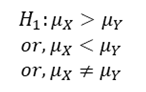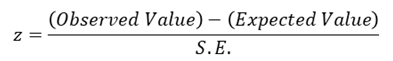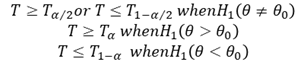Among all the decisions we make in our lives, choosing the right career path seems to be the most crucial one. Except for a couple of clueless souls, most students know by the time they clear their boards what they aspire to be. A big chunk of them veer towards engineering, MBA, even pursue masters degree in academics and post completion of their studies they settle for relevant jobs. So far that used to be the happily ever after career story, but, in the last couple of years there seems to be a big paradigm shift and it is causing a stir across industries. Professionals having an engineering background, or, masters degree are opting for a mid-career switch and a majority of them are opting for the data science domain by pursuing a Data Science course. So, what’s pushing them towards DS? Let’s investigate.
What’s causing the career switch?
No matter which field someone has chosen for career, achieving stability is a common goal. However, in many fields be it engineering, or, something else the job opportunities are not unlimited yet the number of job seekers is growing every year. So, thereby one can expect to face a stiff competition grabbing a well-paid job.
There have been many layoffs in recent times especially due to the unprecedented situation the world is going through. Even before that there were reports of job cuts and certain sectors not doing well would directly impact the career of thousands. Even if we do not concentrate on the extremes, the growth prospect in most places could be limited and achieving the desired salary or, promotion oftentimes becomes impossible. This leads to not only frustration but uncertainty as well.
The demand for big data
If you haven’t been living as a hermit, then you are aware of the data explosion that impacted nearly every industry. The moment everyone understood the power of big data they started investing in research and in building a system that can handle, store and process data which is a storehouse of information. Now, who is going to process data to extract the information? And here comes the new breed of data experts, namely the data scientists, who have mastered the technology having undergone Data Science training and are able to develop models and parse through data to deliver the insights companies are looking for to make informed decisions. The data trend is pushing the boundaries and as cutting edge technologies like AI, machine learning are percolating every aspect of the industries, the demand for avant-garde courses like natural language processing course in gurgaon, is skyrocketing.
Lack of trained industry ready data science professionals
Although big data has started trending as businesses started gathering data from multiple sources, there are not many professionals available to handle the data. The trend is only gaining momentum and if you just check the top job portals such as Glassdoor, Indeed and go through the ads seeking data scientists you would immediately know how far the field has traveled. With more and more industries turning to big data, the demand for qualified data scientists is shooting up.
Why data science is being chosen as the best option?
In the 21st century data science is a field which has plethora of opportunities for the right people and this is one field which is not only growing now but is also poised to grow in future as well. The data scientist is one of the most highest paid professional in today’s job market. According to the U.S. Bureau of Labor Statistics report by the year 2026 there is a possibility of creation of 11.5 million jobs in this field.
Now take a look at the Indian context, from agriculture to aviation the demand for data scientists would continue to grow as there is a severe shortage of professionals. As per a report the salary of a data scientist could hover around ₹1,052K per annum and remember the field is growing which means there is not going to be a dearth of job opportunities or, lucrative pay packages.
The shift
Considering all of these factors there has been a conscious shift in the mindset of the professionals, who are indeed making a beeline for institutes that offer data science certification. By doing so they hope to-
Access promising career opportunities
Achieve job satisfaction and financial stability
Earn more while enjoying job security
Work across industries and also be recruited by industry biggies
Gain valuable experience to be in demand for the rest of their career
Be a part of a domain that promises innovation and evolution instead of stagnation
Keeping in mind the growing demand for professionals and the dearth of trained personnel, premier institutes like DexLab Analytics have designed courses that are aimed to build industry-ready professionals. The best thing about such courses is that you can hail from any academic background, here you will be taught from scratch so that you can grasp the fundamentals before moving on to sophisticated modules.
Along with providing data science certification training, they also offer cutting edge courses such as, artificial intelligence certification in delhi ncr, Machine Learning training gurgaon. Such courses enable the professionals enhance their skillset to make their mark in a world which is being dominated by big data and AI. The faculty consists of skilled professionals who are armed with industry knowledge and hence are in a better position to shape students as per industry demands and standards.
The mid-career switch is happening and will continue to happen. There must be professionals who have the expertise to drive an organization towards the future by unlocking their data secrets. However, something must be kept in mind if you are considering a switch, you need to be ready to meet challenges, along with knowledge of Python for data science training, you need to have a vision, a hunger and a love for data to be a successful data scientist.
In this series we cover the basic of statistical inference, this is the fourth part of our discussion where we explain the concept of hypothesis testing which is a statistical technique. You could also check out the 3rd part of the series here.
Introduction
The objective of sampling is to study the features of the population on the basis of sample observations. A carefully selected sample is expected to reveal these features, and hence we shall infer about the population from a statistical analysis of the sample. This process is known as Statistical Inference.
There are two types of problems. Firstly, we may have no information at all about some characteristics of the population, especially the values of the parameters involved in the distribution, and it is required to obtain estimates of these parameters. This is the problem of Estimation. Secondly, some information or hypothetical values of the parameters may be available, and it is required to test how far the hypothesis is tenable in the light of the information provided by the sample. This is the problem of Test of Hypothesis or Test of Significance.
In many practical problems, statisticians are called upon to make decisions about a population on the basis of sample observations. For example, given a random sample, it may be required to decide whether the population, from which the sample has been obtained, is a normal distribution with mean = 40 and s.d. = 3 or not. In attempting to reach such decisions, it is necessary to make certain assumptions or guesses about the characteristics of population, particularly about the probability distribution or the values of its parameters. Such an assumption or statement about the population is called Statistical Hypothesis. The validity of a hypothesis will be tested by analyzing the sample. The procedure which enables us to decide whether a certain hypothesis is true or not, is called Test of Significance or Test of Hypothesis.
