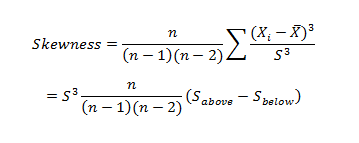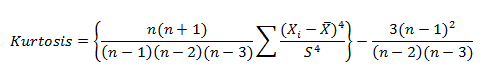A time series is a sequence of numerical data in which each item is associated with a particular instant in time. Many sets of data appear as time series: a monthly sequence of the quantity of goods shipped from a factory, a weekly series of the number of road accidents, daily rainfall amounts, hourly observations made on the yield of a chemical process, and so on. Examples of time series abound in such fields as economics, business, engineering, the natural sciences (especially geophysics and meteorology), and the social sciences.
Univariate time series analysis- When we have a single sequence of data observed over time then it is called univariate time series analysis.
Multivariate time series analysis – When we have several sets of data for the same sequence of time periods to observe then it is called multivariate time series analysis.
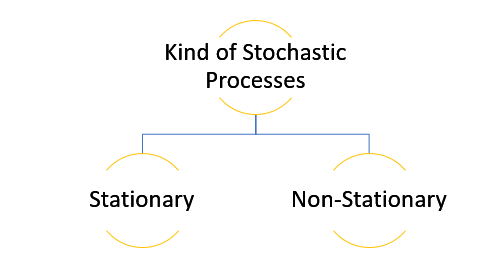
The data used in time series analysis is a random variable (Yt) where t is denoted as time and such a collection of random variables ordered in time is called random or stochastic process.
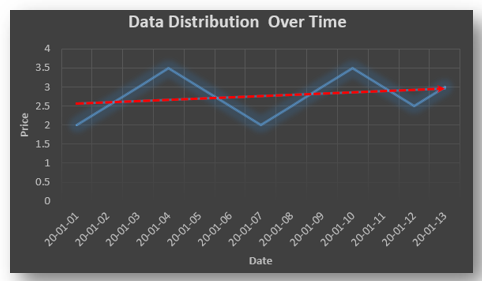
Stationary: A time series is said to be stationary when all the moments of its probability distribution i.e. mean, variance , covariance etc. are invariant over time. It becomes quite easy forecast data in this kind of situation as the hidden patterns are recognizable which make predictions easy.
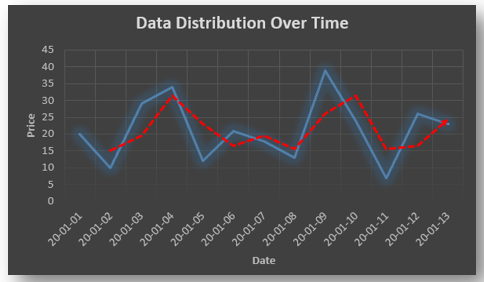
Non-stationary: A non-stationary time series will have a time varying mean or time varying variance or both, which makes it impossible to generalize the time series over other time periods.
Non stationary processes can further be explained with the help of a term called Random walk models. This term or theory usually is used in stock market which assumes that stock prices are independent of each other over time. Now there are two types of random walks: Random walk with drift : When the observation that is to be predicted at a time ‘t’ is equal to last period’s value plus a constant or a drift (α) and the residual term (ε). It can be written as Yt= α + Yt-1 + εt The equation shows that Yt drifts upwards or downwards depending upon α being positive or negative and the mean and the variance also increases over time. Random walk without drift: The random walk without a drift model observes that the values to be predicted at time ‘t’ is equal to last past period’s value plus a random shock. Yt= Yt-1 + εt Consider that the effect in one unit shock then the process started at some time 0 with a value of Y0 When t=1 Y1= Y0 + ε1 When t=2 Y2= Y1+ ε2= Y0 + ε1+ ε2 In general, Yt= Y0+∑ εt In this case as t increases the variance increases indefinitely whereas the mean value of Y is equal to its initial or starting value. Therefore the random walk model without drift is a non-stationary process.
So, with that we come to the end of the discussion on the Time Series. Hopefully it helped you understand time Series, for more information you can also watch the video tutorial attached down this blog. DexLab Analytics offers machine learning courses in delhi. To keep on learning more, follow DexLab Analytics blog.
Computer vision is an advanced branch of AI that revolves around the concept of object recognition and smart classification of objects in images or, videos. This is indeed a revolutionary innovation that aims to simulate the way human vision is trained to identify and classify objects. Studying deep learning for computer vision course can help gain specialized knowledge in this field. The growing application of computer vision across industries is now opening up multiple career avenues.
The application of computer vision is changing different industries:
Healthcare
In healthcare computer vision technology is adding efficiency to medical imaging procedures such as MRI. Detecting even the smallest of oddity is now possible which ensures accurate diagnosis. In departments like radiology, cardiology, computer vision techniques are gradually being adopted. Not just that, during surgical procedures too computer vision can offer cutting edge solutions. A case in point here would be Gauss Surgical’s blood monitoring system that analyzes the amount of blood loss during surgery.
