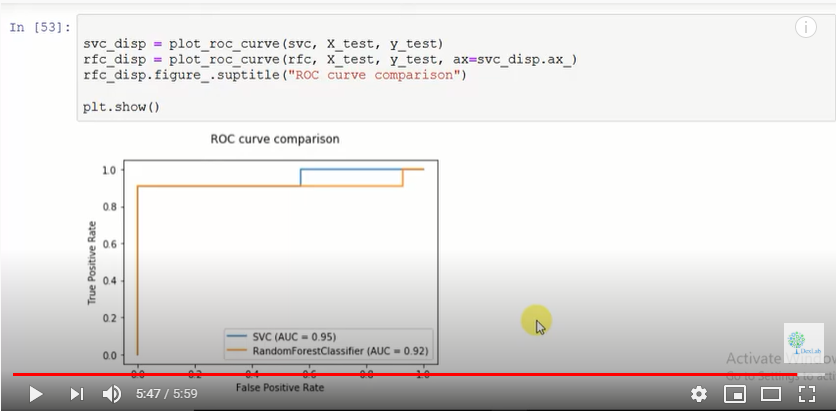
A new tutorial session regarding the scikit-learn 0.22 is here and our sole focus is going to be updating your knowledge regarding the new features that have been added to this library. For this particular session we have decided to introduce you to the concept of gradient boosting that can handle the missing values. This concept is being introduced to clear out a previous misconception regarding the functioning of gradient boosting for this particular purpose.
The earlier notion surrounding GBM or, the gradient boosting algorithm in scikit-learn, was that it was unable to handle the missing values. In this tutorial we want to clarify that misconception, because, contrary to the notion XGBoost library or, XGB library is perfectly capable of handling the missing value analysis. It has been found that XGB library performs better than the normal method taken to find the missing values.
Now getting back to the scikit-learn 0.22 way of solving the issue of missing values. There has been an enhancement in the algorithm gradient boosting due to which you no longer have to handle the missing values because it will handle it of itself.
So take a look at how the concept of native support for missing values for gradient boosting works.
The ensemble algorithm, ensemble.HistGradientBoostingClassifier and ensemble.HistGradientBoostingRegressor, both classification regression now have the power of native support for missing values or, (NaNs). This is indicative of the fact that there is no need now for imputing data during training or predicting.
To gain an insight into how you perform this you need to follow the complete code sheet that you can find here
Now, as you go through the code you will find the word enable, which might surprise you and make you question why it says enable here? Well, this is because it is still being developed.
So, basically all of the algorithms in the scikit-learn 0.22 that are under development process have to run an extra line of code that goes like enable_hist_gradient_boosting. After further development there won’t be any need of that.
The video attached below will further explain how the algorithm works.
There will be more informative tutorial sessions like this, so to stay updated keep following the DexLab Analytics blog.
Watch the video here.
.