What Is Testing Of Hypothesis?
Statistical Hypothesis
Hypothesis is a statistical statement or a conjecture about the value of a parameter. The basic hypothesis being tested is called the null hypothesis. It is sometimes regarded as representing the current state of knowledge & belief about the value being tested. In a test the null hypothesis is constructed with alternative hypothesis denoted by 𝐻1 ,when a hypothesis is completely specified then it is called a simple hypothesis, when all factors of a distribution are not known then the hypothesis is known as a composite hypothesis.
Testing Of Hypothesis
The entire process of statistical inference is mainly inductive in nature, i.e., it is based on deciding the characteristics of the population on the basis of sample study. Such a decision always involves an element of risk i.e., the risk of taking wrong decisions. It is here that modern theory of probability plays a vital role & the statistical technique that helps us at arriving at the criterion for such decision is known as the testing of hypothesis.
Testing Of Statistical Hypothesis
A test of a statistical hypothesis is a two action decision after observing a random sample from the given population. The two action being the acceptance or rejection of hypothesis under consideration. Therefore a test is a rule which divides the entire sample space into two subsets.
A region is which the data is consistent with 𝐻0.
The second is its complement in which the data is inconsistent with 𝐻0.
The actual decision is however based on the values of the suitable functions of the data, the test statistic. The set of all possible values of a test statistic which is consistent with 𝐻0 is the acceptance region and all these values of the test statistic which is inconsistent with 𝐻0 is called the critical region. One important condition that must be kept in mind for efficient working of a test statistic is that the distribution must be specified.
Does the acceptance of a statistical hypothesis necessarily imply that it is true?
The truth a fallacy of a statistical hypothesis is based on the information contained in the sample. The rejection or the acceptance of the hypothesis is contingent on the consistency or inconsistency of the 𝐻0 with the sample observations. Therefore it should be clearly bowed in mind that the acceptance of a statistical hypothesis is due to the insufficient evidence provided by the sample to reject it & it doesn’t necessarily imply that it is true.
Elements: Null Hypothesis, Alternative Hypothesis, Pot
Null Hypothesis
A Null hypothesis is a hypothesis that says there is no statistical significance between the two variables in the hypothesis. There is no difference between certain characteristics of a population. It is denoted by the symbol 𝐻0. For example, the null hypothesis may be that the population mean is 40 then
𝐻0(𝜇 = 40)
Let us suppose that two different concerns manufacture drugs for including sleep, drug A manufactured by first concern and drug B manufactured by second concern. Each company claims that its drug is superior to that of the other and it is desired to test which is a superior drug A or B? To formulate the statistical hypothesis let X be a random variable which denotes the additional hours of sleep gained by an individual when drug A is given and let the random variable Y denote the additional hours to sleep gained when drug B is used. Let us suppose that X and Y follow the probability distributions with means 𝜇𝑥 and 𝜇𝑌 respectively.
Here our null hypothesis would be that there is no difference between the effects of two drugs. Symbolically,
𝐻0: 𝜇𝑋 = 𝜇𝑌
Alternative Hypothesis
A statistical hypothesis which differs from the null hypothesis is called an Alternative Hypothesis, and is denoted by 𝐻1. The alternative hypothesis is not tested, but its acceptance (rejection) depends on the rejection (acceptance) of the null hypothesis. Alternative hypothesis contradicts the null hypothesis. The choice of an appropriate critical region depends on the type of alternative hypothesis, whether both-sided, one-sided (right/left) or specified alternative.
Alternative hypothesis is usually denoted by 𝐻1.
For example, in the drugs problem, the alternative hypothesis could be
Power Of Test
The null hypothesis 𝐻0 𝜃 = 𝜃0 is accepted when the observed value of test statistic lies the critical region, as determined by the test procedure. Suppose that the true value of 𝜃 is not 𝜃0, but another value 𝜃1, i.e. a specified alternative hypothesis 𝐻1 𝜃 = 𝜃1 is true. Type II error is committed if 𝐻0 is not rejected, i.e. the test statistic lies outside the critical region. Hence the probability of Type II error is a function of 𝜃1, because now 𝜃 = 𝜃1 is assumed to be true. If 𝛽 𝜃1 denotes the probability of Type II error, when 𝜃 = 𝜃1 is true, the complementary probability 1 − 𝛽 𝜃1 is called power of the test against the specified alternative 𝐻1 𝜃 = 𝜃1 . Power = 1-Probability of Type II error=Probability of rejection 𝐻0 when 𝐻1 is true Obviously, we could like a test to be as ‘powerful’ as possible for all critical regions of the same size. Treated as a function of 𝜃, the expression of 𝑃 𝜃 = 1 − 𝛽 𝜃 is called Power Function of the test for 𝜃0 against 𝜃. the curve obtained by plotting P(𝜃) against all possible values of 𝜃, is known as Power Curve.
Elements: Type I & Type II Error
Type I Error & Type Ii Error
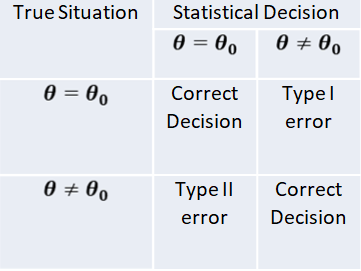
The procedure of testing statistical hypothesis does not guarantee that all decisions are perfectly accurate. At times, the test may lead to erroneous conclusions. This is so, because the decision is taken on the basis of sample values, which are themselves fluctuating and depend purely on chance. The errors in statistical decisions are two types:
Type I Error – This is the error committed by the test in rejecting a true null hypothesis.
Type II Error – This is the error committed by the test in accepting a false null hypothesis.
