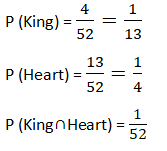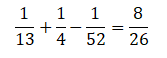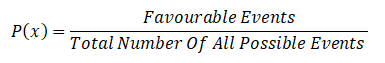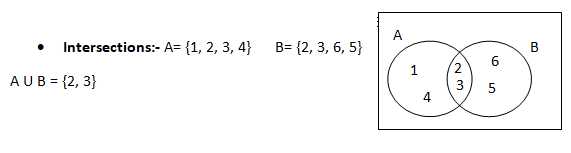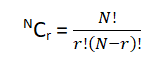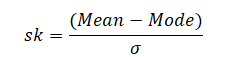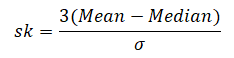Machine learning has become a popular term as this advanced technology is full of immense potential. Before explaining the intuition behind machine learning let’s understand the meaning of the term first which is becoming so popular in this era of scientific innovation and is a trend that everybody wants to follow.
What is Machine Learning?
Machine learning if explained in a very layman language is a program running behind an application which has an ability to learn from what is sees and the errors that it makes and then tries to improve itself through trial and error. A programming language like Python and a method of calculation (statistics) is what helps propel this application in the right direction.
Now that you know what machine learning is, let’s discuss about what is the intuition behind building a machine learning algorithm or a program.
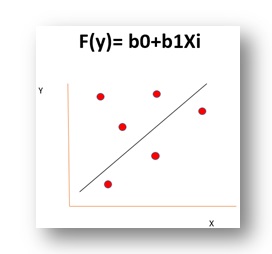
In my previous blog I have discussed about a statistical concept called Linear Regression which follows given a X independent variable, prediction of a Y dependent variable is possible if we understand the rate at which X and Y are changing and the direction towards which they are moving i.e. we understand the hidden pattern they are following, we will be able to predict the value of Y when X= 15.
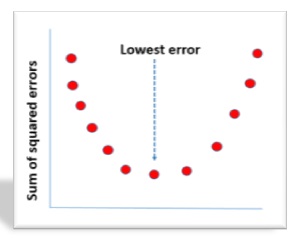
In the process of all that, we need to reduce the error between the predicted Y and the observed Y which we had to train our model but this is not possible with only calculating the slope i.e. b1 a single time and this is where machine learning comes in handy.
The idea behind machine learning is to learn from the past mistakes and try to find the best possible coefficients i.e. b0 and b1 so that we are able to reduce the distance between predicted and observed y which leads to the minimization of error in predictions which we are making. This intuition remains the same throughout all the machine learning algorithms only the problem in question and the methodology to solve the problem changes.
Now let’s quickly look at the branches of Machine Learning.
Branches of Machine Learning
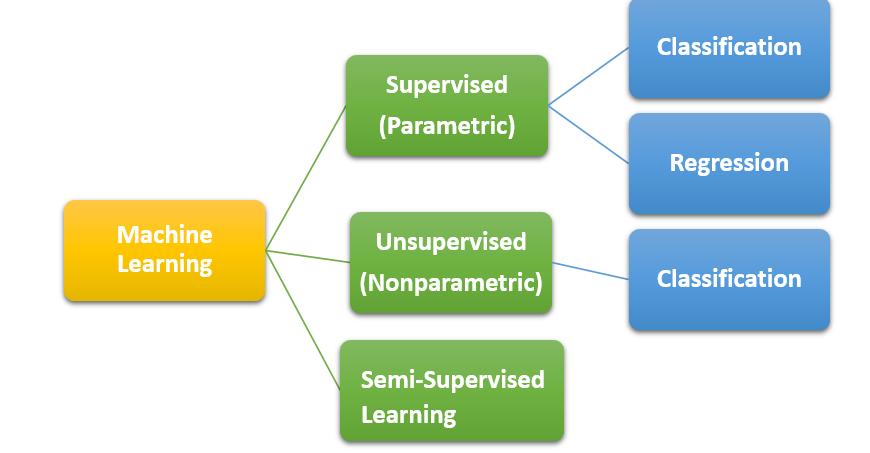
Supervised (Parametric) Machine Learning Algorithm:- Under this branch both the independent variable X and the dependent variable Y is given in the form of Y = f(X) and this branch can further be divided based on the kind of problem we are dealing with i.e. whether the variable Y is continuous or a category.
Unsupervised (Non-parametric) Machine Learning Algorithm:- Under this branch you do not have the Y variable i.e. Y ≠ f(X) and you can only solve classification problems.
