an independent event. For example drinking tea is independent of going for shopping.
Collectively Exhaustive Events:– A set of collectively exhaustive events comprises of all possible elementary events for an experiment. Therefore, all sample spaces are collectively exhaustive sets.
Complementary Events:– A complement of event A will be A` i.e. P(A`) = 1 ─ P(A)
Properties of probability
Probabilities are non-negative values ranging between 0 & 1.
Ω = 1 i.e. combined probability of sample is 1
If A & B are two mutually exclusive events then P(A U B)= P(A) +P(B)
Probability of not happening of an event is P(A)= 1 ─ P(A)
Rules of Counting the possibilities
The mn counting rule:- When a customer has a set of combinations to choose from like two different engines, five different paint colors and three different interior packages , how will he calculate the total number of options available to him? The answer to the question is “ mn counting rule”. Simply multiply the given options, like in our case 2 * 5 * 3 will give us 30.This means the customer has 30 combinations to choose from when it comes to purchasing a car.
Sampling from a population with replacement:- Suppose that you roll a dice three times i.e. the number of trials is 3, now if we want to check how many combinations are possible in this particular experiment we use Nn = 63 = 216
Sampling from a population without replacement:- When the sample space shrinks after each trial then you use the following formula :-
Conclusion
There is a video covering the same concept attached down the blog, go through it to be more clear about this.
In a world that is riveting towards exploring the hidden potential of emerging technologies like artificial intelligence, staying aware can not only keep you in sync but can also ensure your growth. Among all the tech terms doing the rounds now, machine learning is probably the one that you have heard frequently or, it might also be the term that intrigues you the most. You might even have a friend who is pursuing a Machine Learning course in Gurgaon. So, amidst all of this hoopla why don’t you upgrade your knowledge regarding machine learning? It’s not rocket science but, it’s science and it’s really cool!
Machine learning is a subset of AI that revolves round the concept of enabling a system to learn from the data automatically while finding patterns and improve the ability to predict without being explicitly programmed beforehand. One of the examples would be when you shop online from a particular site, you would notice product recommendations are lining up the page that particularly align with your preferences. The data footprint you leave behind is being picked up and analyzed to find a pattern and machine learning algorithms work to make predictions based on that, it is a continuous process of learning that simulate human learning process.
The same experience you would go through while watching YouTube, as it would present more videos based on your recent viewing pattern. Being such a powerful technology machine learning is gradually being implemented across different sectors and thereby pushing the demand for skilled personnel. Pursuing machine learning certification courses in gurgaon from a reputed institute, will enable an individual to pick up the nuances of machine learning to land the perfect career.
What are the different types of machine learning?
When we say machines learn, it might sound like a simple concept, but, the more you delve deeper into the topic to dissect the way it works you would know that there are more to it than meets the eyes. Machine learning could be divided into categories based on the learning aspect, here we will be focusing on 3 major categories which are namely:
Supervised Learning
Unsupervised Learning
Reinforcement Learning
Supervised Learning
Supervised learning as the name suggests involves providing the machine learning algorithm with training dataset, an example of sort to enable the system to learn to work its ways through to form the connection between input and output, the problem and the solution. The data provided for the training purposes needs to be correctly labeled so, that the algorithm is able to identify the relationship and could learn to predict output based on the input and upon finding errors could make necessary modifications. Post training when given a new dataset it should be able to analyze the input to predict a likely output for the new dataset. This basic form of machine learning is used for facial recognition, for classifying spams.
Unsupervised Learning
Again the term is suggestive like the prior category we discussed above, this is also the exact opposite of supervised learning as here there is no training data available to rely on. The input is available minus the output hence the algorithm does not have a reference to learn from. Basically the algorithm has to work its way through a big mass of unclassified data and start finding patterns on its own, due to the nature of its learning which involves parsing through unclassified data the process gets complicated yet holds potential. It basically involves clustering and association to work its way through data.
Reinforcement Learning
Reinforcement learning could be said to have similarity with the way humans learn through trial and error method. It does not have any guidance whatsoever and involves a reward, in a given situation the algorithm needs to work its way through to find the right solution to get to the reward, and it gets there by overcoming obstacles and learning from the errors along the way. The algorithm needs to analyze and find the best solution to maximize its rewards and minimize penalties as the process involves both. Video games could be an example of reinforcement learning.
