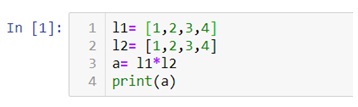
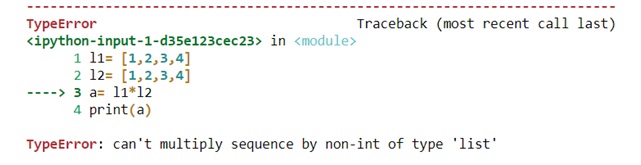
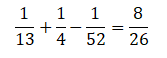MongoDB is a document based database program which was developed by MongoDB Inc. and is licensed under server side public license (SSPL). It can be used across platforms and is a non-relational database also known as NoSQL, where NoSQL means that the data is not stored in the conventional tabular format and is used for unstructured data as compared to SQL and that is the major difference between NoSQL and SQL.
MongoDB stores document in JSON or BSON format. JSON also known as JavaScript Object notation is a format where data is stored in a key value pair or array format which is readable for a normal human being whereas BSON is nothing but the JSON file encoded in the binary format which is quite hard for a human being to understand.
Structure of MongoDB which uses a query language MQL(Mongodb query language):-
Databases:- Databases is a group of collections.
Collections:- Collection is a group fields.
Fields:- Fields are nothing but key value pairs
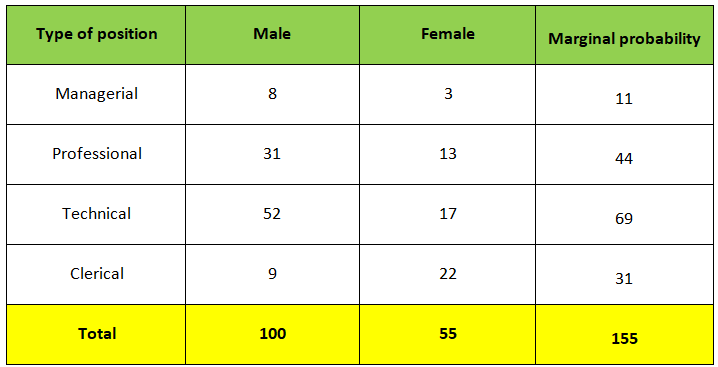
Just for an example look at the image given below:-
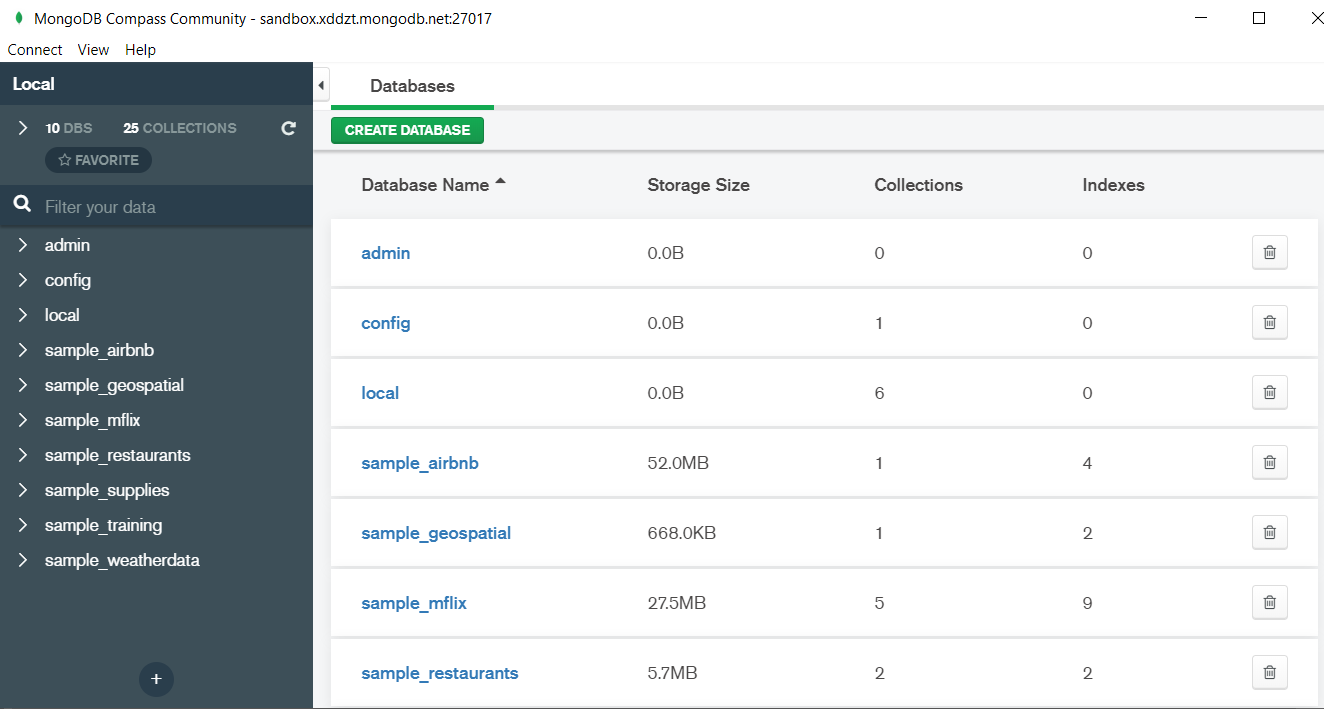
Here I am using MongoDB Compass a tool to connect to Atlas which is a cloud based platform which can help us write our queries and start performing all sort of data extraction and deployment techniques. You can download MongoDB Compass via the given link https://www.mongodb.com/try/download/compass
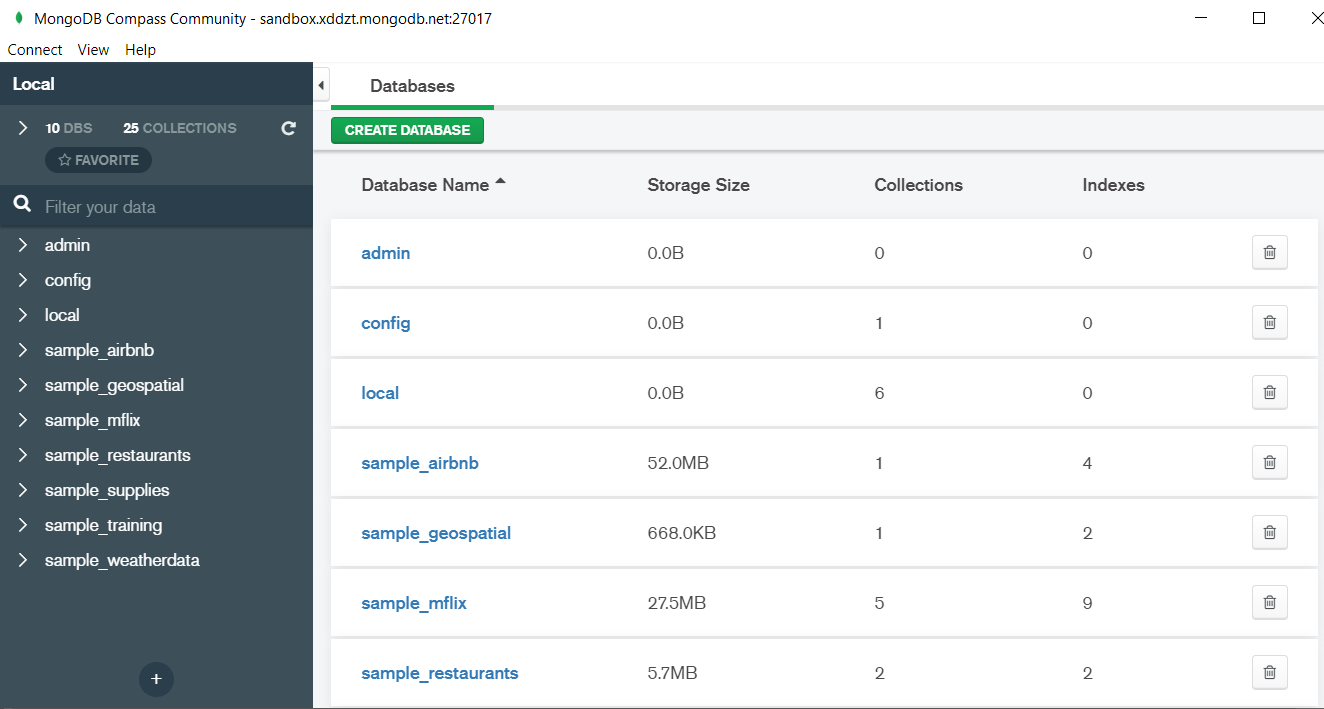
In the above image in the red box we have our databases and if we click on the “sample_training” database we will see a list of collections similar to the tables in sql.