Semi-Supervised Machine Learning Algorithms:- This is the most difficult to solve as under this kind of problem the data which is available for the analysis has missing values of Y which makes it quite difficult to train the algorithm as the possibility of false prediction is very high.
So, with that this discussion here on machine learning wraps up, hopefully, it helped you understand the intuition behind machine learning, also check out the video tutorial attached down the blog to learn more. The field of machine learning is full of opportunities, DexLab Analytics offers machine learning course in delhi ncr, keep on following the blog to enhance your knowledge as we continue to update it with interesting and informative posts for you.
If you are aware of the growth opportunities awaiting you in the Machine Learning domain, you must be in a rush to master the Machine Learning skills. Now, there are courses available that aim to sharpen the students with skills they would need to work in a challenging environment. However, some often prefer the self-study mode for developing knowledge in this highly specialized domain. No matter which way you prefer to learn, ultimately your passion and dedication would matter the most, because in both ways you need to put in the hard work and really toil hard to make any progress.
Is self-study a feasible option?
If you have already been through some course and want to go to the advanced level through self-study that’s a different issue, but, for those who are just starting out without any background in science, does it even make any sense to opt for self-study?
Given the way Machine Learning technology is moving fast and creating a demand for professionals with highly specialized industry knowledge, do you think self-study would be enough? Do you think a self-study plan to learn something you have no idea about would work? How much time would you need to devote? What should be your learning route? And how do you know this is the right path to follow?
Before we dive deeper into the discussion, we need to go through some prerequisites for Machine Learning study plan.
Machine learning is a broad field and assuming you are a beginner with no prior knowledge in this domain, you have to be familiar with mathematics, statistics, programming languages, meaning undergoing a Python certification training</strong>, must be proficient in data handling including analysis and modeling, you have to work on algorithms. So, can you pick up all of these skills one by one via self-study? Add to the list the latest Machine Learning tools and applications you need to grasp.
There will be help available in the form of:
There would be vast resources, in forms of e-books, lectures, video tutorials, most of these are free and easily accessible.
There are forums, groups out there which you can join and access help
You can take part in online competitions
Think it through. How long will it take for you to get from one stage to the next?
Even though there being no dearth of resources available you would be struggling with your progress and most importantly you would struggle to keep up with the pace the technology is moving ahead. Picking up a programming language, grasping and mastering concepts of linear algebra, probability, data is going to be a mammoth task.
What difference a certification course can make?
To begin with these courses are designed for people coming from different backgrounds, so, you having or, not having any prior knowledge in mathematics, statistics wouldn’t matter as you would be taught everything from scratch be it math or, Machine Learning Using Python.
The programs are designed for both working professionals as well as for beginners, all you need to do is choose the one that suits your specific level.
These courses are designed to transform you into an industry-ready professional and you would be under the guidance of professionals who are more than familiar with the nuances of the way the industry functions.
The modules would follow a strict schedule and your training path would be well planned out covering all the areas you need to master.
You would learn via hands-on training and get to handle projects. Nothing makes you skilled like hands-on training.
Your journey towards a smarter future needs to be through a well mapped-out path, so, be smart about it. DexLab Analytics offers industry-ready courses on Data Science, Machine Learning course in Gurgaon and AI with Python. Take advantage of the courses that are taught by instructors who have both expertise and experience. Time is indeed money, so, stop wasting time and get down to learning.
Artificial Intelligence or, AI is an advanced technology that is busy taking the world in its strides. With virtual assistants, face recognition, NLP, object detection, data crunching becoming familiar terms it is no wonder that this dynamic technology is being integrated into the very fabric of our society. Almost every sector is now adopting AI technology, be it running business operations or, ensuring error-free diagnosis in the healthcare domain, the exponential growth of this technology is pushing the demand for skilled AI professionals who can monitor and manage the AI operations of an organization.
Since AI is an expansive term and branches off in multiple directions, the job opportunities available in this field are also diverse. According to recent studies, AI jobs are going to be the most in-demand jobs in the near future. Multiple job roles are available that come with specific job responsibilities. So, let’s have a look at some of these.
Machine Learning Engineer
An machine learning engineer is supposed to be one of the most in-demand jobs available in this field, the basic job of an ML engineer center round working on self-running software, and they need to work with a huge pile of data. In an organization, the machine learning engineers need to collaborate with data scientists and ensure that real-time data is being put to use for churning out accurate results. They need to work with data science models and develop algorithms that can process the data and offer insight. Mostly their job responsibility revolves around working with current machine learning frameworks and working on it to make it better. Re-training machine learning models is another significant responsibility they need to shoulder.