Automotive
The self-driving cars are no longer a sci-fi theme, but, a hardcore reality, computer vision technology analyzes the road conditions, detects humans crossing the road, objects as well as road signs and lane changes. There are advanced systems that aim to prevent accidents that run on the same technology and could also signal if the driver behind the wheel is not awake, thus saving lives in real-time.
Manufacturing
The manufacturing industry is reaping benefits of computer vision technology in so many ways. Using computer vision the equipment condition can be monitored and measures could be taken accordingly to prevent untimely breakdown. Maintaining production quality also gets easier with computer vision application as even the smallest defect in a product or, on the packaging could be detected which might get missed by human eyes. Not just that but, even the labels could be efficiently screened to detect printing errors.
Agriculture
In the field of agriculture, computer vision technology is helping maintain quality and adding efficiency. Using drones to monitor the crops is getting easier, not just that but computer vision technology is helping farmers separate crops as per quality and decide which crop could be stored for a long time. Livestock monitoring is another job that could be efficiently handled using computer vision technology. However, one significant application is perhaps using computer vision to detect crops that are infected and need pesticide.
Military applications
Computer vision can add an edge to modern warfare, its adoption in the military surely indicate that. Autonomous vehicles powered with computer vision techniques can save so many lives, especially when deployed during battles. Not just that, but detecting landmines, or, enemy, both high-risk yet extremely important operations can be handled successfully by adopting computer vision techniques. Image sensors could deliver the intelligence the military think-tank needs to take timely decisions.
Surveillance
Surveillance is a highly crucial area that could immensely benefit from computer vision applications. In shops preventing crimes like shoplifting could become easier, as the cameras could easily detect any kind of suspicious behavior and activity going on in the shop premises. Another factor to consider here would be the application of facial recognition to identify miscreants from videos.
Computer vision technology is changing the way we look at our world, and with further research, there would be smarter products on the market that can truly transform our lives by allowing us to be more efficient. For someone aspiring to make a career in this promising domain should undergo computer vision course python training.
The latest research work in the field of image recognition led to the development of a new activation function for visual recognition tasks, namely Funnel activation(FReLU). In this research ReLU and PReLU are extended to a 2D activation by adding a negligible overhead of spatial condition. Experiments on ImageNet, COCO detection, and semantic segmentation tasks are conducted to measure the performance of FReLU.
CNNs have shown advanced performances in many visual recognition tasks, such as image classification, object detection, and semantic segmentation. In a CNN framework, basically two major kind of layers play crucial roles, the convolution layer and the non-linear activation layer. Both the convolution layers and activation layers perform distinct functions, however, in both layers there are challenges regarding capturing the spatial dependency. However, despite advancements achieved by complex convolutions, improving the performance of visual tasks is still challenging which results in Rectified Linear Unit (ReLU) being the most widely used function till date.
The research focused on two distinct queries
Could regular convolutions achieve similar accuracy, to grasp the challenging complex images? 2. Could we design an activation specifically for visual tasks?
1. Effectiveness and generalization performance
In a bid to find answers to these questions, researchers identified spatially insensitiveness in activations to be the main impending factor that prevent visual tasks from improving further.
To address this issue they proposed to find a new visual activation task that could be effective in removing this obstacle and be a better alternative to previous activation approaches.
How other activations work
Taking a look at other activations such as Scalar activations, Contextual conditional activations helps in understanding the context better.
Scalar activations basically are concerned with single input and output which could be represented in form of y = f(x). ReLU or, the Rectified Linear Unit is a widely used activation that is used for various tasks and could be represented as y = max(x, 0).
Contextual conditional activations work on the basis of many-to-one function. In this process neurons that are conditioned on contextual information are activated.
Spatial dependency modeling
In order to accumulate the various ranges of spatial dependences, some approaches utilize various shapes of convolution kernels which leads to lesser efficiency. In other methods like STN, spatial transformations are adaptively used for refining short-range dependencies for the dense vision tasks.
FReLU differs from all other methods in the sense that it performs better without involving complex convolutions. FReLU addresses the issues and solves with a higher level of efficiency.
Receptive field: How FReLU differs from other methods regarding the Receptive field
The size as well as the region of the receptive field play a crucial role in vision recognition tasks. The pixel contribution can be unequal. In order to implement the adaptive receptive field and for a better performance, many methods resort to complex convolutions. FReLU differs from such methods in the way that it achieves the same goal with regular convolutions in a more simple yet highly efficient manner.