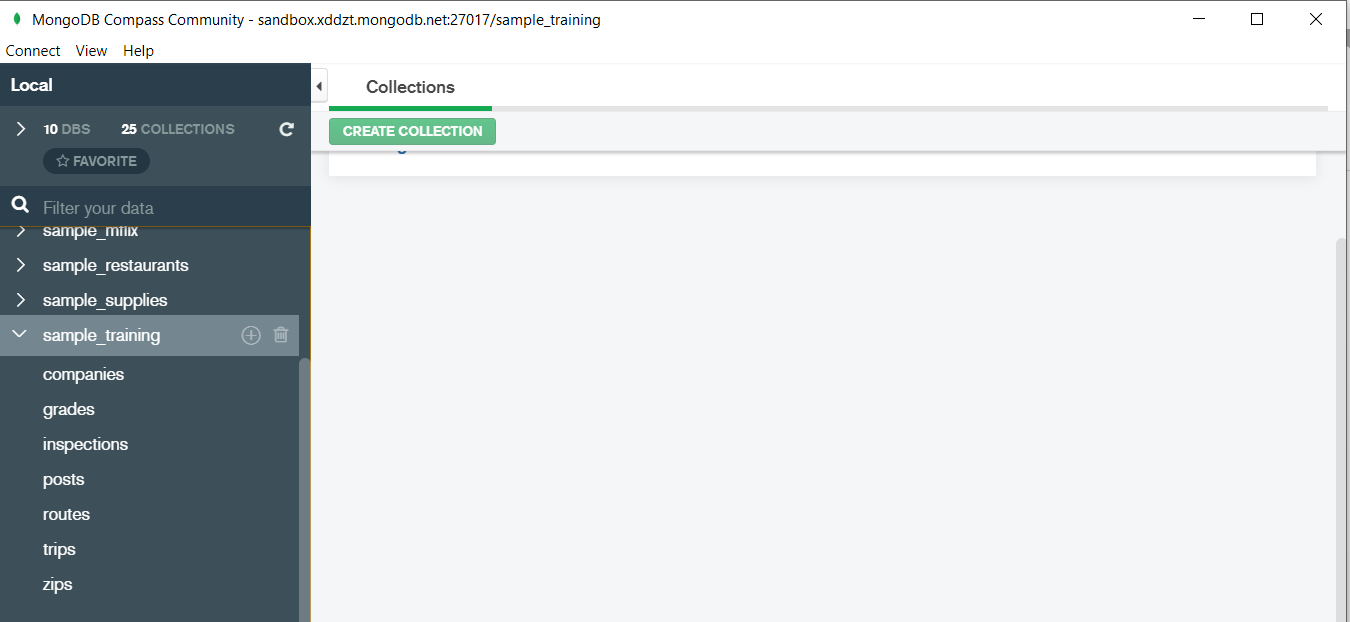
Now lets write our first query and see what data in “companies” collection looks like but before that select the “companies” collection.