If recent statistics are to be believed the salary of a machine learning hovers around ₹681,881 in India.
Artificial Intelligence Engineer
AI engineers are indeed a specialized breed of professionals who are in charge of AI infrastructure and work on AI models. They work on designing models and then test and finally, they need to deploy these models. Automating functionalities is also important and most importantly they must understand the key problems that need AI solutions. AI engineers need to write programs, so they need to be familiar with several programming languages, having a background in Machine Learning Using Python could be a big help. Another important responsibility is creating smart AI algorithms for developing an AI system, as per the specific requirement that needs to be solved using that system.
In India, an AI engineer could expect the salary to be around ₹7,86,105 per year, as per Glassdoor figures.
Data Scientist
A data scientist is going to be in charge of the data science team and need to work on the huge volumes of data to analyze and extract information, build and combine models and employ machine learning, data mining, techniques along with utilizing numerous tools including visualization tools to help an organization reach its business goals. The data scientists need to work with raw data and he needs to be in charge of automating the collection procedure and most importantly they need to process and prepare data for further analysis, and present the insight to the stakeholders.
A data scientist could earn around ₹ 7,41,962 per year in India as per the numbers found on Indeed.
AI Architect
An AI architect needs to work with the AI architecture and assess the current status in order to ensure that the solutions are fulfilling the current requirements and would be ready to scale up to adapt to the changing set of requirements that would arise in the future. They must be familiar with the current AI framework that they need to employ to develop an AI infrastructure that is sustainable. Along with working with a large amount of data, an AI architect must be employing machine learning algorithms and posses a thorough knowledge of the product development, and suggest suitable applications and solutions.
In India an AI architect could expect to make around ₹3,567K per year as per Glassdoor statistics is concerned.
There are so many job opportunities available in the AI domain, and here only a few job roles have been described. There are plenty more diverse job opportunities await you out there, grab those, just get artificial intelligence certification in delhi ncr and be future-ready.
Today’s workspace has turned volatile in trying to adjust to the new normal. Along with struggling to stay indoors while living a virtual life, adopting new manners of social distancing, people are also having to deal with issues like job loss, pay cut, or, worse, lack of vacancies. Different sectors are getting hit, except for those driven by cutting edge technology like Data Science, Artificial intelligence. The need to transition into a digital world is greater than ever. As per the World Economic Forum, there would be a greater push towards “digitization” as well as “automation”. This signifies the need for professionals with a background in Data Science, Artificial Intelligence in the future that is going to be entirely data-reliant.
So, what are you going to do? Sit back and wait till the storm passes over or are you going to utilize this downtime to upskill yourself with a Data Science course? With the PM stressing on how the “skill, re-skill and upskill” being the need of the hour, you can hardly afford to lose more time. Since Data Science is one of the comparatively steadier fields, that is growing despite all odds, it is time to acquire data literacy to stay relevant in a workspace that is increasingly becoming data-driven. From healthcare to manufacturing, different sectors are busy decoding the data in hand to go digital in a pandemic ridden world, and employers are looking for people who are willing to push the envelope harder to remain relevant.
What is data literacy?
Before progressing, you must understand what data literacy even means. Data literacy basically refers to having an in-depth knowledge of data that helps the employees work with data to derive actionable information from it and channelizing that to make informed decisions. However, data literacy has a wider meaning and it is not limited to the data team comprising data scientists, no, it takes all the employees in its ambit, so, that the data flow throughout the organization is seamless. Without there being employees who know their way around data, an organization can never realize its dream of initiating a data-driven culture. Having a background in Data science using Python training is the key to achieving data literacy.
The demand for data scientists and data analysts is soaring up
Despite the ominous presence of the pandemic, the demand for Data Science professionals is there and in August, the demand for Data Analysts and Data Scientists soared. As per a recent study, in India, a Data Science professional can expect no less than ₹9.5 lakh per annum. With prestigious institutes like Infosys, IBM India, Cognizant Technology Solutions, Accenture hiring, it is now absolutely mandatory to undergo Data Science training to grab the job opportunities.
Getting Data Science certification can help you close the gap
The skill gap is there, but, that does not mean it could not be taken care of. On the contrary, it is absolutely possible and imperative that you take the necessary step of upskilling yourself to be ready for the Data Science field. Having a working knowledge of data is not enough, you must be familiar with the latest Data Science tools, must possess the knowledge to work with different models, must be familiar with data extraction, data manipulation. All of these skills and more, you would need to master before you go seeking a well-paying job.