Considering for the population mean is 40, i.e. 𝐻0 𝜇 = 40 , let us imagine that we have a random sample from a population whose mean is really 40. if we apply the test for 𝐻0 𝜇 = 40 , we might find that the values of test statistic lines in the critical region, thereby leading to the conclusion that the population mean is not 40; i.e. the test rejects the null hypothesis although it is true. We have thus committed what is known as “Type I error” or “Error of first kind”. On the other hand, suppose that we have a random sample from a population whose mean is known to different from 40, say 43. if we apply the test for 𝐻0 𝜇 = 40 , the value of the statistic may, by chance, lie in the acceptance region, leading to the conclusion that the mean may be 40; i.e. the test does not reject the null hypothesis 𝐻0 𝜇 = 40 , although it is false. This is again another form of incorrect decision, and the error thus committed is known as “Type II error” or “Error of second kind”.
Using sampling distribution of the test statistic, we can measure in advance the probabilities of committing the two types of error. Since the null hypothesis is rejected only when the test statistic falls in the critical region.
Probability of Type I error = Probability of rejecting 𝐻0 𝜃 = 𝜃0 , when it is true = Probability that the test statistic lies in the critical region, assuming 𝜃 = 𝜃0.
The probability of Type I error must not exceed the level of significance (𝛼) of the test.
The probability of Type II error assumes different values for different values of 𝜃 covered by the alternative hypothesis 𝐻1. Since the null hypothesis is accepted only when the observed value of the best statistic lies outside the critical region.
Probability of Type II error 𝑊ℎ𝑒𝑛 𝜃 = 𝜃1 = Probability of accepting 𝐻0 𝜃 = 𝜃0 , when it is false = Probability that the test statistic lies in the region of acceptance, assuming 𝜃 = 𝜃1
The probability of Type I error is necessary for constructing a test of significance. It is in fact the ‘size of the Critical Region’. The probability of Type II error is used to measure the “power” of the test in detecting falsity of the null hypothesis. When the population has a continuous distribution
Probability of Type I error = Level of significance = Size of critical region
Elements: Level Of Significance & Critical Region
Level Of Significance And Critical Region
The decision about rejection or otherwise of the null hypothesis is based on probability considerations. Assuming the null hypothesis to be true, we calculate the probability of obtaining a difference equal to or greater than the observed difference. If this probability is found to be small, say less than .05, the conclusion is that the observed value of the statistic is rather unusual and has been caused due to the underlying assumption (i.e. null hypothesis) that is not true. We say that the observed difference is significant at 5 per cent level, and hence the ‘null hypothesis is rejected’ at 5 per cent level of significance. If, however, this probability is not very small, say more than .05, the observed difference cannot be considered to be unusual and is attributed to sampling fluctuation only. The difference is, now said to be not significant at 5 per cent level, and we conclude that there is no reason to reject the null hypothesis’ at 5 per cent level of significance. It has become customary to use 5% and 1% level of significance, although other levels, such as 2% or 5% may also be used.
Without actually going to calculate this probability, the test of significance may be simplified as follows. From the sampling distribution of the statistic, we find the maximum difference is which is exceeded in (say 5) percent of cases. If the observed difference in larger than this value, the null hypothesis is rejected. It is less there in no reason to reject the null hypothesis.
Suppose, the sampling distribution of the statistic is a normal distribution. Since the area under normal curve outside the ordinates at mean ±1.96 (𝑠. 𝑑. ) is only 5%, the probability that the observed value of the statistic differs from the expected value of 1.96 times the S.E. or more is .05; and the probability of a larger difference will be still smaller. If, therefore
Is either greater than 1.96 or less than -1.96 (i.e. numerically greater than 1.96), the null hypothesis 𝐻0 is rejected at 5% level of significance. The set values 𝑧 ≥ 1.96 𝑜𝑟 ≤ −1.96, i.e.
|𝑧| ≥ 1.96
constitutes what is called the Critical Region for the test. Similarly since the area outside mean ±2.58 (s.d.) is only 1%. 𝐻0 is rejected at 1% level of significance, if z numerically exceeds 258, i.e. the critical region is 𝑧 ≥ 2.58 at 1% level. Using the sampling distribution of an appropriate test statistic we are able to establish the maximum difference at a specified level between the observed and expected values that is consistent with null hypothesis 𝐻0 . The set of values of the test statistic corresponding to this difference which lead to the acceptance of 𝐻0 is called Region of acceptance. Conversely, the set of values of the statistic leading to the rejection of 𝐻0 is referred to as Region of Rejection or “Critical Region” of the test. The value of the statistic which lies at the boundary of the regions of acceptance and the rejection is called Critical value. When the null hypothesis is true, the probability of observed value of the test statistic falling in the critical region is often called the “Size of Critical Region”.
𝑆𝑖𝑧𝑒 𝑜𝑓 𝐶𝑟𝑖𝑡𝑖𝑐𝑎𝑙 𝑅𝑒𝑔𝑖𝑜𝑛 ≤ 𝐿𝑒𝑣𝑒𝑙 𝑜𝑓 𝑆𝑖𝑔𝑛𝑖𝑓𝑖𝑐𝑎𝑛𝑐𝑒
However, for a continuous population, the critical region is so determined that its size equals the Level of Significance (𝛼).