Although only 3 core categories have been mentioned here, there remains other categories which deserve as much attention, such as deep learning. Deep learning too is a comparatively new field that deserves a complete discussion solely devoted to understanding this dynamic technology, focusing on its various aspects including how to be adept at deep learning for computer vision with python.
Machine learning is a highly potent technology that has the power to predict the future course of action, industries are waking up to smell the benefits that could be derived from implementation of ML. So, let’s quickly find out what some of the applications are:
Malware and spam filtering
You do not have to be tech savvy to understand what email spams are or, what malware is. Application of machine learning is refining the way emails are filtered with spams being detected and sent to a separate section, the same goes for malware detection as ML powered systems are quick to detect new malware from previous patterns.
Virtual personal assistants
As Alexa and Siri have become a part of life, we are now used to having access to our very own virtual personal assistants. However, when we ask a question or, give a command, ML starts working its magic as it gathers the data and processes it to offer a more personalized service by predicting the pattern of commands and queries.
Refined search results
When you put in a search query in Google or, any of the search engines the algorithms follow and learn from the pattern of the way you conduct a search and respond to the search results being displayed. Based on the patterns it refines the search results that impact page ranking.
Social media feeds
Whether it is Facebook or, Pinterest , the presence of machine learning could be felt across all platforms. Your friends, your interactions, your actions all of these are monitored and analyzed by machine learning algorithms to detect a pattern and prepare friend suggestions list. Automatic Friend Tagging Suggestions is another example of ML application.
Those were a couple of examples of machine learning application, but this dynamic field stretches far. The field is evolving and in the process creating new career opportunities. However, to land a job in this field one needs to have a background in Machine Learning Using Python, to become an expert and land the right job.
In the digital era we live in, nearly every transaction we do take place online and we leave a trail behind in the process which is easy to track for anyone with considerable skill in hacking. If you take a look at the state of cybercrime you are bound to feel worried because the hackers are also utilizing the latest technology and their recklessness is resulting in incidents like identity thefts.
Identity theft is increasingly becoming a threat for individuals and organizations, resulting in a huge amount of financial loss. Identity theft could occur in different ways, such as via sending fake mails which if you open can be used to grab sensitive information from the device you are using, or, via dumpster-diving methods. The problem with identity theft is that you get to learn about it much later and after losing a significant amount of money. Most of the time the amount lost cannot be recovered.
However, using machine learning techniques it is possible to overcome the shortcomings of traditional methods employed for ID theft detection and stay one step ahead to outwit the perpetrators. Machine learning has the potential to devise a smarter strategy, but, there must be professionals who have done Machine Learning training gurgaon to be able to monitor the whole process. So, let’s take a look at how machine learning can better identity theft detection process.
Authentication tests could be conducted
Machine learning could scan and cross-verify the IDs with unknown database in real-time. Using techniques like facial recognition, biometrics could actually help offer some extra support to make the process absolutely perfect. The best part of implementing machine learning technology is that there would be constant monitoring of the data. By doing so, the detection could be almost instantaneous and people could be alerted before it has a chance to snowball into something big.
Patterns get identified
Machine learning wades through tons of data to identify patterns, which could come in real handy during the process of identity theft detection. When you use your phone or laptop every day for different tasks, you do that in a set manner, but, when that device gets compromised that pattern would certainly change. While scanning data the machine learning algorithms can detect a threat by spotting an oddity and could help in taking preventive action.
Decisions could be made in real-time
Machine learning can automate the whole process of data analytics and remove the chance of human error. Machine learning also allows us to make decisions in real-time to prevent fraud or, could also send alerts, the implementation of ML can speed up the whole process thereby making it more efficient. The organizations instead of running after false alerts could actually use a solution to address a real threat without wasting a single valuable moment.
Handling big datasets
Handling a huge amount of data every single day could be an impossible task for a team comprising humans. But, the machine learning system can not only handle giant data sets, but it also thrives on data. The more datasets get fed into the system the more refined and accurate results could be expected of it. It needs data to identify the differences between genuine transactions and fraud cases.