Self-study might seem like a tempting idea, but, it is not a practical solution, if you want to be industry-ready then you must know what the industry is expecting from a Data Science professional, and only a faculty comprising industry experts can give you that knowledge while guiding you through a well designed Python for data science training course.
An institute such as DexLab Analytics understands the need of the hour and has a great team of industry professionals and experts to help aspiring Data Scientists and Data Analysts fulfill their dream. Along with offering state-of-the-art Data Science certification courses, they also provide courses like Machine Learning Using Python.
No matter which way you look, upskilling is the need of the hour as the world is busy embracing the power of Data Science. Stop procrastinating and get ready for the future.
This is the second part of the probability series, in the first segment we discussed the basic concepts of probability. In this second part we will delve deeper into the topic and discuss the theorems of probability. Let’s find out what these theorems are.
Addition Theorem
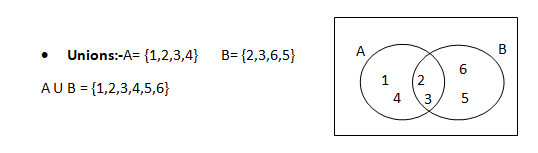
If A and B are two events and they are not necessarily mutually exclusive then the probability of occurrence of at least one of the two events A and B i.e. P(AUB) is given by
Removing the intersections will give the probability of A or B or both.
Example:- From a deck of cards 1 card is drawn, what is the probability the card is king or heart or both?
Total cards 52
P(KingUHeart)= P(King)+P(Heart) ─ P(King∩Heart)
If A and B are two mutually exclusive events then the probability that either A or B will occur is the sum of individual probabilities of the events A and B.
P(A)+P(B), here the combined probability of the two will either give P(A) or P(B)
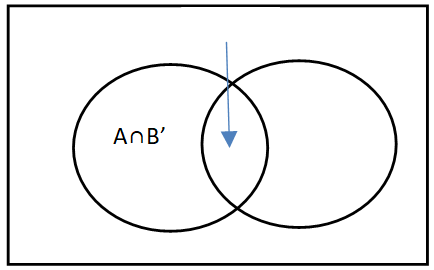
If A and B are two non mutually exclusive events then the probability of occurrence of event A is given by
Where B’ is 1-P(B), that means probability of A is calculated as P(A)=1-P(B)
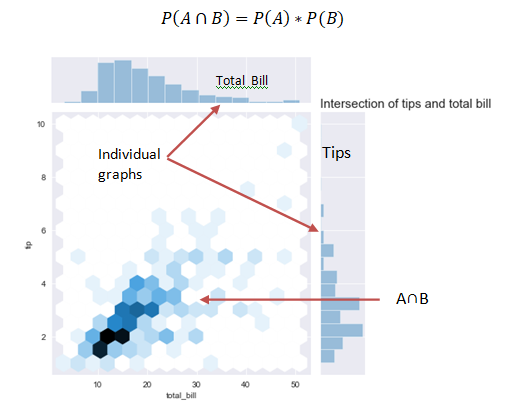
Multiplication Law
The law of multiplication is used to find the joint probability or the intersection i.e. the probability of two events occurring together at the same point of time.
In the above graph we see that when the bill is paid at the same time tip is also paid and the interaction of the two can be seen in the graph.
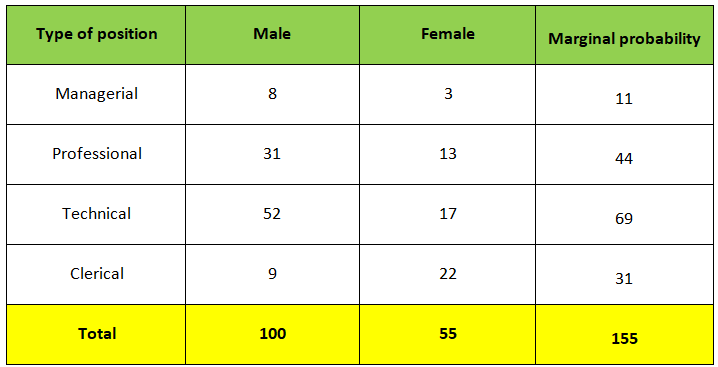
Joint probability table
A joint probability table displays the intersection (joint) probabilities along with the marginal probabilities of a given problem where the marginal probability is computed by dividing some subtotal by the whole.
Example:- Given the following joint probability table find out the probability that the employee is female or a professional worker.