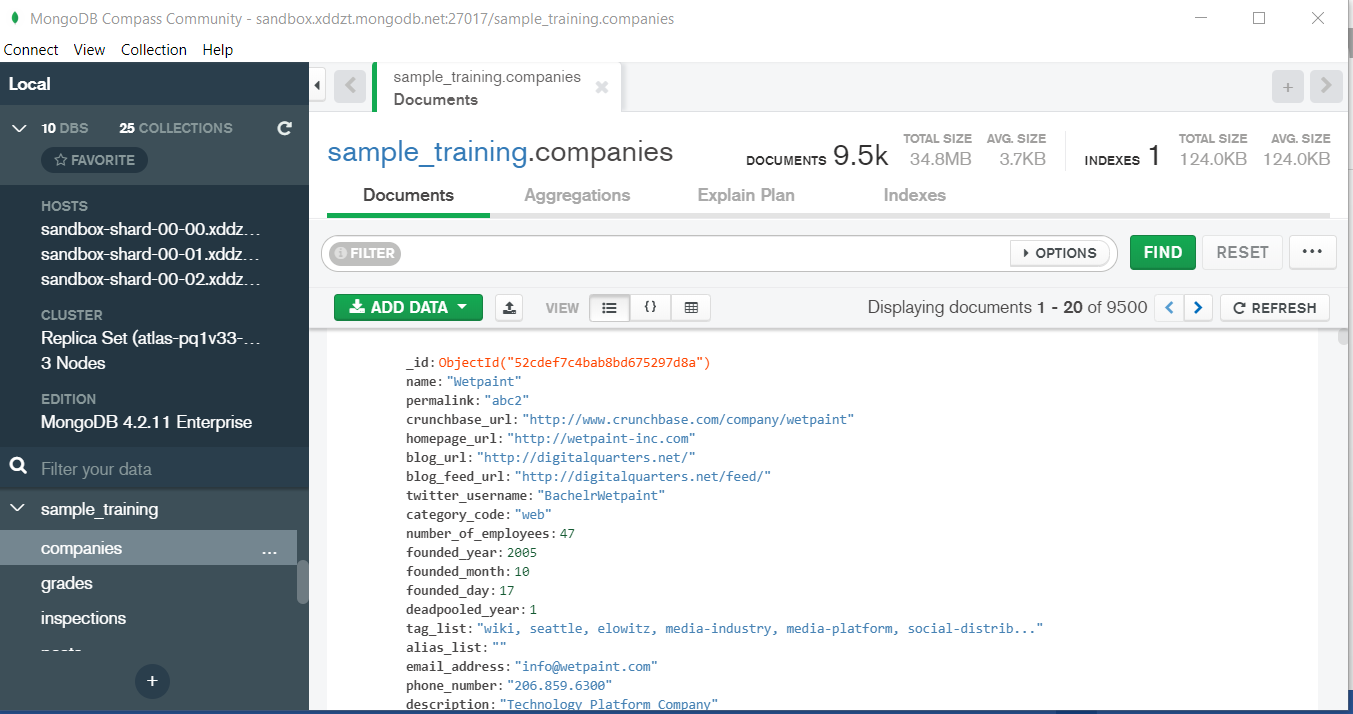
Now in our filter cell we can write the following query:-
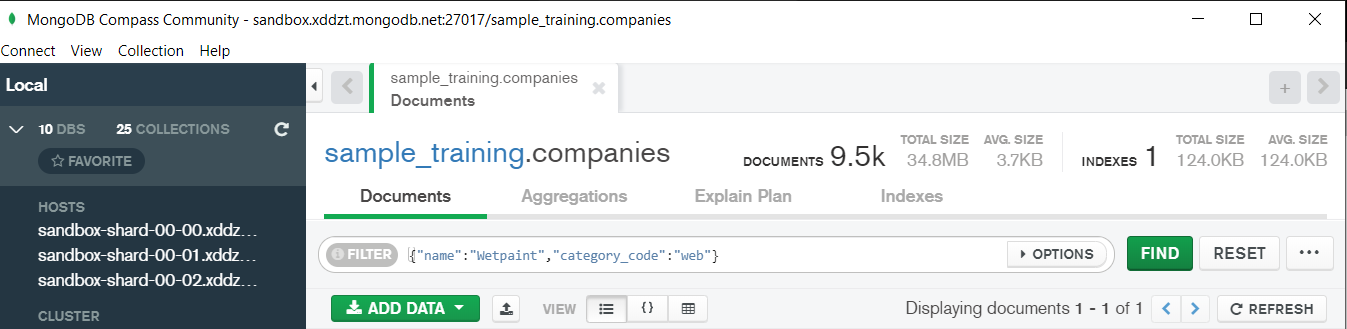
In the above query “name” and “category_code” are the key values also known as fields and “Wetpaint” and “web” are the pair values on the basis of which we want to filter the data.