Keeping the devices secure
Cases like identity theft could take place when devices get stolen. Now machine learning is being integrated with mobile devices to keep the devices protected from malware threats, features like biometric facial recognition are also there to ensure that the device cannot be compromised.
Application of machine learning can not only detect identity thefts but, can also prevent such attacks from happening. However, just implementation is not going to be enough, constant monitoring by a person having Machine Learning Using Python training is necessary. For some reason, if some threat goes undetected without raising any alarm the system might repeat that pattern, so monitoring is important.
A new tutorial session regarding the scikit-learn 0.22 is here and our sole focus is going to be updating your knowledge regarding the new features that have been added to this library. For this particular session we have decided to introduce you to the concept of gradient boosting that can handle the missing values. This concept is being introduced to clear out a previous misconception regarding the functioning of gradient boosting for this particular purpose.
The earlier notion surrounding GBM or, the gradient boosting algorithm in scikit-learn, was that it was unable to handle the missing values. In this tutorial we want to clarify that misconception, because, contrary to the notion XGBoost library or, XGB library is perfectly capable of handling the missing value analysis. It has been found that XGB library performs better than the normal method taken to find the missing values.
Now getting back to the scikit-learn 0.22 way of solving the issue of missing values. There has been an enhancement in the algorithm gradient boosting due to which you no longer have to handle the missing values because it will handle it of itself.
So take a look at how the concept of native support for missing values for gradient boosting works.
The ensemble algorithm, ensemble.HistGradientBoostingClassifier and ensemble.HistGradientBoostingRegressor, both classification regression now have the power of native support for missing values or, (NaNs). This is indicative of the fact that there is no need now for imputing data during training or predicting.
To gain an insight into how you perform this you need to follow the complete code sheet that you can find here
Now, as you go through the code you will find the word enable, which might surprise you and make you question why it says enable here? Well, this is because it is still being developed.
So, basically all of the algorithms in the scikit-learn 0.22 that are under development process have to run an extra line of code that goes like enable_hist_gradient_boosting. After further development there won’t be any need of that.
The video attached below will further explain how the algorithm works.
There will be more informative tutorial sessions like this, so to stay updated keep following the DexLab Analytics blog.
AI is a dynamic field that is constantly evolving thanks to the continuous stream of research work being conducted. The field is being reshaped by emerging trends. In order to keep pace with this fast-moving technology, especially if you are pursuing Data Science training you should learn about the latest trends that are going to dominate this field.
Digital Data Forgetting
It is a curious trend to watch out for as instead of learning data, unlearning would take precedence. In machine learning data is fed to the system based on which it makes predictive analysis. However, thanks to the growing channels and activities the amount of data generated is increasing, and a significant portion of which might not even be required and which only contribute to creating noise.
Although it is possible to store the data utilizing cloud-based systems, the price an organization will have to bear for unnecessary data, does not justify the decision. Furthermore, it might also raise privacy risks in the future. The efficient handling of this data lineage issue requires systems that will forget unnecessary data so that it can proceed with what is important.
NLP
Now that chatbots are being put to use to provide better customer support, the significance of NLP or, natural language processing is only going to increase. NLP is all about analyzing and processing speech patterns. There is now a shift towards developing language models around the concepts of pre-training and fine-tuning and further research work is being conducted to make these systems even more efficient, however, the focus on transfer learning might lessen considering the financial and operational complications involved in the process.
Reinforcement Learning
This is another trend to look out for, reinforcement learning is where a model or system learning involves a preset goal and is met with reward or, punishment depending upon the outcome. This particular trend might push AI to a whole new level. In RL, the learning activity is somewhat random and the system has to rely on the experience it has gained and continues to learn by repeating what it has learned, and as it starts recognizing rewards it continues working towards it until the learning takes a logical turn. Research works are being conducted to make this process more sophisticated.
Automated Machine Learning
If you are aware of Google AutoML, then you already have an inkling of what AutoML is. It basically focuses on the end-to-end process and automates it. It applies a number of techniques including RL, to reach a higher level of accuracy. It works on raw data and processes it to suggest a solution that is most appropriate. It basically is a lifesaver for those who are not familiar with ML. However, there are programs available that enable professionals pursue Machine Learning Using Python who are looking to gain expertise in this field.