Watch this video down below that further explains the theorems.
At the end of this blog, you must have grasped the basics of the theorems discussed here. Keep on tracking the Dexlab Analytics blog where you will find more discussions on topics related to Data Science training.
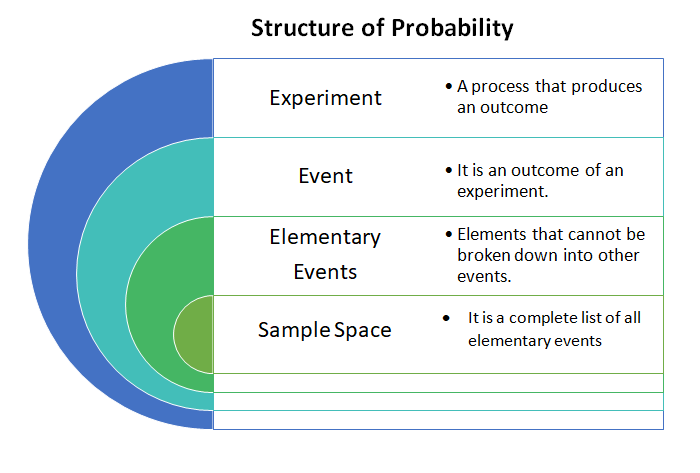
Today we will begin discussion about a significant concept, probability, which measures the likelihood of the occurrence of an event. This is the first part of the series, where you would be introduced to the core concept. So, let’s begin.
What is probability?
It is a measure of quantifying the likelihood that an event will occur and it is written as P(x).
Key concepts of probability
A union comprises of only unique values.
Intersection comprises of common values of the two sets
Mutually Exclusive Events:- If the occurrence of one event preludes the occurrence of the other event(s), then it is called mutually exclusive event.
P(A∩B) = 0
Independent Events:- If the occurrence or non-occurrence of an event does not have any effect on the occurrence or non-occurrence of other event(s), then it is called an independent event. For example drinking tea is independent of going for shopping.
Collectively Exhaustive Events:– A set of collectively exhaustive events comprises of all possible elementary events for an experiment. Therefore, all sample spaces are collectively exhaustive sets.
Complementary Events:– A complement of event A will be A` i.e. P(A`) = 1 ─ P(A)
Properties of probability
Probabilities are non-negative values ranging between 0 & 1.
Ω = 1 i.e. combined probability of sample is 1
If A & B are two mutually exclusive events then P(A U B)= P(A) +P(B)
Probability of not happening of an event is P(A)= 1 ─ P(A)
Rules of Counting the possibilities
The mn counting rule:- When a customer has a set of combinations to choose from like two different engines, five different paint colors and three different interior packages , how will he calculate the total number of options available to him? The answer to the question is “ mn counting rule”. Simply multiply the given options, like in our case 2 * 5 * 3 will give us 30.This means the customer has 30 combinations to choose from when it comes to purchasing a car.
Sampling from a population with replacement:- Suppose that you roll a dice three times i.e. the number of trials is 3, now if we want to check how many combinations are possible in this particular experiment we use Nn = 63 = 216
Sampling from a population without replacement:- When the sample space shrinks after each trial then you use the following formula :-
Conclusion
There is a video covering the same concept attached down the blog, go through it to be more clear about this.
While dealing with data distribution, Skewness and Kurtosis are the two vital concepts that you need to be aware of. Today, we will be discussing both the concepts to help your gain new perspective.
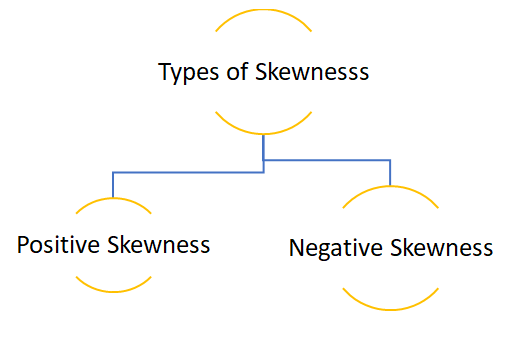
Skewness gives an idea about the shape of the distribution of your data. It helps you identify the side towards which your data is inclined. In such a case, the plot of the distribution is stretched to one side than to the other. This means in case of skewness we can say that the mean, median and mode of your dataset are not equal and does not follow the assumptions of a normally distributed curve.