What is cluster and how to create it on Atlas?
MongoDB cluster also know as sharded cluster is created where each collection is divided into shards (small portions of the original data) which is a replica set of the original collection. In case you want to use Atlas there is an unpaid version available with approximately 512 mb space which is free to use. There is a pre-existing cluster in MongoDB named Sandbox , which currently I am using and you can use it too by following the given steps:-
1. Create a free account or sign in using your Google account on
https://www.mongodb.com/cloud/atlas/lp/try2-in?utm_source=google&utm_campaign=gs_apac_india_search_brand_atlas_desktop&utm_term=mongodb%20atlas&utm_medium=cpc_paid_search&utm_ad=e&utm_ad_campaign_id=6501677905&gclid=CjwKCAiAr6-ABhAfEiwADO4sfaMDS6YRyBKaciG97RoCgBimOEq9jU2E5N4Jc4ErkuJXYcVpPd47-xoCkL8QAvD_BwE
2. Click on “Create an Organization”.
3. Write the organization name “MDBU”.
4. Click on “Create Organization”.
5. Click on “New Project”.
6. Name your project M001 and click “Next”.
7. Click on “Build a Cluster”.
8. Click on “Create a Cluster” an option under which free is written.
9. Click on the region closest to you and at the bottom change the name of the cluster to “Sandbox”.
10. Now click on connect and click on “Allow access from anywhere”.
11. Create a Database User and then click on “Create Database User”.
username: m001-student
password: m001-mongodb-basics
12. Click on “Close” and now load your sample as given below :
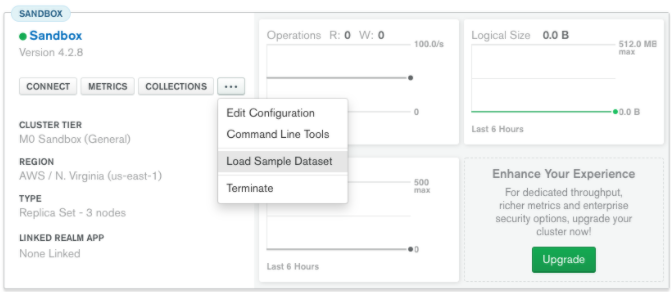
Loading may take a while….
13. Click on collections once the sample is loaded and now you can start using the filter option in a similar way as in MongoDB Compass
In my next blog I’ll be sharing with you how to connect Atlas with MongoDB Compass and we will also learn few ways in which we can write query using MQL.
So, with that we come to the end of the discussion on the MongoDB. Hopefully it helped you understand the topic, for more information you can also watch the video tutorial attached down this blog. The blog is designed and prepared by Niharika Rai, Analytics Consultant, DexLab Analytics DexLab Analytics offers machine learning courses in Gurgaon. To keep on learning more, follow DexLab Analytics blog.
.