Funnel Activation: how funnel activation works
FReLU being conceptually simple is designed for visual tasks. The research further delves into reviewing the ReLU activation and PReLU which is an advanced variant of ReLU, moving on to the key elements of FReLU the funnel condition and the pixel-wise modeling capacity, both of which are not found in ReLU or, in any of its variants.
2. Funnel activation
Funnel condition
Here the same max(·) is adopted as the simple non-linear function, when it comes to the condition part it gets extended to be a 2D condition which is dependent on the spatial context for individual pixel. For the implementation of the spatial condition, Parametric Pooling Window is used for creating dependency.
Pixel-wise modeling capacity
Due to the funnel condition the network is capable of generating spatial conditions in the non-linear activations for each pixel. This differs from usual methods where spatial dependency is created in the convolution layer and non-linear transformations are conducted separately. This model achieves a pixel-wise modeling capacity thereby extraction of spatial structure of objects could be addressed naturally.
Experiments
Evaluation of the activation is tested via experiments on ImageNet 2012 classification dataset[9,37].The evaluation is done in stages starting with different sizes of ResNet. Comparisons with scalar activations is done on ResNets with varying depths, followed by Comparison on light-weight CNNs. An object detection experiment is done to evaluate the generalization performance on various tasks on COCO dataset containing 80 object categories. Further comparison is also done on semantic segmentation task in CityScape dataset. Difference of the images could be perceived through the CityScape images.
4. Visualization of semantic segmentation
Funnel activation: ablation studies
The scope of the visual activation is tested further via ablation studies where each component of the activation namely 1) funnel condition, and 2)max(·) non-linearity are individually examined. The three parts of the investigation are as follows Ablation on the spatial condition, Ablation on the non-linearity, Ablation on the window size
Compatibility with Existing Methods
Before the new activation could be adopted into the convolutional networks, layers and stages need to be decided, the compatibility with other existing approaches such as SENet also was tested. The process took place in stages as follows
Compatibility with different convolution layers
Compatibility with different stages
Compatibility with SENet
Conclusion: Post all the investigations done to test out the compatibility of FReLU on different levels, it could be stated that this funnel activation is simple yet highly effective and specifically developed for visual tasks. Its pixel-wise modeling capacity is able to grasp even complex layouts easily. But further research work could be done to expand its scope as it definitely has huge potential.
To get in-depth knowledge regarding the various stages of the research work on Funnel Activation for Visual Recognition, check https://arxiv.org/abs/2007.11824.
Computer Vision is one of the most revolutionary and advanced technologies that deep learning has birthed. It is the computer’s ability to classify and recognize objects in pictures and even videos like the human eye does. There are five main techniques of computer vision that we ought to know about for their amazing technological prowess and ability to ‘see’ and perceive surroundings like we do. Let us see what they are.
Image Classification
The main concern around image classification is categorization of images based on viewpoint variation, image deformation and occlusion, illumination and background clutter. Measuring the accuracy of the description of an image becomes a difficult task because of these factors. Researchers have come up with a novel way to solve the problem.
They use a data driven approach to classify the image. Instead of classifying what each image looks like in code, they feed the computer system with many image classes and then develop algorithms that look at these classes and “learn” about the visual appearance of each class. The most popular system used for image classification is Convolutional Neural Networks (CNNs).
Object Detection
Object detection is, simply put, defining objects within images by outputting bounding boxes and labels or tags for individual objects. This differs from image classification in that it is applied to several objects all at once rather than identifying just one dominant object in an image. Now applying CNNs to this technique will be computationally expensive.
So the technique used for object detection is region-based CNNs of R-CNNs. In this technique, first an image is scanned for objects using an algorithm that generates hundreds of region proposals. Then a CNN is run on each region proposal and only then is each object in each region proposal classified. It is like surveying and labelling the items in a warehouse of a store.
Object Tracking
Object tracking refers to the process of tracking or following a specific object like a car or a person in a given scene in videos. This technique is important for autonomous driving systems in self-driving cars. Object detection can be divided into two main categories – generative method and discriminative method.
The first method uses the generative model to describe the evident characteristics of objects. The second method is used to distinguish between object and background and foreground.
Semantic Segmentation
Crucial to computer vision is the process of segmentation wherein whole images are divided or segmented into pixelgroups that are subsequently labeled and classified.
The science tries to understand the role of each pixel in the image. So, for instance, besides recognizing and detecting a tree in an image, its boundaries are depicted as well. CNNs are best used for this technique.
Instance Segmentation
This method builds on semantic segmentation in that instead of classifying just one single dominant object in an image, it labels multiple images with different colours.
When we see complicated images with multiple overlapping objects and different backgrounds, we apply instance segmentation to it. This is done to generate pixel studies of each object, their boundaries and backdrops.