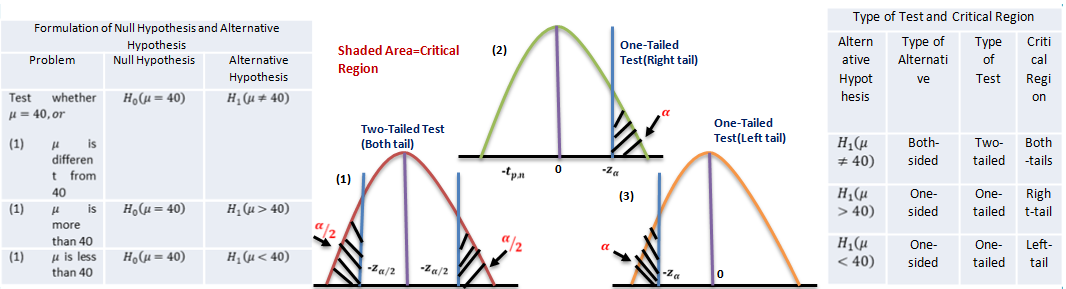
Two-Tailed And One-Tailed Tests
Our discussion above were centered around testing the significance of ‘difference’ between the observed and expected values, i.e. whether the observed value is significantly different from (i.e. either larger or smaller than) the expected value, as could arise due to fluctuations of random sampling. In the illustration, the null hypothesis is tested against “both-sided alternatives” 𝜇 > 40 𝑜𝑟 𝜇 < 40 , i.e.
𝐻0 𝜇 = 40 𝑎𝑔𝑎𝑖𝑛𝑠𝑡 𝐻1 𝜇 ≠ 40
Thus assuming 𝐻0 to be true, we would be looking for large differences on both sides of the expected value, i.e. in “both tails” of the distribution. Such tests are, therefore, called “Two-tailed tests”.
Sometimes we are interested in tests for large differences on one side only i.e., in one ‘one tail’ of the distribution. For example, whether a change in the production bricks with a ‘higher’ breaking strength, or whether a change in the production technique yields ‘lower’ percentage of defectives. These are known as “One-tailed tests”.
For testing the null hypothesis against “one-sided alternatives (right side)” 𝜇 > 40 , i.e.
𝐻0 𝜇 = 40 𝑎𝑔𝑎𝑖𝑛𝑠𝑡𝐻1 𝜇 > 40
The calculated value of the statistic z is compared with 1.645, since 5% of the area under the standard normal curve lies to the right of 1.645. if the observed value of z exceeds 1.645, the null hypothesis 𝐻0 is rejected at 5% level of significance. If a 1% level were used, we would replace 1.645 by 2.33. thus the critical regions for test at 5% and 1% levels are 𝑧 ≥ 1.645 and 𝑧 ≥ 2.33 respectively.
For testing the null hypothesis against “one-sided alternatives (left side)” 𝜇 < 40 i.e.
𝐻0 𝜇 = 40 𝑎𝑔𝑎𝑖𝑛𝑠𝑡𝐻1 𝜇 < 40
The value of z is compared with -1.645 for significance at 5% level, and with -2.33 for significance at 1% level. The critical regions are now 𝑧 ≤ −1.645 and 𝑧 ≤ −2.33 for 5% and 1% levels respectively. In fact, the sampling distributions of many of the commonly-used statistics can be approximated by normal distributions as the sample size increases, so that these rules are applicable in most cases when the sample size is ‘large’, say, more than 30. It is evident that the same null hypothesis may be tested against alternative hypothesis of different types depending on the nature of the problem. Correspondingly, the type of test and the critical region associated with each test will also be different.
Solving Testing Of Hypothesis Problem
Step 1 Set up the “Null Hypothesis” 𝐻0 and the “Alternative Hypothesis” 𝐻1 on the basis of the given problem. The null hypothesis usually specifies the values of some parameters involved in the population: 𝐻0 𝜃 = 𝜃0 . The alternative hypothesis may be any one of the following types: 𝐻1 ( ) 𝜃 ≠ 𝜃1 𝐻1 𝜃 > 𝜃0 , 𝐻1 𝜃 < 𝜃0 . The types of alternative hypothesis determines whether to use a two-tailed or one-tailed test (right or left tail).
Step 2
State the appropriate “test statistic” T and also its sampling distribution, when the null hypothesis is true. In large sample tests the statistic 𝑧 = (𝑇 − 𝜃0)Τ𝑆. 𝐸. , (T) which approximately follows Standard Normal Distribution, is often used. In small sample tests, the population is assumed to be Normal and various test statistics are used which follow Standard Normal, Chi-square, t for F distribution exactly.
Step 3 Select the “level of significance” 𝛼 of the test, if it is not specified in the given problem. This represents the maximum probability of committing a Type I error, i.e., of making a wrong decision by the test procedure when in fact the null hypothesis is true. Usually, a 5% or 1% level of significance is used (If nothing is mentioned, use 5% level).
Step 4
Find the “Critical region” of the test at the chosen level of significance. This represents the set of values of the test statistic which lead to rejection of the null hypothesis. The critical region always appears in one or both tails of the distribution, depending on weather the alternative hypothesis is one-sided or both-sided. The area in the tails must be equal to the level of significance 𝛼. For a one-tailed test, 𝛼 appears in one tail and for two-tailed test 𝛼/2 appears in each tail of the distribution. The critical region is
Where 𝑇𝛼 is the value of T such that the area to its tight is 𝛼.
Step 5
Compute the value of the test statistic T on the basis of sample data the null hypothesis. In large sample tests, if some parameters remain unknown they should be estimated from the sample. Step 6
If the computed value of test statistic T lies in the critical region, “reject 𝐻0”; otherwise “do not reject 𝐻0 ”. The decision regarding rejection or otherwise of 𝐻0 is made after a comparison of the computed value of T with critical value (i.e., boundary value of the appropriate critical region).
Step 7 Write the conclusion in plain non-technical language. If 𝐻0 is rejected, the interpretation is: “the data are not consistent with the assumption that the null hypothesis is true and hence 𝐻0 is not tenable”. If 𝐻0 is not rejected, “the data cannot provide any evidence against the null hypothesis and hence 𝐻0 may be accepted to the true”. The conclusion should preferably be given in the words stated in the problem.