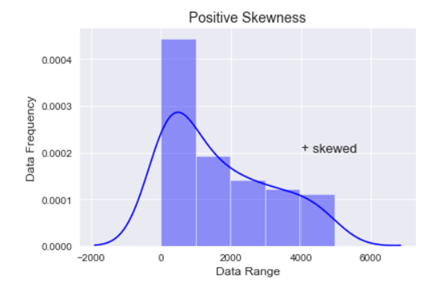
Positive skewness:- When the curve is stretched towards the right side more it is called a positively skewed curve. In this case mean is greater than median and median is the greater mode
(Mean>Median>Mode)
Let’s see how we can plot a positively skewed graph using python programming language.
First we will have to import all the necessary libraries.
Then let’s create a data using the following code:-
In the above code we first created an empty list and then created a loop where we are generating a data of 100 observations. The initial value is raised by 0.1 and then each observation is raised by the loop count.
To get a visual representation of the above data we will be using the Seaborn library and to add more attributes to our graph we will use the Matplotlib methods.
In the above graph you can see that the data is stretched towards right, hence the data is positively skewed.
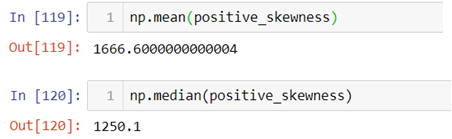
Now let’s cross validate the notion that whether Mean>Median>Mode or not.
Since each observation in the dataset is unique mode cannot be calculated.
Calculation of skewness:
Formula:-
In case we have the value of mode then skewness can be measured by Mode ─ Mean
In case mode is ill-defined then skewness can be measured by 3(Mean ─ Median)
To obtain relative measures of skewness, as in dispersion we use the following formula:-
When mode is defined:- When mode is ill-defined:-
To calculate positive skewness using Python programming language we use the following code:-
Negative skewness:- When the curve is stretched towards left side more it is called a negatively skewed curve. In this case mean is less than median and median is mode.
(Mean<Median<Mode)
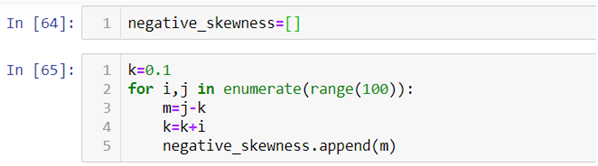
Now let’s see how we can plot a negatively skewed graph using python programming language.
Since we have already imported all the necessary libraries we can head towards generating the data.|
In the above code instead of raising the value of observation we are reducing it.
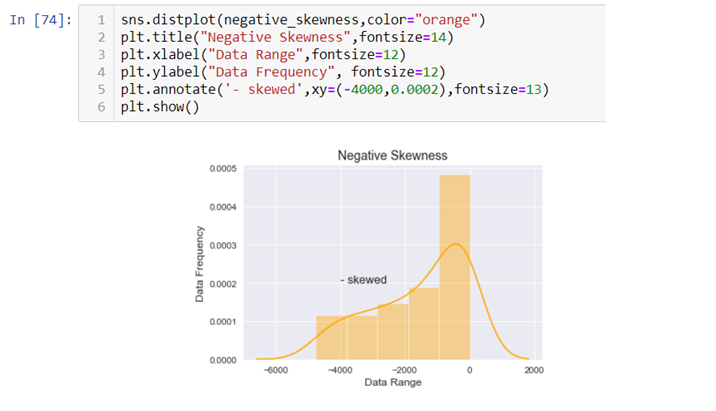
To visualize the data we have created again we will use the Seaborn and Matplotlib library.
The above graph is stretched towards left, hence it is negatively skewed.
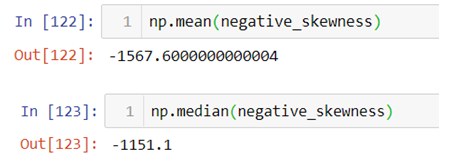
To check whether Mean<Median<Mode or not again we will be using the following code:-
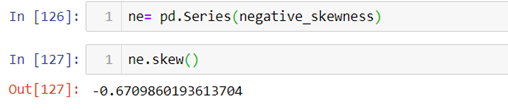
The above result shows that the value of mean is less than mode and since each observation is unique mode cannot be calculated.
Now let’s calculate skewness in Python.
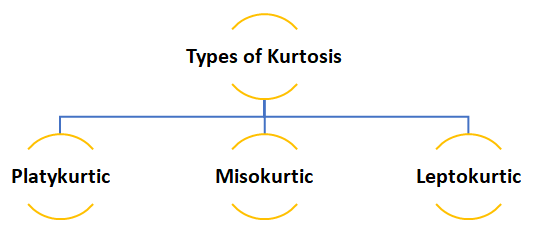
Kurtosis
Kurtosis is nothing but the flatness or the peakness of a distribution curve.