Conclusion
Besides these techniques to study and analyse and interpret images or a series of images, there are many more complex techniques that we have not delved into in this blog. However, for more on computer vision, you can peruse the DexLab Analytics website. DexLab Analytics is a premiere Deep Learning training institute In Delhi.
In the first series of this article we have seen what is computer vision and a brief review of its applications. You can read the first part of this article here. We have also seen the contribution of deep learning in computer vision. Especially we focused on Image Classification and deep learning architecture which is used in Image Classification. In this series we will focus on other applications including Image Localization, Object Detection and Image Segmentation. We will also walk through the required deep learning architecture used for above applications.
Image classification with Localization
Similar to classification, localization finds the location of a single object inside the image. Localization can be used for lots of useful real-life problems. For example, smart cropping (knowing where to crop images based on where the object is located), or even regular object extraction for further processing using different techniques. It can be combined with classification for not only locating the object but categorizing it into one of many possible categories.
Iterating over the problem of localization plus classification we end up with the need for detecting and classifying multiple objects at the same time. Object detection is the problem of finding and classifying a variable number of objects on an image. The important difference is the “variable” part. In contrast with problems like classification, the output of object detection is variable in length, since the number of objects detected may change from image to image.
The PASCAL Visual Object Classes datasets, or PASCAL VOC for short (e.g. VOC 2012), is a common dataset for object detection.
Deep learning for Image Localization and Object Detection
There is nothing hardcore about the architectures which we are going to discuss. What we are going to discuss are some clever ideas to make the system intolerant to the number of outputs and to reduce its computation cost. So, we do not know the exact number of objects in our image and we want to classify all of them and draw a bounding box around them. That means that the number of coordinates that the model should output is not constant. If the image has 2 objects, we need 8 coordinates. If it has 4 objects, we want 16. So how we build such a model?
One key idea to traditional computer vision is regions proposal. We generate a set of windows that are likely to contain an object using classic CV algorithms, like edge and shape detection and we apply only these windows (or regions of interests) to the CNN. To learn more about how regions are proposed, we introduce a new architecture called RCNN.
R-CNN
Given an image with multiple objects, we generate some regions of interests using a proposal method (in RCNN’s case this method is called selective search) and wrap the regions into a fixed size. We forward each region to Convolutional Neural Network (such as AlexNet), which will use an SVM to make a classification decision for each one and predicts a regression for each bounding box. This prediction comes as a correction of the region proposed, which may be in the right position but not at the exact size and orientation.
Although the model produces good results, it suffers from a major issue. It is quite slow and computationally expensive. Imagine that in an average case, we produce 2000 regions, which we need to store in disk, and we forward each one of them into the CNN for multiple passes until it is trained. To fix some of these problems, an improvement of the model comes in play called ‘Fast-RCNN’
Fast RCNN
The idea is straightforward. Instead of passing all regions into the convolutional layer one by one, we pass the entire image once and produce a feature map. Then we take the region proposals as before (using some external method) and sort of project them onto the feature map. Now we have the regions in the feature map instead of the original image and we can forward them in some fully connected layers to output the classification decision and the bounding box correction.
Note that the projection of regions proposal is implemented using a special layer (ROI layer), which is essentially a type of max-pooling with a pool size dependent on the input, so that the output always has the same size.
Faster RCNN
And we can take this a step further. Using the produced feature maps from the convolutional layer, we infer regions proposal using a Region Proposal network rather than relying on an external system. Once we have those proposals, the remaining procedure is the same as Fast-RCNN (forward to ROI layer, classify using SVM and predict the bounding box). The tricky part is how to train the whole model as we have multiple tasks that need to be addressed:
The region proposal network should decide for each region if it contains an object or not.
It needs to produce the bounding box coordinates.
The entire model should classify the objects to categories.
And again predict the bounding box offsets.
As the name suggests, Faster RCNN turns out to be much faster than the previous models and is the one preferred in most real-world applications.
Localization and object detection is a super active and interesting area of research due to the high emergency of real world applications that require excellent performance in computer vision tasks (self-driving cars, robotics). Companies and universities come up with new ideas on how to improve the accuracy on regular basis.
There is another class of models for localization and object detection, called single shot detectors, which have become very popular in the last few years because they are even faster and require less computational cost in general. Sure, they are less accurate, but they are ideal for embedded systems and similar power-hungry applications.
Object segmentation
Going one step further from object detection we would want to not only find objects inside an image, but find a pixel by pixel mask of each of the detected objects. We refer to this problem as instance or object segmentation.
Semantic Segmentation is the process of assigning a label to every pixel in the image. This is in stark contrast to classification, where a single label is assigned to the entire picture. Semantic segmentation treats multiple objects of the same class as a single entity. On the other hand, instance segmentation treats multiple objects of the same class as distinct individual objects (or instances). Typically, instance segmentation is harder than semantic segmentation.
