The latest research work in the field of image recognition led to the development of a new activation function for visual recognition tasks, namely Funnel activation(FReLU). In this research ReLU and PReLU are extended to a 2D activation by adding a negligible overhead of spatial condition. Experiments on ImageNet, COCO detection, and semantic segmentation tasks are conducted to measure the performance of FReLU.
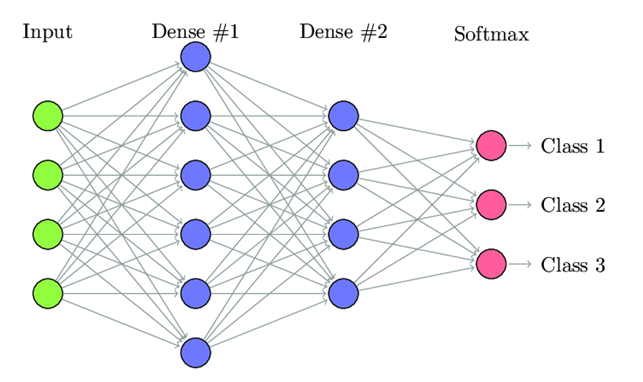
CNNs have shown advanced performances in many visual recognition tasks, such as image classification, object detection, and semantic segmentation. In a CNN framework, basically two major kind of layers play crucial roles, the convolution layer and the non-linear activation layer. Both the convolution layers and activation layers perform distinct functions, however, in both layers there are challenges regarding capturing the spatial dependency. However, despite advancements achieved by complex convolutions, improving the performance of visual tasks is still challenging which results in Rectified Linear Unit (ReLU) being the most widely used function till date.
The research focused on two distinct queries
- Could regular convolutions achieve similar accuracy, to grasp the challenging complex images?
2. Could we design an activation specifically for visual tasks?
1. Effectiveness and generalization performance
In a bid to find answers to these questions, researchers identified spatially insensitiveness in activations to be the main impending factor that prevent visual tasks from improving further.
To address this issue they proposed to find a new visual activation task that could be effective in removing this obstacle and be a better alternative to previous activation approaches.
How other activations work
Taking a look at other activations such as Scalar activations, Contextual conditional activations helps in understanding the context better.
Scalar activations basically are concerned with single input and output which could be represented in form of y = f(x). ReLU or, the Rectified Linear Unit is a widely used activation that is used for various tasks and could be represented as y = max(x, 0).
Contextual conditional activations work on the basis of many-to-one function. In this process neurons that are conditioned on contextual information are activated.
Spatial dependency modeling
In order to accumulate the various ranges of spatial dependences, some approaches utilize various shapes of convolution kernels which leads to lesser efficiency. In other methods like STN, spatial transformations are adaptively used for refining short-range dependencies for the dense vision tasks.
FReLU differs from all other methods in the sense that it performs better without involving complex convolutions. FReLU addresses the issues and solves with a higher level of efficiency.
Receptive field: How FReLU differs from other methods regarding the Receptive field
The size as well as the region of the receptive field play a crucial role in vision recognition tasks. The pixel contribution can be unequal. In order to implement the adaptive receptive field and for a better performance, many methods resort to complex convolutions. FReLU differs from such methods in the way that it achieves the same goal with regular convolutions in a more simple yet highly efficient manner.
Funnel Activation: how funnel activation works
FReLU being conceptually simple is designed for visual tasks. The research further delves into reviewing the ReLU activation and PReLU which is an advanced variant of ReLU, moving on to the key elements of FReLU the funnel condition and the pixel-wise modeling capacity, both of which are not found in ReLU or, in any of its variants.
2. Funnel activation
Funnel condition
Here the same max(·) is adopted as the simple non-linear function, when it comes to the condition part it gets extended to be a 2D condition which is dependent on the spatial context for individual pixel. For the implementation of the spatial condition, Parametric Pooling Window is used for creating dependency.
Pixel-wise modeling capacity
Due to the funnel condition the network is capable of generating spatial conditions in the non-linear activations for each pixel. This differs from usual methods where spatial dependency is created in the convolution layer and non-linear transformations are conducted separately. This model achieves a pixel-wise modeling capacity thereby extraction of spatial structure of objects could be addressed naturally.
Experiments
Evaluation of the activation is tested via experiments on ImageNet 2012 classification dataset[9,37].The evaluation is done in stages starting with different sizes of ResNet. Comparisons with scalar activations is done on ResNets with varying depths, followed by Comparison on light-weight CNNs. An object detection experiment is done to evaluate the generalization performance on various tasks on COCO dataset containing 80 object categories. Further comparison is also done on semantic segmentation task in CityScape dataset. Difference of the images could be perceived through the CityScape images.

4. Visualization of semantic segmentation
Funnel activation: ablation studies
The scope of the visual activation is tested further via ablation studies where each component of the activation namely 1) funnel condition, and 2)max(·) non-linearity are individually examined. The three parts of the investigation are as follows Ablation on the spatial condition, Ablation on the non-linearity, Ablation on the window size
Compatibility with Existing Methods
Before the new activation could be adopted into the convolutional networks, layers and stages need to be decided, the compatibility with other existing approaches such as SENet also was tested. The process took place in stages as follows
Compatibility with different convolution layers
Compatibility with different stages
Compatibility with SENet
Conclusion: Post all the investigations done to test out the compatibility of FReLU on different levels, it could be stated that this funnel activation is simple yet highly effective and specifically developed for visual tasks. Its pixel-wise modeling capacity is able to grasp even complex layouts easily. But further research work could be done to expand its scope as it definitely has huge potential.
To get in-depth knowledge regarding the various stages of the research work on Funnel Activation for Visual Recognition, check https://arxiv.org/abs/2007.11824.
.