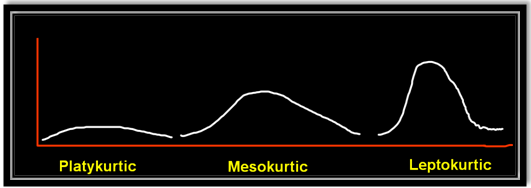
Platykurtic :- This kind of distribution has the smallest or the flattest peak.
Misokurtic:- This kind of distribution has a medium peak.
Leptokurtic:- This kind of distribution has the highest peak.
The video attached below will help you clear any query you might have.
So, this was the discussion on the Skewness and Kurtosis, at the end of this you have definitely become familiar with both concepts. Dexlab Analytics blog has informative posts on diverse topics such as neural network machine learning python which you need to explore to update yourself. Dexlab Analytics offers cutting edge courses like machine learning certification courses in gurgaon.
In a world that is riveting towards exploring the hidden potential of emerging technologies like artificial intelligence, staying aware can not only keep you in sync but can also ensure your growth. Among all the tech terms doing the rounds now, machine learning is probably the one that you have heard frequently or, it might also be the term that intrigues you the most. You might even have a friend who is pursuing a Machine Learning course in Gurgaon. So, amidst all of this hoopla why don’t you upgrade your knowledge regarding machine learning? It’s not rocket science but, it’s science and it’s really cool!
Machine learning is a subset of AI that revolves round the concept of enabling a system to learn from the data automatically while finding patterns and improve the ability to predict without being explicitly programmed beforehand. One of the examples would be when you shop online from a particular site, you would notice product recommendations are lining up the page that particularly align with your preferences. The data footprint you leave behind is being picked up and analyzed to find a pattern and machine learning algorithms work to make predictions based on that, it is a continuous process of learning that simulate human learning process.
The same experience you would go through while watching YouTube, as it would present more videos based on your recent viewing pattern. Being such a powerful technology machine learning is gradually being implemented across different sectors and thereby pushing the demand for skilled personnel. Pursuing machine learning certification courses in gurgaon from a reputed institute, will enable an individual to pick up the nuances of machine learning to land the perfect career.
What are the different types of machine learning?
When we say machines learn, it might sound like a simple concept, but, the more you delve deeper into the topic to dissect the way it works you would know that there are more to it than meets the eyes. Machine learning could be divided into categories based on the learning aspect, here we will be focusing on 3 major categories which are namely:
Supervised Learning
Unsupervised Learning
Reinforcement Learning
Supervised Learning
Supervised learning as the name suggests involves providing the machine learning algorithm with training dataset, an example of sort to enable the system to learn to work its ways through to form the connection between input and output, the problem and the solution. The data provided for the training purposes needs to be correctly labeled so, that the algorithm is able to identify the relationship and could learn to predict output based on the input and upon finding errors could make necessary modifications. Post training when given a new dataset it should be able to analyze the input to predict a likely output for the new dataset. This basic form of machine learning is used for facial recognition, for classifying spams.
Unsupervised Learning
Again the term is suggestive like the prior category we discussed above, this is also the exact opposite of supervised learning as here there is no training data available to rely on. The input is available minus the output hence the algorithm does not have a reference to learn from. Basically the algorithm has to work its way through a big mass of unclassified data and start finding patterns on its own, due to the nature of its learning which involves parsing through unclassified data the process gets complicated yet holds potential. It basically involves clustering and association to work its way through data.
Reinforcement Learning
Reinforcement learning could be said to have similarity with the way humans learn through trial and error method. It does not have any guidance whatsoever and involves a reward, in a given situation the algorithm needs to work its way through to find the right solution to get to the reward, and it gets there by overcoming obstacles and learning from the errors along the way. The algorithm needs to analyze and find the best solution to maximize its rewards and minimize penalties as the process involves both. Video games could be an example of reinforcement learning.
Although only 3 core categories have been mentioned here, there remains other categories which deserve as much attention, such as deep learning. Deep learning too is a comparatively new field that deserves a complete discussion solely devoted to understanding this dynamic technology, focusing on its various aspects including how to be adept at deep learning for computer vision with python.
Machine learning is a highly potent technology that has the power to predict the future course of action, industries are waking up to smell the benefits that could be derived from implementation of ML. So, let’s quickly find out what some of the applications are:
Malware and spam filtering
You do not have to be tech savvy to understand what email spams are or, what malware is. Application of machine learning is refining the way emails are filtered with spams being detected and sent to a separate section, the same goes for malware detection as ML powered systems are quick to detect new malware from previous patterns.