In order to perform semantic segmentation, a higher level understanding of the image is required. The algorithm should figure out the objects present and also the pixels which correspond to the object. Semantic segmentation is one of the essential tasks for complete scene understanding. This can be used in analysis of medical images and satellite images. Again, the VOC 2012 and MS COCO datasets can be used for object segmentation.
Deep Learning for Image Segmentation
Modern image segmentation techniques are powered by deep learning technology. Here are several deep learning architectures used for segmentation.
Convolutional Neural Networks (CNNs)
Image segmentation with CNN involves feeding segments of an image as input to a convolutional neural network, which labels the pixels. The CNN cannot process the whole image at once. It scans the image, looking at a small “filter” of several pixels each time until it has mapped the entire image. To learn more see our in-depth guide about Convolutional Neural Networks.
Fully Convolutional Networks (FCNs)
Traditional CNNs have fully-connected layers, which can’t manage different input sizes. FCNs use convolutional layers to process varying input sizes and can work faster. The final output layer has a large receptive field and corresponds to the height and width of the image, while the number of channels corresponds to the number of classes. The convolutional layers classify every pixel to determine the context of the image, including the location of objects.
DeepLab
One main motivation for DeepLab is to perform image segmentation while helping control signal decimation—reducing the number of samples and the amount of data that the network must process. Another motivation is to enable multi-scale contextual feature learning—aggregating features from images at different scales. DeepLab uses an ImageNet pre-trained residual neural network (ResNet) for feature extraction. DeepLab uses atrous (dilated) convolutions instead of regular convolutions. The varying dilation rates of each convolution enable the ResNet block to capture multi-scale contextual information. DeepLab comprises three components:
Atrous convolutions—with a factor that expands or contracts the convolutional filter’s field of view.
ResNet—a deep convolutional network (DCNN) from Microsoft. It provides a framework that enables training thousands of layers while maintaining performance. The powerful representational ability of ResNet boosts computer vision applications like object detection and face recognition.
Atrous spatial pyramid pooling (ASPP)—provides multi-scale information. It uses a set of atrous convolutions with varying dilation rates to capture long-range context. ASPP also uses global average pooling (GAP) to incorporate image-level features and add global context information.
SegNet neural network
An architecture based on deep encoders and decoders is also known as semantic pixel-wise segmentation. It involves encoding the input image into low dimensions and then recovering it with orientation invariance capabilities in the decoder. This generates a segmented image at the decoder end.
Conclusion
In this post we have discussed some applications of computer vision including Image Localization, Object Detection and Image Segmentation. We then discussed required deep learning architectures which are used for the above applications.
Computer vision is the field of computer science that focuses on replicating parts of the complexity of the human vision system and enabling computers to identify and process objects in images and videos in the same way that humans do. With computer vision, our computer can extract, analyze and understand useful information from an individual image or a sequence of images. Computer vision is a field of artificial intelligence that works on enabling computers to see, identify and process images in the same way that human vision does, and then provide the appropriate output.
Initially computer vision only worked in limited capacity but due to advance innovations in deep learning and neural networks, the field has been able to take great leaps in recent years and has been able to surpass humans in some tasks related to detecting and labeling objects.
The Contribution of Deep Learning in Computer Vision
While there are still significant obstacles in the path of human-quality computer vision, Deep Learning systems have made significant progress in dealing with some of the relevant sub-tasks. The reason for this success is partly based on the additional responsibility assigned to deep learning systems.
It is reasonable to say that the biggest difference with deep learning systems is that they no longer need to be programmed to specifically look for features. Rather than searching for specific features by way of a carefully programmed algorithm, the neural networks inside deep learning systems are trained. For example, if cars in an image keep being misclassified as motorcycles then you don’t fine-tune parameters or re-write the algorithm. Instead, you continue training until the system gets it right.
With the increased computational power offered by modern-day deep learning systems, there is steady and noticeable progress towards the point where a computer will be able to recognize and react to everything that it sees.
Application of Computer Vision
The field of Computer Vision is too expansive to cover in depth. The techniques of computer vision can help a computer to extract, analyze, and understand useful information from a single or a sequence of images. There are many advanced techniques like style transfer, colorization, action recognition, 3D objects, human pose estimation, and much more but in this article we will only focus on the commonly used techniques of computer vision. These techniques are: –
Image Classification
Image Classification with Localization
Object Segmentation
Object Detection
So in this article we will go through all the above techniques of computer vision and we will also see how deep learning is used for the various techniques of computer vision in detail. To avoid confusion we will distribute this article in a series of multiple blogs. In first blog we will see the first technique of computer vision which is Image Classification and we will also explore that how deep learning is used in Image Classification.
Image Classification
Image classification is the process of predicting a specific class, or label, for something that is defined by a set of data points. Image classification is a subset of the classification problem, where an entire image is assigned a label. Perhaps a picture will be classified as a daytime or nighttime shot. Or, in a similar way, images of cars and motorcycles will be automatically placed into their own groups.
