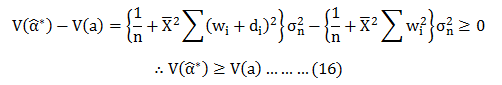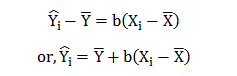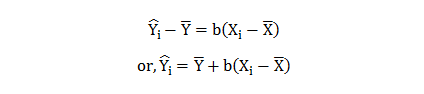Small or big, most of the organizations seek aspiring data scientists. The reason being this new breed of data experts helps them stay ahead of the curve and churns out industry-relevant insights.
It hardly matters if you are a fresher or a college dropout, with the right skill-set and basic understanding of nuanced concepts of machine learning, you are good to go and pursue a lucrative career in data science with a decent pay scale.
However, whenever a company hires a new data scientist, the former expects that the candidate had some prior work experience or at least have been a part in a few data science-related projects. Projects are the gateway to hone your skills and expertise in any realm. In such projects, a budding data scientist not only learns how to develop a successful machine learning model but also solves an array of critical tasks, which needs to be fulfilled single-handedly. The tasks include preparing a problem sheet, crafting a suitable solution to the problem, collect and clean data and finally evaluate the quality of the model.
Below, we have charted down top 5 full-stack data science projects that will boost your efforts of preparing an interesting resume.

Face Detection
In the last decade, face detection gained prominence and popularity across myriad industry domains. From smartphones to digitally unlocking your house door, this robust technology is being used at homes, offices and everywhere.
Project: Real-Time Face Recognition
Tools: OpenCV, Python
Algorithms: Convolution Neural Network and other facial detection algorithms
Spam Detection
Today, the internet plays a crucial role in our lives. Nevertheless, sharing information across the internet is no mean feat. Communication systems, such as emails, at times, contain spam, which results in decreased employee productivity and needs to be avoided.
Project: Spam Classification
Tools: Python, Matplotlib
Algorithm: NLTK
Sentiment Analysis
If you are from the Natural Language Processing and Machine Learning domain, sentiment analysis must have been the hot-trend topic. All kinds of organizations use this technology to understand customer behaviors and frame strategies. It works by combining NLP and suave machine learning technologies.
Project: Twitter Sentiment Analysis
Tools: NLTK, Python
Algorithms: Sentiment Analysis
Time Series Prediction
Making predictions regarding the future is known as extrapolation in the classical handling of time series data. Modern researchers, however, prefer to call it time series forecasting. It is a revolutionary phenomenon of taking models perfect on historical data and using them for future prediction of observations.
Project: Web Traffic Time Series Forecasting
Tools: GCP
Algorithms: Long short-term memory (LSTM), Recurrent Neural Networks (RNN) and ARIMA-based techniques

Recommender Systems
Bigwigs, such as Netflix, Pandora, Amazon and LinkedIn rely on recommender systems. The latter helps users find out new and relevant content and items. In simple terms, recommender systems are algorithms that suggest users meaningful items based on his preferences and requirements.
Project: Youtube Video Recommendation System
Tools: Python, sklearn
Algorithms: Deep Neural Networks, classification algorithms
If you are a budding data scientist, follow DexLab Analytics. We are a premier data science training platform specialized in a wide array of in-demand skill training courses. For more information on data science courses in Gurgaon, feel free to drop by our website today.
The blog has been sourced from ― www.analyticsindiamag.com/5-simple-full-stack-data-science-projects-to-put-on-your-resume
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.