Conclusion
Hypothesis is a statistical statement or a conjecture about the value of a parameter. The legal concept that one is innocent until proven guilty has an analogous use in the world of statistics. In devising a test, statisticians do not attempt to prove that a particular statement or hypothesis is true. Instead, they assume that the hypothesis is incorrect (like not guilty), and then work to find statistical evidence that would allow them to overturn that assumption. In statistics this process is referred to as hypothesis testing, and it is often used to test the relationship between two variables. A hypothesis makes a prediction about some relationship of interest. Then, based on actual data and a pre-selected level of statistical significance, that hypothesis is either accepted or rejected. There are some elements of hypothesis like null hypothesis, alternative hypothesis, type I & type II error, level of significance, critical region and power of test and some processes like one and two tail test to find the critical region of the graph as well as the error that help us reach the final conclusion.
A Null hypothesis is a hypothesis that says there is no statistical significance between the two variables in the hypothesis. There is no difference between certain characteristics of a population. It is denoted by the symbol 𝐻0. A statistical hypothesis which differs from the null hypothesis is called an Alternative Hypothesis, and is denoted by 𝐻1. The procedure of testing statistical hypothesis does not guarantee that all decisions are perfectly accurate. At times, the test may lead to erroneous conclusions. This is so, because the decision is taken on the basis of sample values, which are themselves fluctuating and depend purely on chance, this process called types of error. Hypothesis testing is very important part of statistical analysis. By the help of hypothesis testing many business problem can be solved accurately.
That was the fourth part of the series, that explained hypothesis testing and hopefully it clarified your notion of the same by discussing each crucial aspect of it. You can find more informative posts like this one on Data Science course topics. Just keep on following the Dexlab Analytics blog to stay informed.
A business organization has to deal with a massive amount of data streaming from myriad sources, and data warehousing refers to the process of collection and storage of that data that needs to be analyzed to glean valuable business insight. Data warehousing plays a crucial role in business intelligence. The concept originated in the 1980s, it basically involves data extraction from disparate sources which later gets processed and post formatting the data stays in the system ready to be utilized for taking important decisions.
Data warehouse basically performs the task of running an analysis on the stored data which could be both structured and unstructured even semi-structured, however, the data that is in the warehouse cannot be modified. Data warehousing basically helps companies gain insight regarding factors influencing business, and they could use the data insight to formulate new strategies, developing products and so on. This highly skilled task demands professionals who have a background in Data science using python training.
What are the different steps in data warehousing?
Data warehousing involves the following steps
Transactional data extraction: In this step, the data is extracted from multiple sources available and loaded into the system.
Data transformation: The transactional data extracted from different sources need to be transformed and it would need relating as well.
Building a dimensional model: A dimensional model comprising fact and dimension tables are built and the data gets loaded.
Getting a front-end reporting tool: The tool could be built or, purchased, a crucial decision that needs much deliberation.
Benefits of data warehousing
An edge over the competition
This is undeniably one benefit every business would be eager to reap from data warehousing. The data that is untapped could be the source of valuable information regarding risk factors, trends, customers and so many other factors that could impact the business. Data warehousing collates the data and arranges them in a contextual manner that is easy for a company to access and utilize to make informed decisions.
Enhanced data quality
Since data pooled from different sources could be structured or, unstructured and in different formats, working with such data inconsistency could be problematic and data warehousing takes care of the issue by transforming the data into a consistent format. The standardized data that easily conforms to the analytics platform can be of immense value.
Historical data analysis
A data warehouse basically stores a big amount of data and that includes historical data as well. Such data are basically old records of the company regarding sales, employee data, or, product-related information. Now the historical data belonging to different time periods need to be analyzed to predict upcoming trends.
Smarter business intelligence
Since businesses now rely on data-driven insight to devise strategies, they need access to data that is consistent, error-free, and high quality. However, data coming from numerous sources could be erroneous and irrelevant. But, data warehousing takes care of this issue by formatting the data to make it consistent and free from any error and could be analyzed to offer valuable insight that could help the management take decisions regarding sales, marketing, finance.
High ROI
Building a data warehouse requires significant investment but in the long term, the revenue that it generates can be significant. In fact, keen business intelligence now plays a crucial role in determining the success of an organization and with data warehousing the organizations can have access to data that is consistent and high quality thus enabling the company to derive actionable intel. When a company implements such insight in making smarter strategies, they do gain in the long run.
Data warehousing plays a significant role in collating and storing valuable data that fuels a company’s business decisions. However, given the specialized nature of the task, one must undergo Data Science training, to learn the nuances. The field of big data has plenty of opportunities for the right candidates.
Big data is certainly is getting a lot of hype and for good reasons. Different sectors ranging from business to healthcare are intent on harnessing the power of data to find solutions to their most imminent problems. Huge investments are being made to build models, but, there are some niggling issues that are not being resolved.
So what are the big challenges the data science industry is facing?
Managing big data
Thanks to the explosion of information now the amount of data being created every year is adding to the already overstocked pile, and, most of the data we are talking about here is unstructured data. So, handling such a massive amount of raw data that is not even in a particular database is a big challenge that could only be overcome by implementing advanced tools.
Lack of skilled personnel
One of the biggest challenges the data science industry has to deal with is the shortage of skilled professionals that are well equipped with Data Science training. The companies need somebody with specific training to manage and process the datasets and present them with the insight which they can channelize to develop business strategies. Sending employees to a Data analyst training institute can help companies address the issue and they could also consider making additional efforts for retaining employees by offering them a higher remuneration.
Communication gap
One of the challenges that stand in the way, is the lack of understanding on the part of the data scientists involved in a project. They are in charge of sorting, cleaning, and processing data, but before they take up the responsibility they need to understand what is the goal that they are working towards. When they are working for a business organization they need to know what the set business objective is, before they start looking for patterns and build models.