There are countless categories, or classes, in which a specific image can be classified. Consider a manual process where images are compared and similar ones are grouped according to like-characteristics, but without necessarily knowing in advance what you are looking for. Obviously, this is an onerous task. To make it even more so, assume that the set of images numbers in the hundreds of thousands. It becomes readily apparent that an automatic system is needed in order to do this quickly and efficiently.
There are many image classification tasks that involve photographs of objects. Two popular examples include the CIFAR-10 and CIFAR-100 datasets that have photographs to be classified into 10 and 100 classes respectively.
Deep learning for Image Classification
The deep learning architecture for image classification generally includes convolutional layers, making it a convolutional neural network (CNN). A typical use case for CNNs is where you feed the network images and the network classifies the data. CNNs tend to start with an input “scanner” which isn’t intended to parse all the training data at once. For example, to input an image of 100 x 100 pixels, you wouldn’t want a layer with 10,000 nodes.
Rather, you create a scanning input layer of say 10 x 10 which you feed the first 10 x 10 pixels of the image. Once you passed that input, you feed it the next 10 x 10 pixels by moving the scanner one pixel to the right. This technique is known as sliding windows.
Following Layers are used to build Convolutional Neural Networks:
INPUT [32x32x3] will hold the raw pixel values of the image, in this case an image of width 32, height 32, and with three color channels R,G,B.
CONV layer will compute the output of neurons that are connected to local regions in the input, each computing a dot product between their weights and a small region they are connected to in the input volume. This may result in volume such as [32x32x12] if we decided to use 12 filters.
RELU layer will apply an element wise activation function, such as the max(0,x)max(0,x)thresholding at zero. This leaves the size of the volume unchanged ([32x32x12]).
POOL layer will perform a downsampling operation along the spatial dimensions (width, height), resulting in volume such as [16x16x12].
FC (i.e. fully-connected) layer will compute the class scores, resulting in volume of size [1x1x10], where each of the 10 numbers correspond to a class score, such as among the 10 categories of CIFAR-10. As with ordinary Neural Networks and as the name implies, each neuron in this layer will be connected to all the numbers in the previous volume.
Output of the Model History
In this way, ConvNets transform the original image layer by layer from the original pixel values to the final class scores. Note that some layers contain parameters and other don’t. In particular, the CONV/FC layers perform transformations that are a function of not only the activations in the input volume, but also of the parameters (the weights and biases of the neurons). On the other hand, the RELU/POOL layers will implement a fixed function. The parameters in the CONV/FC layers will be trained with gradient descent so that the class scores that the ConvNet computes are consistent with the labels in the training set for each image.
Conclusion
The above content focuses on image classification only and the architecture of deep learning used for it. But there is more to computer vision than just classification task. The detection, segmentation and localization of classified objects are equally important. We will see these in next blog.
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now. To learn more about Data Analyst with R Course – Enrol Now. To learn more about Big Data Course – Enrol Now.
To learn more about Machine Learning Using Python and Spark – Enrol Now. To learn more about Data Analyst with SAS Course – Enrol Now. To learn more about Data Analyst with Apache Spark Course – Enrol Now. To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.
The major improvements that Artificial Neural Network is bringing about in favour of deep learning for computer vision with Pythonare ground-breaking. Machine vision, in general, is hugely benefitted with the inclusion of the computer vision course Python, spurred by the all-new technology of Neural Networks. This is by and large a huge advancement in the field of computer science and gives much of an insight into what the future holds for us.
However, along with an array of experiments that are performed day in day out with Neural Network Machine Learning Python, numerous other fields are also likely to be revamped in much the same way. Predicting the weather, studying animals and other critical studies of cosmology are also believed to be easing soon holding the hands of the Artificial Neural Network technology.
Some Well-known Feats of the Artificial Neural Network
Artificial Neural networks (ANNs) are used in studying the patterns, relationships from the collected data just like humans. Going by the name, ANNs are modelled on the neural networks found in our brains, which are used to infuse the machines with the ability to learn by them. Besides, ANNs have been hugely successful in bringing about the concept of self-driving cars, boosting medical technology and numerous other fields. But, here we lay down some other fields which are soaking in the Artificial Neural Network extensively.
Meteorology
The accurate prediction of hailstorms and providing relevant alerts to the specific areas are expected to boost shortly. With the inclusion of Convolutional neural networks, (CNNs) the study of meteorology is deemed to achieve new heights. Besides, this improved technology would also be capable of identifying the size of the hails during this storm.
Tracking Bird Migration
We are all aware of the phenomenon of migration for the birds. But with the changing age, the routes of the birds are also different from what they used to be. However, if you need to track the migration of the birds, you can opt for the exclusive Neural Networks in Python course.
