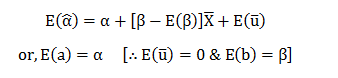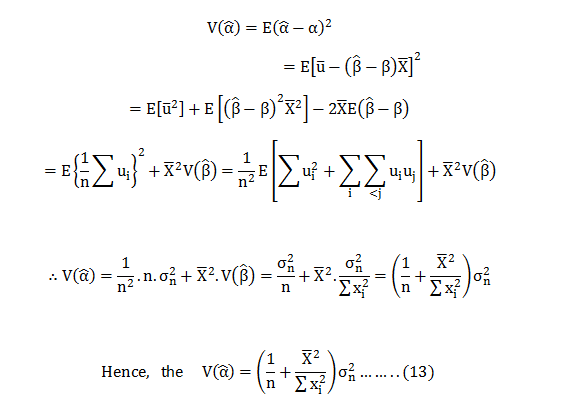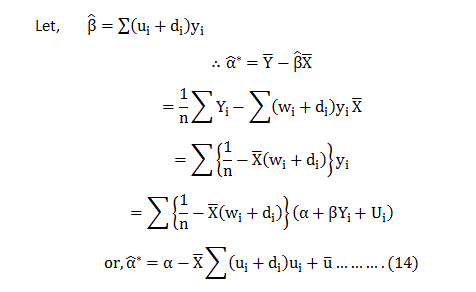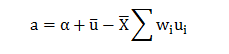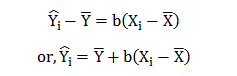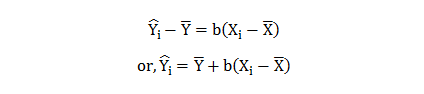Business leaders across platforms are hungrily eyeing data-driven decision making for its ability to transform businesses. But what needs to be taken into account is the opinion of data scientists in the core company teams for they are the experts in the field and whatever they have to say regarding data driven decisions should be the final word in these matters.
“The ideal scenario is all parties in complete alignment. This can be envisioned as a perfect rectangle, with business leaders’ expectations at the top, fully supported by a foundation of data science capabilities — for example, when data science and AI can achieve management’s goal of reducing customer retention costs by automating identification and outreach to at-risk customers,”says a report.
The much sought after rectangle, however, is rarely achieved. “A more workable shape is the rhombus, depicting the push-and-pull of expectations and deliverables.”
Using the power of your company’s data.
Business leaders must have patience with developments on the part of data scientists for what they expect is usually not in sync with the deliverables on the ground.
“Over the last few years, an automaker, for example, dove into data science on leadership’s blind faith that analytics could revolutionize the driver experience. After much trial and error, the results fell far short of adding anything meaningful to what drivers found valuable behind the wheel of a car.”
Appreciate Small Improvements
Also, what must be appreciated are small improvements made impactful. For instance, “slight increases in profitability per customer or conversion rates” are things that should be taken into account despite the fact that they might be modest gains in comparison to what business leaders had invested in analytics. “Applied over a large population of customers, however, those small improvements can yield big results. Moreover, these improvements can lead to gains elsewhere, such as eliminating ineffective business initiatives.”
Healthy Competition
However, it is advisable for business leaders to constantly push their data scientists to strive for more deliverables and improve their tally with a framework of healthy competition in place. In fact, big companies form data science centers of excellence, “while also creating a healthy competitive atmosphere that encourages data scientists to push each other to find the best tools, strategies, and techniques for solving problems and implementing solutions.”

Here are three ways to inspire data scientists
- Both sides must work together –Take the example of a data science team with expertise in building models to improve customers’ shopping experiences. “Business leaders might assume that a natural next step is to use AI to enhance all customer service needs.”However, AI and machine learning cannot answer the ‘why’ or ‘how’ of the data insights. Human beings have to delve into those aspects by studying the AI output. And on the other hand, data scientists also must understand why business leaders expect so much from them and how to achieve a middle path with regard to expectations and deliverables.
- Gain from past successes and achievements – “There is value in small data projects to build capabilities and understanding and to help foster a data-driven culture.”The best policy for firms to follow is to initially keep modest expectations. After executing and implementing the analytics projects, they should conduct a brutally honest anatomy of the successes and failures, and then build business expectations at the same time as analytics investment.
- Let data scientists spell out the delivery of analytics results – “Communication around what is reasonable and deliverable given current capabilities must come from the data scientists — not the frontline marketing person in an agency or the business unit leader.” Before signing any contract or deal with a client, it is advisable to allow the client to have a discussion with the data scientists so that there is no conflict of ideas between what the data science team spells out and what the marketing team has in mind. For this, data scientists will have to work on their soft skills and improve their ability to “speak business” regarding specific projects.
.