Data integration
When we are talking about big data, we mean data pouring from various sources. The myriad sources could range from emails, documents, social media, and whatnot. In order to process, all of this data need to be combined, which can be a mammoth task in itself. Despite there being data integration tools available, the problem still persists. Investment in developing smarter tools is the biggest requirement now.
Data security
Just the way integrating data coming from different sources is a big problem, likewise maintaining data security is another big challenge especially when interconnectivity among data sources exists. This poses a big risk and renders the data vulnerable to hacking. In the light of this problem, procuring permission for utilizing data from a source becomes a big issue. The solution lies in developing advanced machine learning algorithms to keep the hackers at bay.
Data validity
Gaining insight from data processing could only be possible when that data is free from any sort of error. However, sometimes data hailing from different sources could show disparity regardless of being about the same subject. Especially in healthcare, for example, patient data when coming from two different sources could often show dissimilarity. This poses a serious challenge and it could be considered an extension of the data integration issue. Advanced technology coupled with the right policy changes need to be in place to address this issue, otherwise, it would continue to be a roadblock.
The challenges are there, but, recognizing those is as essential as continuing research work to finding solutions. Institutes are investing money in developing data science tools that could smoothen the process by eliminating the hurdles. Accessing big data courses in delhi, is a good way to build a promising career in the field of data science, because despite there being challenges the field is full big opportunities.
The term big data refers to the massive amount of data being generated from various sources that need to be sorted, processed, and analyzed using advanced data science tools to derive valuable insight for different industries. Now, big data comprises structured, semi-structured, and mostly unstructured data. Processing this huge data takes skill and expertise and which only someone with Data Science training would be able to do.
The concept of big data is relatively new and it started emerging post the arrival of internet closely followed by the proliferation of advanced mobile devices, social media platforms, IoT devices, and all other myriad platforms that are the breeding grounds of user-generated data. Managing and storing this data which could be in text, audio, image formats is essential for not just businesses but, for other sectors as well. The information data holds can help in the decision-making process and enable people to understand the vital aspects of an issue better.
The characteristics of big data
Now, any data cannot be classified as big data, there are certain characteristics that define big data and getting in-depth knowledge regarding these characteristics can help you grasp the concept of big data better. The main characteristics of big data could be broken down into 5Vs.
What are the 5Vs of data?
The 5Vs of data basically refers to the core elements of big data, the presence of which acts as a differentiating factor. Although many argue in favor of the essential 3 VS, other pundits prefer dissecting data as per 5Vs. These 5Vs denote Volume, Velocity, Variety, Veracity, Value the five core factors but, not necessarily in that order. However, Volume would always be the element that lays the foundation of big data. Pursuing a Data Science course would further clarify your idea of big data.
Volume
This concept is easier to grasp as it refers to the enormous amount of data being generated and collected every day. This amount is referred to as volume, the size of data definitely plays a crucial role as storing this data is posing a serious challenge for the companies. Now the size of the data would vary from one industry to the other, the amount of data an e-commerce site generates would vary from the amount generated on a popular social media platform like Facebook. Now, only advanced technology could handle and process and not to mention deal with the cost and space management issue for storing such large volumes of data.
Velocity
Another crucial feature of big data is velocity which basically refers to the speed at which data is generated and processed, analyzed, and moved across platforms to deliver insight in real-time if possible. Especially, in a field like healthcare the speed matters, crucial trading decisions that could result in loss or profit, must also be taken in an instant. Only the application of advanced data science technology can collect data points in an instant and process those at a lightning speed to deliver results. Another point to be noted here is the fact that just like volume the velocity of data is also increasing.
Variety
The 3rd V refers to the variety, a significant aspect of big data that sheds light on the diversity of data and its sources. As we already know that the data now hails from multiple sources, including social media platforms, IoT devices, and whatnot. The problem does not stop there, the data is also diverse in terms of format such as videos, texts, images, audios and it is a combination of structured and unstructured data. In fact, almost 80%-90% of data is unstructured in nature. This poses a big problem for the data scientists as sorting this data into distinct categories for processing is a complicated task. However, with advanced data science technologies in place determining the relationship among data is a lot hassle-free process now.
Veracity
It is perhaps the most significant aspect of all other elements, no matter how large datasets you have and in what variety, if the data is messy and inaccurate then it is hardly going to be of any use. Data quality matters and dirty data could be a big problem especially because of the fact that data comes from multiple sources. So, you have apparently no control, the problems range from incomplete data to inconsistency of information. In such situations filtering the data to extract quality data for analysis purposes is essential. Pursuing Data science using python training can help gain more skill required for such specific tasks.
Value
The 5th V of big data refers to the value of the data we are talking about. You are investing money in collecting, storing, and processing the big data but if it does not generate any value at the end of the day then it is completely useless. Managing this massive amount of data requires a big investment in advanced infrastructure and additional resources, so, there needs to be ROI. The data teams involved in the process of collecting, sorting, and analyzing the data need to be sure of the quality of data they are handling before making any move.
The significance of big data in generating valuable insight is undeniable and soon it would be empowering every industry. Further research in this field would lead to the development of data science tools for handling big data issues in a more efficient manner. The career prospects in this field are also bright, training from a Data analyst training institute can help push one towards a rewarding career.
With the big data field experiencing an exponential growth, the need for skilled professionals to sort, analyze data is also growing. Not just businesses but other sectors too are realizing the significance of big data to leverage their growth.
In order to move forward with confidence, big data can help. With digitization the amount of data being generated is also increasing and to process such vast amount of data skilled professionals are required.
The field is surely opening up for the young generation who needs the right blend of skill and passion to land high-paying jobs in the field. Help is available in the form of training institutes which offer cutting edge courses like big data training in gurgaon.
So how much data we are talking about here?