Interpreting the Dark Matter
Dark matter has been a topic which remains largely unexplored till date. Nothing beyond the name and the fact that it binds the universe together is brought to light. However, with the marked progress of the premium institutes like the Neural Networks Training in Delhi, the dark matter will no longer be a mystery.
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now. To learn more about Data Analyst with R Course – Enrol Now. To learn more about Big Data Course – Enrol Now.
To learn more about Machine Learning Using Python and Spark – Enrol Now. To learn more about Data Analyst with SAS Course – Enrol Now. To learn more about Data Analyst with Apache Spark Course – Enrol Now. To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.
This is a blog which shall widen your approach on the Statistical Application using R & Python. You perhaps already have been calculatingGeometric Mean using R & Pythonand are already aware of theApplication of Harmonic Mean using R & Python. However, if you are eager to further your knowledge about Skewness & Kurtosis and interested to know of their application using R and Python, then this is the right place.
Skewness:
Skewness is a metric which tells us about the location of my dataset. That is, if you want to know where most of the values are concentrated on an ascending scale.
Skewness is of two kinds: Positive skew and Negative skew. A positively skewed dataset will have most of the values concentrated at the beginning of the scale. Eg: If a woman is asked to rate 100 tinder profiles based on the looks on a scale of 1 – 10, 1 being the ugliest and 10 being the most handsome. Then the resulting ratings will be positively skewed. This is to say that women are harsh critiques of looks.
Now, consider another example: Say if the wealth of the 1% richest people were to be plotted on a scale of say $0 – $200 billion. Then, most of the values will be concentrated at the end of the scale. This will be an example of a negatively skewed dataset.
In essence, skewness is the third central moment about mean and gives us a feel for the location of the data set values. It is recommended to go throughSTATISTICAL APPLICATION IN R & PYTHON: CHAPTER 1 – MEASURE OF CENTRAL TENDENCY to have an understanding of the Central Tendency and its measures. Having no skewness will mean the data set is fairly symmetrical and has a bell shaped curve.
Where n is the sample size, Xi is the ith X value, X is the average and S is the sample standard deviation. Note the exponent in the summation. It is “3”.
Kurtosis:
Kurtosis is a statistical measure that’s used to describe, or Skewness, of observed data around the mean, sometimes referred to as the volatility to volatility. Kurtosis is used generally in the statistical field to describe trends in charts. Kurtosis can be present in a chart with fat tails and a low, even distribution, as well as be present in a chart with skinny tails and a distribution concentrated toward the mean.
Kurtosis for a normal distribution is 3. Most software packages use the formula:
The types of kurtosis are:-
Application:
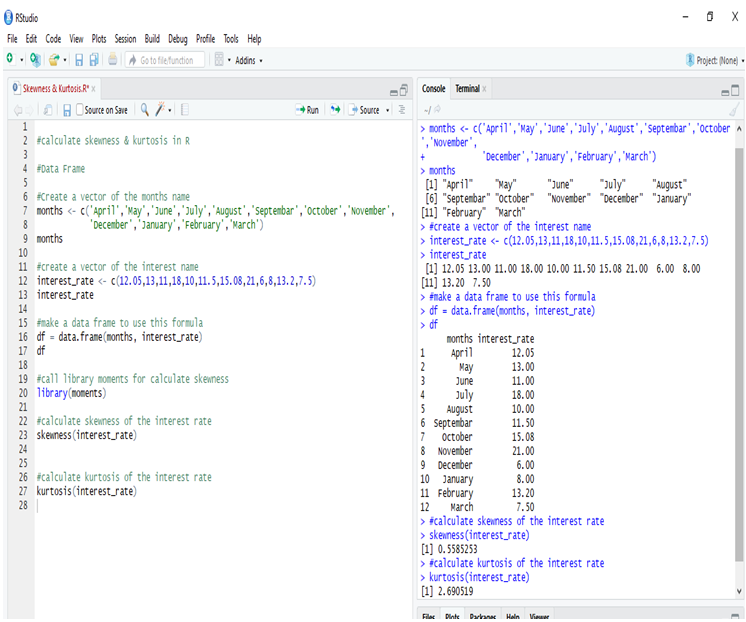
A person tries to analyze last 12months interest rate of the investment firm to understand the risk factor for the future investment.
Calculating the Skewness & Kurtosis of interest rate in R, we get the positive skewed value, which is near to 0. The skewness of the interest rate is 0.5585253.
The kurtosis of the interest rate is 2.690519
Kurtosis is less than 3, so this is Platykurtic distribution.
