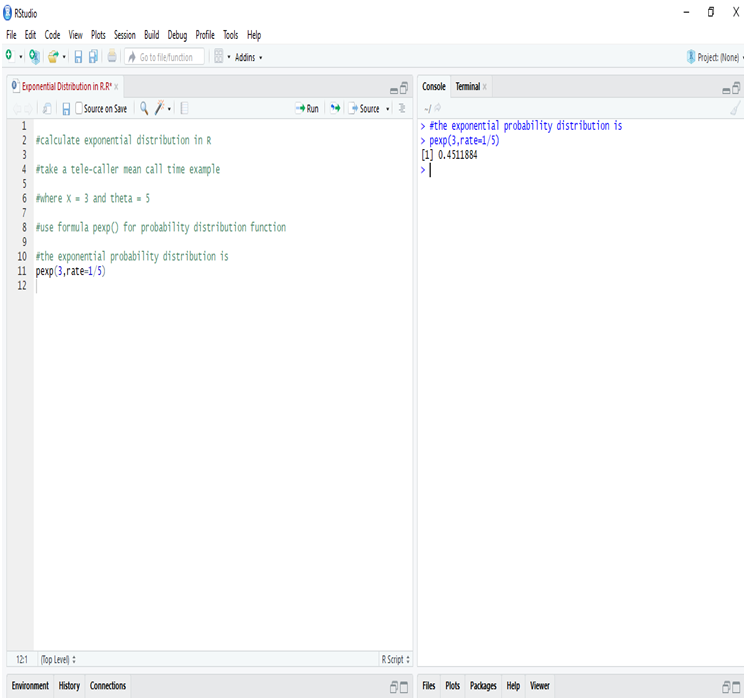
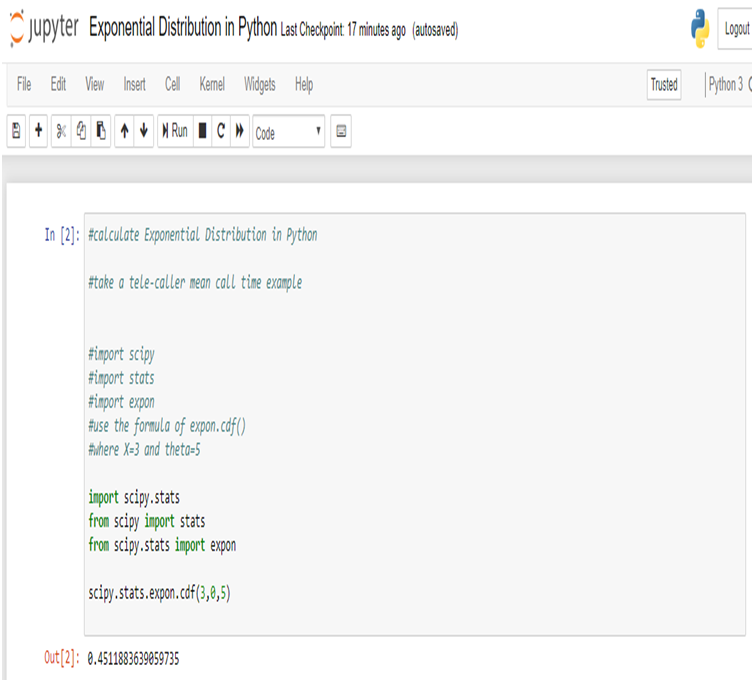
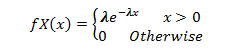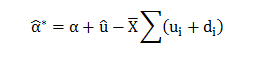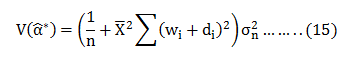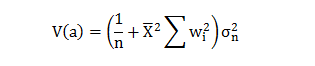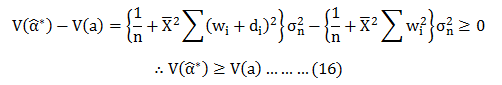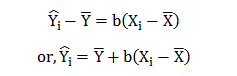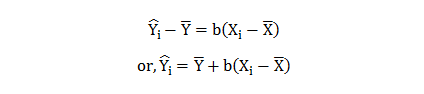Data Science has undergone a tremendous change since the 1990s when the term was first coined. With data as its pivotal element, we need to ask valid questions like why we need data and what we can do with the data in hand.
The Data Scientist is supposed to ask these questions to determine how data can be useful in today’s world of change and flux. The steps taken to determine the outcome of processes applied to data is known as Data Science project lifecycle. These steps are enumerated here.
Business Understanding
Business Understanding is a key player in the success of any data science project. Despite the prevalence of technology in today’s scenario it can safely be said that the “success of any project depends on the quality of questions asked of the dataset.”One has to properly understand the business model he is working under to be able to effectively work on the obtained data.
Data Collection
Data is the raison detre of data science. It is the pivot on which data science functions. Data can be collected from numerous sources – logs from webservers, data from online repositories, data from databases, social media data, data in excel sheet format. Data is everywhere. If the right questions are asked of data in the first step of a project life cycle, then data collection will follow naturally.
Data Preparation
The available Data set might not be in the desired format and suitable enough to perform analysis upon readily. So the data set will have to be cleaned or scrubbed so to say before it can be analyzed. It will have to be structured in a format that can be analyzed scientifically. This process is also known as Data cleaning or data wrangling. As the case might be, data can be obtained from various sources but it will need to be combined so it can be analyzed.
For this, data structuring is required. Also, there might me some elements missing in the data set in which case model building becomes a problem. There are various methods to conduct missing value and duplicate value treatment.
“Exploratory Data Analysis (EDA) plays an important role at this stage as summarization of clean data helps in identifying the structure, outliers, anomalies and patterns in the data.
These insights could help in building the model.”
Data Modelling
This stage is the most, we can say, magical of all. But ensure you have thoroughly gone through the previous processes before you begin building your model. “Feature selection is one of the first things that you would like to do in this stage. Not all features might be essential for making the predictions. What needs to be done here is to reduce the dimensionality of the dataset. It should be done such that features contributing to the prediction results should be selected.”
“Based on the business problem models could be selected. It is essential to identify what is the task, is it a classification problem, regression or prediction problem, time series forecasting or a clustering problem.” Once problem type is sorted out the model can be implemented.
“After the modelling process, model performance measurement is required. For this precision, recall, F1-score for classification problem could be used. For regression problem R2, MAPE (Moving Average Percentage Error) or RMSE (Root Mean Square Error) could be used.”The model should be a robust one and not an overfitted model that will not be accurate.

Interpreting Data
This is the last and most important step of any Data Science project. Execution of this step should be as good and robust as to produce what a layman can understand in terms of the outcome of the project.“The predictive power of the model lies in its ability to generalise.”
.