The amount of data that is generated now thanks to IOT, stands at more than 2.5 quintillion bytes of data and this amount is being generated everyday as per the sixth edition of DOMO’s report. By this current year it was estimated that every person will create 1.7MB of data every second.
With IOT being primarily the reason behind this data proliferation, we are looking at a huge data avalanche heading our way comprising mostly unstructured data.
All of the data generated along with past stock are of importance now as crucial sectors like banking, healthcare, communication, manufacturing, finance are being reliant on data to extract valuable information for taking pivotal decisions.
A Data analyst training institute can be of immense value as they take up the responsibility of shaping data skills of the professionals needed by these sectors.
The expanding field of data requires data experts
Processing through mountains of unstructured data, cleaning it, preparing it for further processing and then analyzing it to find pattern takes skill which could be attained by pursuing Data science using python training.
As per survey findings, there is a huge gap in the demand and supply chain. The field might be expanding and organizations being eager to embrace the power of data, but, the dearth of professionals is posing a big problem which is why the companies in dire need of trained workforce are taking the salary graph higher to lure talent.
However, there are courses available such as business analyst training delhi, that are aimed at training up the new generation of geeks to handle the big data, thereby helping them carve out successful career avenues.
What are the trending jobs in this sector?
Data scientist
A data scientist basically works with a business organization to process raw data, cleaning, analyzing the data to detect patterns that could be of immense value for the organization concerned. A data scientist can play a big role in helping a company decide the next business strategy. They also create algorithms and build machine learning models. Data Science training can help you be prepared for such a high-profile position.
In the USA, a data scientist can earn upto $1,13,309, while in India it could be ₹500,000 per annum.
Data Engineer
A data engineer is a person who is well versed in programming and SQL, and works with stored data. He basically has to work with data systems and is charged with the responsibility of creating data infrastructure and maintaining it. A data engineer also works to build data pipelines to channelize valuable data to data analysts and scientists fast.
The salary range of a data engineer in the USA could be near $128,722 per annum and in India it could hover around ₹839,565.
Data Analyst
The data analyst is basically the guy who runs the show as he is in charge of manipulating huge data sets. He is involved with the tasks of gathering data and he also creates databases, analytics models, extracts information and analyzes that to aid in decision making. Not just that but he also needs to present the insight into a format that everybody can grasp.
If you aim to grab this job then you could expect a pay around $62,453 in United States. In India that number might be around ₹419135 on average.
BI Analyst
A BI Analyst has to put his entire focus on analyzing data in order to identify the potential areas for a company to prosper along with the main obstacles standing in their way to success. They have to update the database on a continuous basis along with monitoring the performance of rivals in the field concerned.
Along with possessing sharp business acumen, he must be proficient in data handling. He basically offers data-driven insight while donning the role of a consultant.
A background in computer science or, business administration, statistics, finance could work in your favor if only you can couple that with big data courses in delhi.
A skilled BI Analyst could expect a pay around $94906 in the USA, and in India they might get upto ₹577745.
There are more lucrative job opportunities and exciting job roles awaiting the next generation of professionals that can help them build a highly successful career. Regardless of which background they hail from undergoing a Data Science course can push them in the right direction.
Data mining refers to processing mountainous amount of data that pile up, to detect patterns and offer useful insight to businesses to strategize better. The data in question could be both structured and unstructured datasets containing valuable information and which if and when processed using the right technique could lead towards solutions.
Enrolling in a Data analyst training institute, can help the professionals involved in this field hone their skills. Now that we have learned what data mining is, let’s have a look at the data mining techniques employed for refining data.
Data cleaning
Since the data we are talking about is mostly unstructured data it could be erroneous, corrupt data. So, before the data processing can even begin it is essential to rectify or, eliminate such data from the data sets and thus preparing the ground for the next phases of operations. Data cleaning enhances data quality and ensures faster processing of data to generate insight. Data Science training is essential to be familiar with the process of data mining.
Classification analysis
Classification analysis is a complicated data mining technique which basically is about data segmentation. To be more precise it is decided which category an observation might belong to. While working with various data different attributes of the data are analyzed and the class or, segments they belong to are identified, then using algorithms further information is extracted.
Regression analysis
Regression analysis basically refers to the method of deciding the correlation between variables. Using this method how one variable influences the other could be decided. It basically allows the data analyst to decide which variable is of importance and which could be left out. Regression analysis basically helps to predict.
Anomaly detection
Anomaly detection is the technique that detects data points, observations in a dataset, that deviate from an expected or, normal pattern or behavior. This anomaly could point to some fault or, could lead towards the discovery of an exception that might offer new potential. In fields like health monitoring, or security this could be invaluable.
Clustering
This data mining technique is somewhat similar to classification analysis, but, different in the way that here data objects are grouped together in a cluster. Now objects belonging to one particular cluster will share some common thread while they would be completely different from objects in other clusters. In this technique visual presentation of data is important, for profiling customers this technique comes in handy.
Association
This data mining technique is employed to find some hidden relationhip patterns among variables, mostly dependent variables belonging to a dataset. The recurring relationships of variables are taken into account in this process. This comes in handy in predicting customer behavior, such as when they shop what items are they likely to purchase together could be predicted.
Tracking patterns
This technique is especially useful while sorting out data for the businesses. In this process while working with big datasets, certain trends or, patterns are recognized and these patterns are then monitored to draw a conclusion. This pattern tracking technique could also aid in identifying some sort of anomaly in the dataset that might otherwise go undetected.
Big data is accumulating every day and the more efficiently the datasets get processed and sorted, the better would be the chances of businesses and other sectors be accurate in predicting trends and be prepared for it. The field of data science is full of opportunities now, learning Data science using python training could help the younger generation make it big in this field.
In today’s data-driven world, it is hard to ignore the growing need for data science, as businesses are busy applying data to devise smarter marketing strategies and urging their employees to upgrade themselves. Data Science training is gaining ground as lucrative career opportunities are beckoning the younger generation.