Virtual personal assistants
As Alexa and Siri have become a part of life, we are now used to having access to our very own virtual personal assistants. However, when we ask a question or, give a command, ML starts working its magic as it gathers the data and processes it to offer a more personalized service by predicting the pattern of commands and queries.
Refined search results
When you put in a search query in Google or, any of the search engines the algorithms follow and learn from the pattern of the way you conduct a search and respond to the search results being displayed. Based on the patterns it refines the search results that impact page ranking.
Social media feeds
Whether it is Facebook or, Pinterest , the presence of machine learning could be felt across all platforms. Your friends, your interactions, your actions all of these are monitored and analyzed by machine learning algorithms to detect a pattern and prepare friend suggestions list. Automatic Friend Tagging Suggestions is another example of ML application.
Those were a couple of examples of machine learning application, but this dynamic field stretches far. The field is evolving and in the process creating new career opportunities. However, to land a job in this field one needs to have a background in Machine Learning Using Python, to become an expert and land the right job.
In the digital era we live in, nearly every transaction we do take place online and we leave a trail behind in the process which is easy to track for anyone with considerable skill in hacking. If you take a look at the state of cybercrime you are bound to feel worried because the hackers are also utilizing the latest technology and their recklessness is resulting in incidents like identity thefts.
Identity theft is increasingly becoming a threat for individuals and organizations, resulting in a huge amount of financial loss. Identity theft could occur in different ways, such as via sending fake mails which if you open can be used to grab sensitive information from the device you are using, or, via dumpster-diving methods. The problem with identity theft is that you get to learn about it much later and after losing a significant amount of money. Most of the time the amount lost cannot be recovered.
However, using machine learning techniques it is possible to overcome the shortcomings of traditional methods employed for ID theft detection and stay one step ahead to outwit the perpetrators. Machine learning has the potential to devise a smarter strategy, but, there must be professionals who have done Machine Learning training gurgaon to be able to monitor the whole process. So, let’s take a look at how machine learning can better identity theft detection process.
Authentication tests could be conducted
Machine learning could scan and cross-verify the IDs with unknown database in real-time. Using techniques like facial recognition, biometrics could actually help offer some extra support to make the process absolutely perfect. The best part of implementing machine learning technology is that there would be constant monitoring of the data. By doing so, the detection could be almost instantaneous and people could be alerted before it has a chance to snowball into something big.
Patterns get identified
Machine learning wades through tons of data to identify patterns, which could come in real handy during the process of identity theft detection. When you use your phone or laptop every day for different tasks, you do that in a set manner, but, when that device gets compromised that pattern would certainly change. While scanning data the machine learning algorithms can detect a threat by spotting an oddity and could help in taking preventive action.
Decisions could be made in real-time
Machine learning can automate the whole process of data analytics and remove the chance of human error. Machine learning also allows us to make decisions in real-time to prevent fraud or, could also send alerts, the implementation of ML can speed up the whole process thereby making it more efficient. The organizations instead of running after false alerts could actually use a solution to address a real threat without wasting a single valuable moment.
Handling big datasets
Handling a huge amount of data every single day could be an impossible task for a team comprising humans. But, the machine learning system can not only handle giant data sets, but it also thrives on data. The more datasets get fed into the system the more refined and accurate results could be expected of it. It needs data to identify the differences between genuine transactions and fraud cases.
Keeping the devices secure
Cases like identity theft could take place when devices get stolen. Now machine learning is being integrated with mobile devices to keep the devices protected from malware threats, features like biometric facial recognition are also there to ensure that the device cannot be compromised.
Application of machine learning can not only detect identity thefts but, can also prevent such attacks from happening. However, just implementation is not going to be enough, constant monitoring by a person having Machine Learning Using Python training is necessary. For some reason, if some threat goes undetected without raising any alarm the system might repeat that pattern, so monitoring is important.

 Machine learning if explained in a very layman language is a program running behind an application which has an ability to learn from what is sees and the errors that it makes and then tries to improve itself through trial and error. A programming language like Python and a method of calculation (statistics) is what helps propel this application in the right direction.
Machine learning if explained in a very layman language is a program running behind an application which has an ability to learn from what is sees and the errors that it makes and then tries to improve itself through trial and error. A programming language like Python and a method of calculation (statistics) is what helps propel this application in the right direction.