Internet of Things
IOT devices are a rage and they are able to collect a huge amount of user data that needs to be processed to gather valuable information. However, there could be certain challenges involved in the data collection process which lead to error. The application of ML in this particular field can not only lend more efficiency to the way IOT operates but it can also process a large amount of data to offer actionable insight. The information filtered this way could help develop efficient models for businesses and various other sectors. The merger of IOT and ML is definitely a trend that is definitely going to be revolutionary.
AI technology is getting more sophisticated with emerging trends. The manifold application of AI is opening up new career avenues. Enrolling in a premier artificial intelligence training institute in Gurgaon, would be a good career move for anybody looking forward to having a career in this domain.
Machine learning is a subset of Artificial Intelligence, or, AI which draws from its past experiences to predict future action and act on it. The growing demand for Machine Learning course in Gurgaon, is a clear pointer to the growth the field is experiencing.
If you have been on Youtube frequently then you would certainly have noticed, how it recognizes the choices you made during your last visit and it suggests results based on those past interactions.
The world of machine learning is way past its nascent stage and has found several avenues where its application has become manifold over the years. From predictive analysis to pattern recognition systems, Machine learning is being put to use for finding an array of solutions.
AWS has been a pioneer in the field as it embraced the technology almost 20 years back, recognizing its potential growth across all business verticals.
At a recently held online tech conference, vice president of Amazon AI shared his concerns and ideas regarding the journey of ML while pointing out the hurdles still in the way and which need to be addressed. Here are the key takeaways from the discussion
Growing need for Machine learning
Amazon was quick to realize a crucial fact in the very beginning that consumer experience is a crucial aspect of business which needs to get better with the application of ML.
Despite the impressive trajectory of machine learning and its growing application across different fields there are still issues which pose serious challenge. There are certain issues which if tackled properly would pave the way for a smarter future for all.
Get your data together
Businesses intent on building a machine learning strategy need to understand that they are missing a vital component of the model which is the data itself. Setting out business objectives is not enough; machine learning model is basically built upon data. You need to feed the model data, accumulated over a period of time which it could analyze and to predict future action.
Clarity regarding machine learning application
It is understood that you need to apply machine learning in order to find solutions, to do that you need to identify that particular area of your business where you need the solution. Once you have done that, you need clarity regarding data backup, applicability and impact on business. Swami Sivasubramaniam, vice president of Amazon AI at Amazon Web Services referred to these aspects as “three dimensions”.
Another point he stressed was regarding a collaboration between domain experts and machine learning teams.
Dearth of skill
Although there has been a quantum growth in the application of machine learning, there is a significant lack of trained personnel for handling machine learning models. Undergoing a Machine Learning course in Gurgaon, could bridge the skill gap.
Since, this sector is poised to grow, people willing to make a career should consider undergoing training.
In fact, organizations looking to implement machine learning model, should send their employees for corporate training programs offered at a premier MIS Training Institute in Delhi NCR.
Avoid undifferentiated heavy lifting
Most companies tend to shift their focus from the job at hand and according to Sivasubramaniam, starts dealing with issues like “server hosting, bandwidth management, contract negotiation…”, when they should only be concerned with making the model work for their business model and should look for cloud-based solutions for handling the rest of the issues.
Addressing these issues would only pave the way towards a brighter future where Machine learning would become an integral part of every business model.
Today we are going to learn about the new feature of Scikit-learn version 0.22 called KNN Imputation. This feature now enables us to support imputation for completing missing values using k-Nearest Neighbours (KNN). To track our tutorials on other new releases from scikit-learn, read our blog here and here.
Introduction
Each sample’s missing values are imputed using the mean value from nearest neighbours found in the training set. Two samples are close if the features that are neither missing are close. By default, a Euclidean distance metric that supports missing values, nan_euclidean_distances, is used to find the nearest neighbours.
Input and Output
So, what we do first is to import libraries like NumPy and run them. Then we create as many rows as we wish to. Then we run the function KNN Imputer and we can decide how many neighbours we want. We first, as is the procedure to use scikit-learn goes, create an object and then run it. Then we can directly put the input values in imputer.fit_transform and get the output values in the form of patterns detected in the input values.