So, it is not surprising that a crucial sector like healthcare would apply data science to upgrade their service. Health care is among one of the many sectors that have acknowledged the benefits of data science and adopted it.
The Healthcare industry is vast and it comprises many disciplines and branches that intercross generating a ton of unstructured data which if processed and analyzed could lead to revolutionary changes in the field.
Here is taking a look at how the industry can benefit by adopting data science techniques
Diagnostic error prevention
No matter what health issues one might have, accurate diagnosing is the first step that helps a physician prescribe treatment procedure. However, there have been multiple cases where a diagnostic error has led to even death. With the implementation of data science technology, it is now possible to increase the accuracy of the procedures as the algorithm sifts data to detect patterns and come up with accurate results.
Medical imaging procedures such as MRI, X-Ray can now detect even tiniest deformity in the organs which were erstwhile impossible, due to the application of deep learning technology. Advanced models such as MapReduce is also being put to use to enhance the accuracy level.
Bioinformatics
Genomics is an interesting field of research where researchers analyze your DNA to understand how it affects your health. As they go through genetic sequences to gain an insight into the correlation, they try to find how certain drugs might work on a specific health issue.
The purpose is to provide a more personalized treatment program. In order to process through the highly valuable genome data, data science tools such as SQL are being applied. This field has a vast scope of improvement and with more advanced research work being conducted in the field of Bioinformatics, we can hope for better results. Researchers who have studied Data science using python training, would prove to be invaluable assets for this specific field.
Health monitoring with wearables
Healthcare is an ongoing process, if you fall ill, you get yourself diagnosed and then get treatment for the health condition you have. The story in most cases does not end there, with the number of patients with chronic health problems increasing, it is evident that constant monitoring of your health condition is required to prevent your health condition from taking a worse hit. Data science comes into the picture with wearables and other forms of tracking devices that are programmed to keep your health condition in check. Be it your temperature or, heartbeat the sensors keep tracking even minute changes, the data is analyzed to enable the doctors take preventive measures, the GPS-enabled tracker by Propeller, is an excellent case in point.
Faster approval of new drugs
The application of data science is not restricted to only predicting, preventing, and monitoring patient health conditions. In fact, it has reached out to assist in the drug development process as well. Earlier it would take almost a decade for a drug to be accessible in the market thanks to the numerous testing, trial, and approval procedures.
But, now it is possible to shorten the duration thanks to advanced data science algorithms that enable the researchers to simulate the way a drug might react in the body. Different models are being used by the researchers to process clinical trial data, so, that they can work with different variables. Data Science course enables a professional to carry out research work in such a highly specialized field.
In the context of Covid-19
With the entire world crippling under the unprecedented impact of COVID-19, it is needless to point out that the significance of data science in the healthcare sector is only going to increase. If you have been monitoring the social media platforms then you must have come across the #FlattenTheCurve.
The enormity of the situation and erroneous data collection both have caused issues, but, that hasn’t deterred the data scientists. Once, the dust settles they will have a mountainous task ahead of them to process through a massive amount of data the pandemic will have left behind, to offer insight that might help us take preventive measures in the future.
The field of data science has no doubt made considerable progress and so has the field of modern healthcare. Further research and collaboration would enable future data scientists to provide a better solution to bolster the healthcare sector.
Data Science is the new rage and if you are looking to make a career, you might as well choose to become a data scientist. Data Scientists work with large sets of data to draw valuable insights that can be worked upon. Businesses rely on data scientists to sieve through tonnes of data and mine out crucial information that becomes the bedrock of business decisions in the future.
With the growth of AI, machine learning and predictive analytics, data science has come to be one of the favoured career choices in the world today. It is imperative for a data scientist to know one of more programming languages from any of those available – Java, R, Python, Scala or MATLAB.
However, Data Scientists prefer Python to other programming languages because of a number of reasons. Here we delve into some of them.
Popular
Python is one of the most popular programming languages used today. This dynamic language is easy to pick up and learn and is the best option for beginners. Secondly, it interfaces with complex high performance algorithms written in Fortran or C. It is also used for web development, data mining and scientific computing, among others.
Preferred for Data Science
Python solves most of the daily tasks a data scientist is expected to perform. “For data scientists who need to incorporate statistical code into production databases or integrate data with web-based applications, Python is often the ideal choice. It is also ideal for implementing algorithms, which is something that data scientists need to do often,” says a report.
Packages
Python has a number of very useful packages tailored for specific functions, including pandas, NumPy and SciPy. Data Scientists working on machine learning tasks find scikit-learn useful and Matplotlib is a perfect solution for graphical representation and data visualization in data science projects.
Easy to learn
It is easy to grasp and that is why not only beginners but busy professionals also choose to learn Python for their data science needs. Compared to R, this programming language shows a sharper learning curve for most people choosing to learn it.
Scalability
Unlike other programming languages, Python is highly scalable and perceptive to change. It is also faster than languages like MATLAB. It facilitates scale and gives data scientists multiple ways to approach a problem. This is one of the reasons why Youtube migrated to Python.
Libraries
Python offers access to a wide range of data science and data analysis libraries. These include pandas, NumPy, SciPy, StatsModels, and scikit-learn. And Python will keep building on these and adding to these. These libraries have made many hitherto unsolvable problems seem easy to crack for data scientists.
Python Community
Python has a very robust community and many data science professionals are willing to create new data science libraries for Python users. The Python community is tight-knit one and very active when it comes to finding a solution. Programmers can connect with community members over the Internet and Codementor or Stack Overflow.
So, that is why data scientists tend to opt for Python over other programming languages. This article was brought to you by DexLab Analytics. DexLab Analytics is premiere data science training institute in Gurgaon.