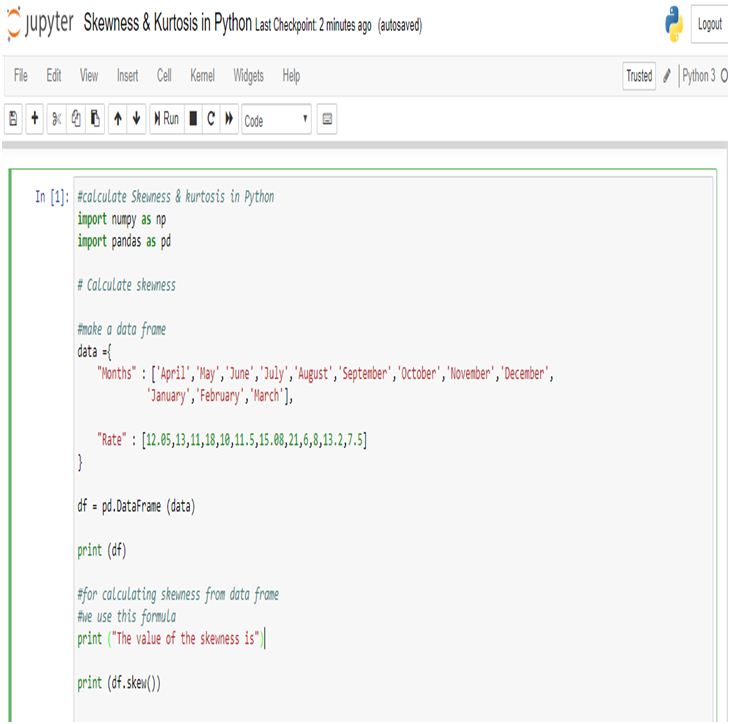
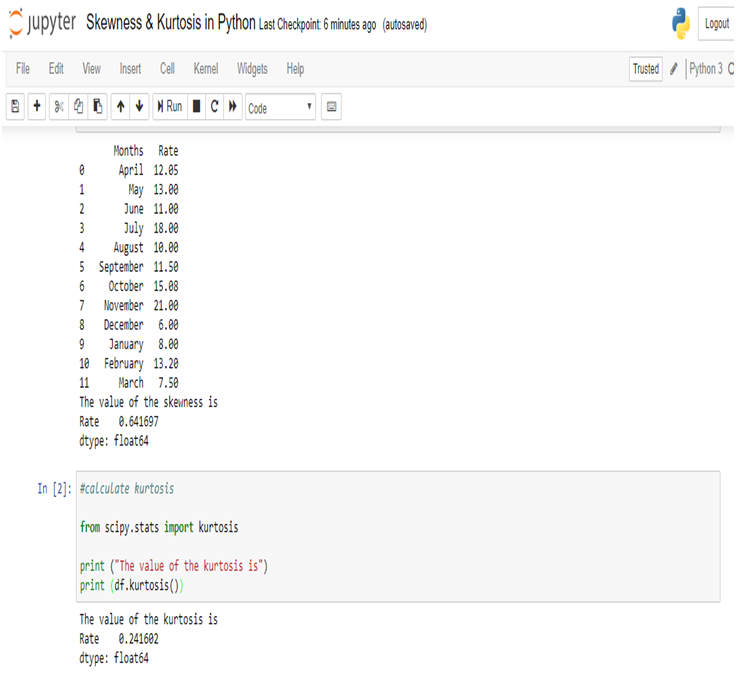
Calculate Skewness & Kurtosis in Python:
Calculating the Skewness & Kurtosis of interest rate in Python, we get the positive skewed value and near from 0. The skewness of the interest rate is 0.641697.
The kurtosis of the interest rate is 0.241602.
Kurtosis is less than 3, so this is Platykurtic distribution.
Conclusion:
Firstly, according to the output of the data the value is positively skewed(R & Python), positive skewness indicates a distribution with an asymmetric tail extending toward more positive values.
And the kurtosis is less than 3 (R & Python), it is a platykurtic distribution. Positive kurtosis indicates a relatively peaked distribution. And the distribution is light tails.
Secondly, the value of the skewness and kurtosis are different in R and Python, but the actual effects are more or less the same. The results are different because skewness and kurtosis are calculated with different formulae or method for the measurement like Bowley’s measure, Pearson’s(First, Second) measures, Fisher’s measure & Moment’s measure. And different software (ex. R, Python, SAS, Excel etc) using different processes to calculate skewness & kurtosis brings the same ultimate result. The numerical values change only when the numbers are also changed. So, we sometimes get different results.
To learn more about Data Analyst with Advanced excel course – Enrol Now. To learn more about Data Analyst with R Course – Enrol Now. To learn more about Big Data Course – Enrol Now.
To learn more about Machine Learning Using Python and Spark – Enrol Now. To learn more about Data Analyst with SAS Course – Enrol Now. To learn more about Data Analyst with Apache Spark Course – Enrol Now. To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.