The code sheet for this tutorial is provided in a Github repository here
For more on this do watch the video attached herewith. This tutorial was brought to you by DexLab Analytics. DexLab Analytics is a premiere Machine Learning institute in Gurgaon.
Our industry experts introduce beginners to Machine Learning Algorithms with Python. In this blog, we will go through various Machine Learning Algorithms to understand the concepts better. This is the first part of a series.
Machine Learning, a subset of Artificial Intelligence, is a process of data analysis that automates analytical model building. It is a branch of artificial intelligence based on the idea that computing systems can learn from data, identify patterns in them and make intelligent decisions with minimal human intervention.
Parametric and Non-Parametric ML Algorithms
We first divide the mathematical methods for decision making in to sections – parametric and non-parametric algorithms. Parametric has a functional form while non-parametric has no functional form.
Functional form comprises a simple formula like 2+2=4 or Y=F(X). So if you input a value, you are to get a fixed output value. That means, if the data set is changed or being changed, there is not much variation in the results. But in non-parametric algorithms, a small change in data sets can result in a large change in the results.
But we do not desire this. We do not want this massive change in results in investments, for instance. We have various ways to solve this difficulty. For example, in statistics, you must have learnt the Central Limit Theorem – As the number of samples increase, the data will start following the normal distribution.
Here is an experiment on decision making with the help of non-parametric algorithm. We first take a random sample, and we apply an algorithm to it to get a result. We repeat this process several times and get an average of the results. In this way, the variation in our results goes down considerably. We will get a central tendency.
Take for example stock market data where prices are totally random. There is no fixed pattern to it. It is a manmade phenomenon. In the same way, we can make predictions in data sets only when there is a particular pattern. It becomes that much more difficult to make predictions in the absence of a clear pattern. In such a case, we take thousands of samples and work them to get a result before investing. We can use a Decision Tree like Random Forest for this.
Supervised and Unsupervised Algorithms
Now, secondly, we can term ML algorithms as supervised or unsupervised algorithms. Suppose we have data under sub-heads – Name, Age, Gender and Salary and Period of Service. Now, consider the model wherein we are asked to predict the period of service of an employee based on data provided under the rest of the sub-heads based on existing employee data.
Now, in this example, the period of service is the Target. The data sets on the basis of which the prediction will be made – Name, Age, Gender, Salary – is the Input. In such a model, where the target variable is specified, we term it as supervised machine learning algorithm. We do this according to a formula – Y=B0 + B1X1.
In unsupervised learning, the target variable is not provided and all we can do is divide the historical data in clusters. For example, Google Translate runs on a supervised model as do chatbots. Data is not only the new oil, it is everything. And there will come a time of data colonisation whereby the organisation with the best data will rule. The better the date, the better our ML models. Who has the best data sets in the world? Google and Amazon, among others, do.
So this is it, about supervised and unsupervised machine learning. For more on this, do watch our intensive video tutorial on ML algorithms.
(Translated till first 28:00 minutes)
This is the first blog of the series, stay tuned with Dexlab Analytics to read through the whole video we’ll covering in our upcoming blogs!
Today we are going to learn about the new releases from Scikit-learn version 0.22, a machine learning library in Python. We, through this video tutorial, aim to learn about the much talked about new release wherein ROC-AUC curve supports Multi Class Classification. Prior to this version, Scikit-learn did not have a function to plot the ROC curve.
To access our previous tutorial on the plotting of the ROC curve, click here.
The ROC-AUC score function can also be used in multi-class classification. Two averaging strategies are currently supported: the one-vs-one (OvO) algorithm computes the average of the pairwise ROC AUC scores and the one-vs-rest (OvR) algorithm computes the average of the ROC AUC scores for each class against all other classes.
In both cases, the multiclass ROC AUC scores are computed from probability estimates that a sample belongs to a particular class according to the model. The OvO and OvR algorithms support weighting uniformly (average=’macro’) and weighting by prevalence (average=’weighted’).
To begin with, we import multi classification, SVC and roc_auc_score. Then we specify the number of classes we want in the multi-classification function. Then we apply the SVC function and finally the roc_auc_score one. This function will give us the probable prediction for all the classes and we will then choose the one that has the highest probability. When we run it we get a ROC_AUC score of 0.99.
The code sheet is provided in a Github repository here.